NVIDIA ドライバ、NVIDIA CUDA ツールキット 11.8、NVIDIA cuDNN 8 のインストール(Ubuntu 上)
【要約】 本記事では、Ubuntu環境において、NVIDIA GPUを活用した開発環境を構築するために不可欠なNVIDIAドライバ、CUDA Toolkit 11.8、およびcuDNN 8をインストールする手順を解説する。対象読者は、AI、プログラミング、データベース等を学ぶ大学生や技術者である。具体的には、ドライバの準備(nouveau無効化、既存ドライバ削除、新規インストール)、公式リポジトリを用いたCUDA Toolkit 11.8およびcuDNN 8のインストール、環境変数設定、そして基本的な動作確認までを網羅する。本手順は、NVIDIA製GPUを搭載したUbuntuシステムを対象とする。
【目次】
NVIDIA CUDA Toolkitは、NVIDIA社が提供するGPUコンピューティングのための統合開発環境であり、GPUを用いた高速な演算処理を実現する。ディープラーニングをはじめとする多くの分野で活用されている。NVIDIA cuDNN(CUDA Deep Neural Network library)は、CUDA上で動作するディープラーニング向けのライブラリであり、畳み込みニューラルネットワークなどの計算を高速化する。
【関連情報】
■サイト内のUbuntu関連ページ
■参考Webページ
- TensorFlow GPU サポート: https://www.tensorflow.org/install/gpu
1. 事前準備
1.1 Ubuntu のシステム更新
インストール作業前にシステムを最新の状態に保つことで、依存関係の問題や予期せぬエラーを防ぐことができる。端末で以下のコマンドを実行し、システムを更新後、再起動する。
# パッケージリストの情報を更新
sudo apt update
sudo apt -yV upgrade
sudo /sbin/shutdown -r now
2. 必要なソフトウェアについて
2.1 GPU(Graphics Processing Unit)
GPUは、グラフィックス処理に特化したプロセッサであるが、その高い並列処理能力から、3Dグラフィックス、動画編集、仮想通貨マイニング、科学計算、ディープラーニングなど幅広い分野で活用されている。
2.2 NVIDIAドライバ
NVIDIAドライバは、NVIDIA社製GPUをUbuntuシステム上で認識させ、その性能を最大限に引き出すために必要なソフトウェアである。
- 公式サイト: https://www.nvidia.co.jp/Download/index.aspx?lang=jp(ダウンロード時にOSとGPUモデルを選択)
- インストール手順(本記事内): セクション4で詳述 [セクション4へ移動]
2.3 NVIDIA CUDA Toolkit
NVIDIA CUDA Toolkitは、NVIDIA GPU上で動作するアプリケーションを開発・実行するための統合開発環境である。コンパイラ、ライブラリ、開発ツールなどが含まれる。
- 公式サイト(アーカイブ): https://developer.nvidia.com/cuda-toolkit-archive
- 公式ドキュメント(Linux): https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html
- インストール手順(本記事内): セクション5で詳述 [セクション5へ移動]
【サイト内の関連ページ】
- Windows での NVIDIA ドライバ、NVIDIA CUDA ツールキット 11.8、NVIDIA cuDNN v8.9.7 のインストールと動作確認: 別ページ »で説明
- Ubuntu での NVIDIA ドライバ、NVIDIA CUDA ツールキット 11.8、NVIDIA cuDNN 8 のインストール: 別ページ »で説明(本ページ)
【関連する外部ページ】
- NVIDIA CUDA ツールキットのインストールに関する、NVIDIA CUDA クイックスタートガイドの公式ページ: https://docs.nvidia.com/cuda/cuda-quick-start-guide/index.html
2.4 NVIDIA cuDNN(CUDA Deep Neural Network library)
NVIDIA cuDNNは、CUDA Toolkit上で動作する、ディープニューラルネットワーク向けのGPUアクセラレーションライブラリである。畳み込み、プーリング、正規化、活性化関数などの標準的なルーチンを高性能に実装している。
- 公式サイト(要登録): https://developer.nvidia.com/cudnn
- インストール手順(本記事内): セクション6で詳述 [セクション6へ移動]
【NVIDIA cuDNN 利用の注意点】
- CUDA Toolkitとのバージョン互換性: cuDNNは特定のCUDA Toolkitバージョンに依存する。利用するフレームワーク(TensorFlow、PyTorch等)が要求するバージョンを確認し、適合する組み合わせをインストールする必要がある
- NVIDIA Developer Program: cuDNNのダウンロードには、NVIDIA Developer Programへの無料メンバー登録が必要である
- NVIDIA Developer Program: https://developer.nvidia.com/developer-program
3. インストール前の確認事項と注意点
- バージョン互換性の確認: TensorFlowやPyTorchなどのフレームワークを利用する場合、フレームワークが要求するNVIDIAドライバ、CUDA Toolkit、cuDNNのバージョンには厳密な互換性要件がある。必ず、利用するフレームワークの公式ドキュメントを確認し、互換性のあるバージョンをインストールすること(関連情報: 別ページ »で詳述)
- CUDA Toolkit アーカイブ: https://developer.nvidia.com/cuda-toolkit-archive
- cuDNN ダウンロードページ(バージョン確認可): https://developer.nvidia.com/cudnn
- cuDNNの環境変数: cuDNNのインストール後、必要に応じて環境変数
CUDNN_PATHの設定が必要になる場合がある(通常、aptでインストールした場合は自動的にパスが通ることが多い) - バージョン選択に関する注意: 本記事ではCUDA 11.8とcuDNN 8を扱うが、これらは執筆時点より前のバージョンである。利用するフレームワークが対応していれば、より新しい安定版のCUDA/cuDNNを検討することも推奨される。常に最新の互換性情報を確認すること
- NVIDIA GPUの搭載: 以降の手順は、NVIDIA製のGPUがシステムに搭載されていることを前提とする
4. NVIDIAドライバのインストール
(このセクションはNVIDIA製GPUが搭載されている場合にのみ実行する)
4.1 NVIDIAグラフィックスカードの確認
システムにNVIDIA製GPUが認識されているか確認する。
lspci | grep -i nvidia | grep VGA
(表示が空の場合、NVIDIA製GPUが搭載されていないか、認識されていない可能性がある)

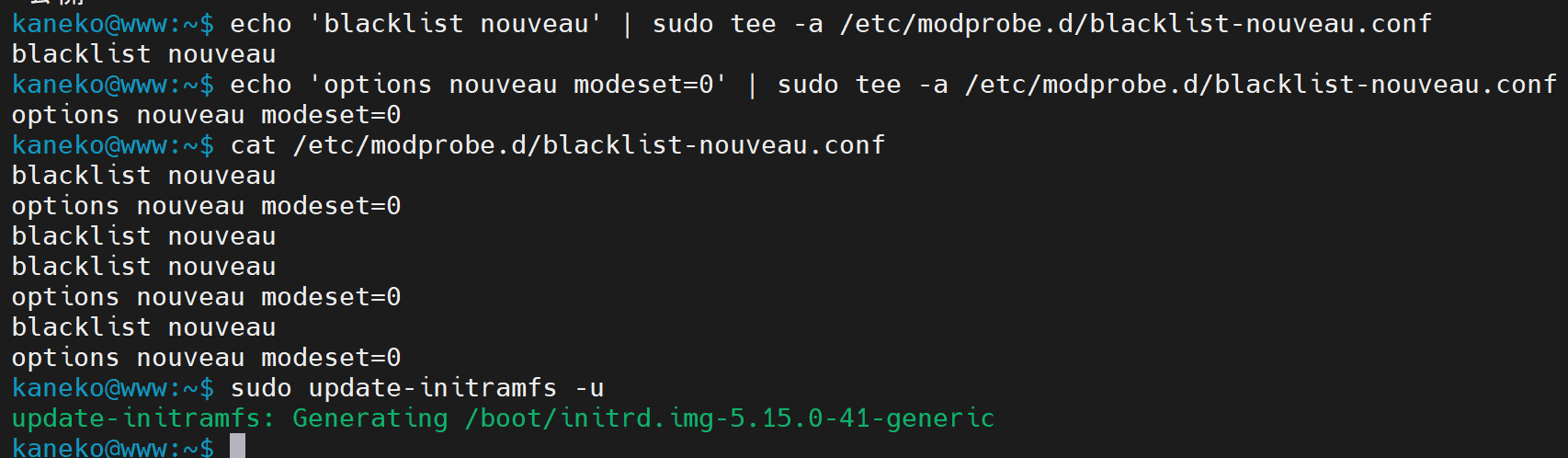
4.2 nouveauドライバの無効化
オープンソースのnouveauドライバが有効になっていると、NVIDIA公式ドライバと競合する場合があるため無効化する。
echo 'blacklist nouveau' | sudo tee /etc/modprobe.d/blacklist-nouveau.conf
echo 'options nouveau modeset=0' | sudo tee -a /etc/modprobe.d/blacklist-nouveau.conf
cat /etc/modprobe.d/blacklist-nouveau.conf # 設定内容を確認
sudo update-initramfs -u # initramfsを更新
4.3 既存のNVIDIA関連パッケージのアンインストール
古いドライバやCUDA Toolkitがインストールされている場合、競合を避けるためにアンインストールする。
# インストールされているCUDA関連パッケージを確認(任意)
dpkg -l | grep cuda
dpkg -l | grep nvidia
# 既存のNVIDIA関連パッケージを削除
sudo apt --purge remove -y '*nvidia*'
sudo apt --purge remove -y '*cuda*'
sudo apt --purge remove -y '*cudnn*'
# 不要になった依存関係を自動削除
sudo apt autoremove -y
(注意) *nvidia* のようなワイルドカード指定は意図しないパッケージを削除する可能性もあるため、実行前に dpkg -l | grep nvidia などで対象を確認することを推奨する。より安全な方法は、ubuntu-drivers devices で表示されるパッケージ名を指定して削除することである。
4.4 カーネルヘッダーと開発パッケージのインストール
ドライバのビルドに必要なカーネルヘッダー等をインストールする。
# パッケージリストの情報を更新
sudo apt update
sudo apt -y install linux-headers-$(uname -r) build-essential dkms
4.5 NVIDIAドライバのインストール
Ubuntuが推奨するドライバを自動でインストールする。
# システムを最新化(念のため)
sudo apt -y update
sudo apt -y upgrade
# sudo apt dist-upgrade # 通常はupgradeで十分なことが多い
# インストール可能なドライバと推奨ドライバを確認
ubuntu-drivers devices
# 推奨ドライバを自動インストール
sudo ubuntu-drivers autoinstall
# initramfsを更新
sudo update-initramfs -u
4.6 Ubuntuシステムの再起動
ドライバの変更を反映させるためにシステムを再起動する。
sudo /sbin/shutdown -r now # または sudo reboot

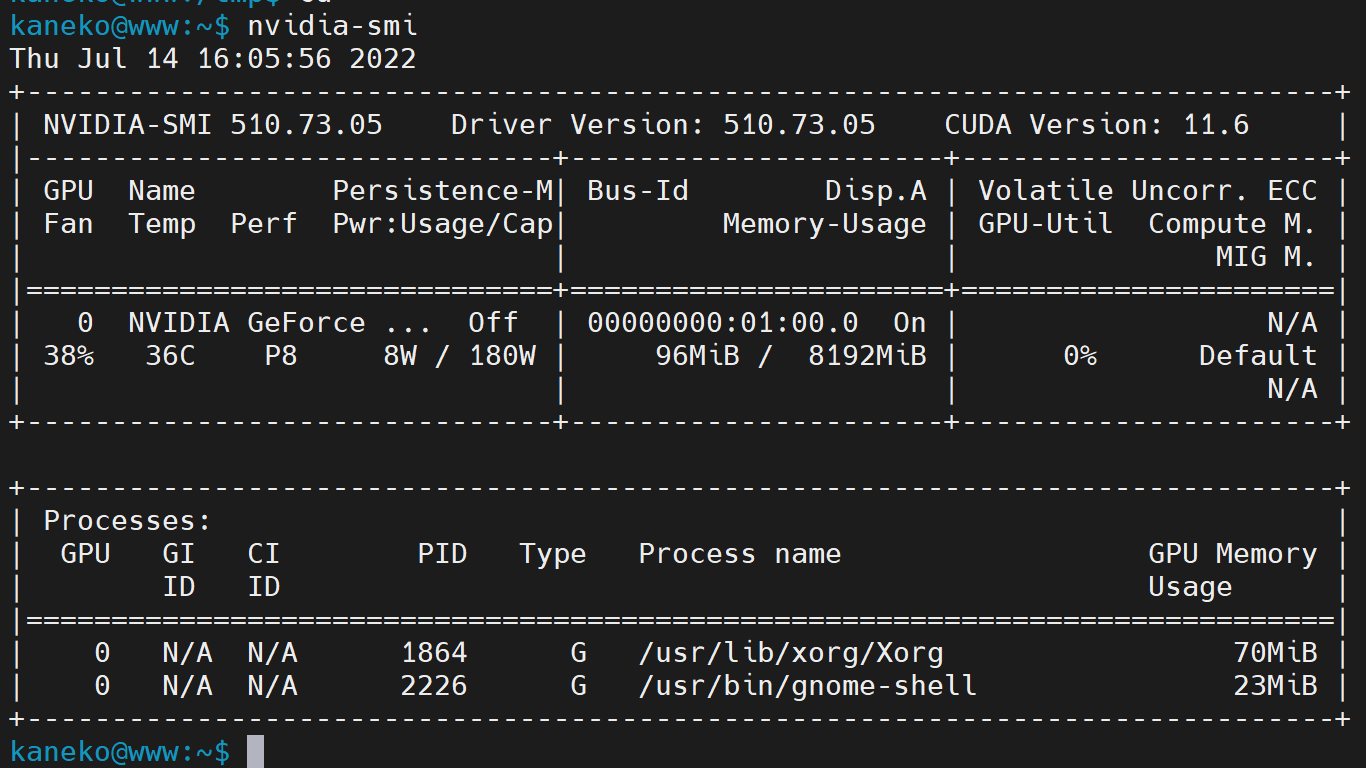
4.7 NVIDIAドライバの確認
再起動後、ドライバが正しくインストールされ、GPUが認識されているか確認する。
nvidia-smi
(コマンド実行結果の Driver Version にバージョンが表示され、GPU情報が表示されれば成功)
5. NVIDIA CUDA Toolkit 11.8 のインストール
5.1 Ubuntuバージョンの確認
CUDAリポジトリの選択に必要なため、Ubuntuのバージョンを確認する。
uname -m # アーキテクチャ(x86_64等)を確認
lsb_release -a # ディストリビューション名とバージョンを確認
# cat /etc/*release # より詳細な情報を確認
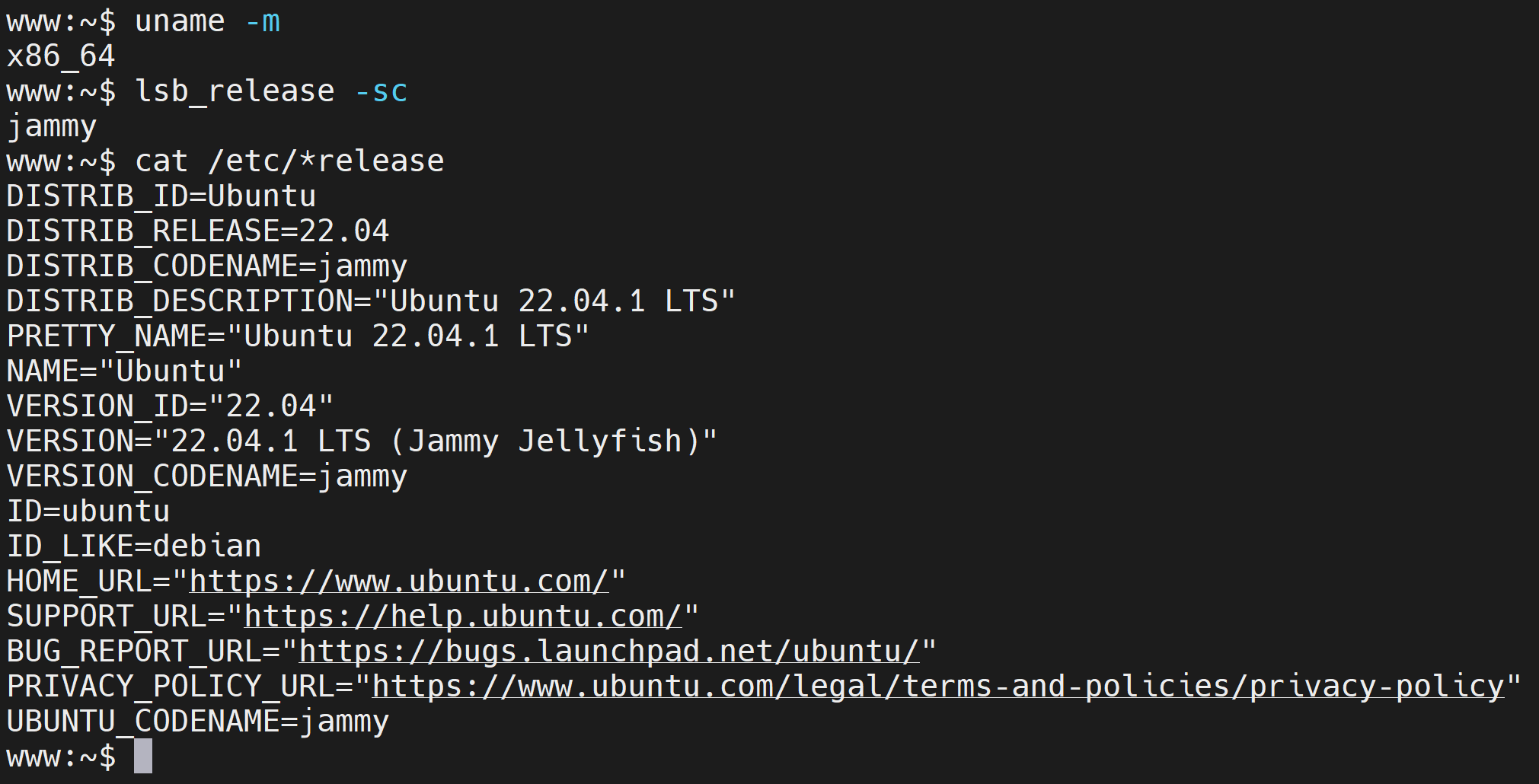
Ubuntu のバージョンが表示されるので確認する。VERSION_ID の行などで確認できる。
5.2 NVIDIA CUDAリポジトリの追加
インストールするCUDA Toolkitのバージョン(11.8)とUbuntuのバージョンに合わせた公式リポジトリを追加する。
(apt-keyに関する注意) apt-key コマンドは非推奨となっている。可能であれば、gpgコマンドを使用してキーを /etc/apt/trusted.gpg.d/ ディレクトリに保存する方法が推奨されるが、ここでは元の手順に従う。将来的にこの方法は動作しなくなる可能性がある。
NVIDIA CUDA パッケージレポジトリ URL: https://developer.download.nvidia.com/compute/cuda/repos/(各Ubuntuバージョンのディレクトリを確認)
Ubuntuバージョンごとの手順:
- Ubuntu 22.04 の場合:
最新のNVIDIA公式手順では
cuda-keyringパッケージを使うことが推奨されている。wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb sudo dpkg -i cuda-keyring_1.1-1_all.deb sudo apt-get update

- Ubuntu 20.04 の場合:
Ubuntu 22.04と同様に
cuda-keyringを使う方法を推奨する。wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-keyring_1.1-1_all.deb sudo dpkg -i cuda-keyring_1.1-1_all.deb sudo apt-get update


5.3 インストール可能なCUDAバージョンの確認(任意)
リポジトリからインストール可能なCUDA 11.xのパッケージを確認する。
apt-cache policy cuda-toolkit-11-8 # 特定バージョンの情報を確認
# apt-cache search cuda-11 # cuda-11を含むパッケージを検索
5.4 NVIDIA CUDA Toolkit 11.8 のインストール
CUDA Toolkit 11.8をインストールする。これにより、関連するドライバもインストールされることがあるため、ドライバのインストール手順(セクション4)を先に行うことが推奨される。
(注記) cuda-toolkit-11-8 と cuda-11-8 は内容が異なる場合がある。通常は cuda-toolkit-XX-Y または cuda-XX-Y でインストールする。公式ドキュメントで推奨されるパッケージ名を確認すること。
# パッケージリストの情報を更新
sudo apt update
sudo apt -y install cuda-toolkit-11-8
# sudo apt -y install cuda-11-8 # より包括的なパッケージの場合
5.5 環境変数の設定
CUDA Toolkitのコマンド(nvccなど)やライブラリを利用できるように、環境変数を設定し、~/.bashrc に追記して永続化する。
export CUDA_HOME=/usr/local/cuda-11.8
echo 'export CUDA_HOME=/usr/local/cuda-11.8' >> ${HOME}/.bashrc
export LD_LIBRARY_PATH=/usr/local/cuda-11.8/lib64:${LD_LIBRARY_PATH}
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-11.8/lib64:${LD_LIBRARY_PATH}' >> ${HOME}/.bashrc
export PATH=/usr/local/cuda-11.8/bin:${PATH}
echo 'export PATH=/usr/local/cuda-11.8/bin:${PATH}' >> ${HOME}/.bashrc
# 設定を即時反映(現在のシェルのみ)
source ${HOME}/.bashrc

5.6 インストールと設定の確認
インストールされたCUDA Toolkitのバージョンと、nvcc コマンドが利用可能か確認する。
cat /usr/local/cuda-11.8/version.json # version.json で詳細バージョンを確認
nvcc --version # nvcc コマンドでバージョンを確認
5.7 再起動(推奨)
システムの状態を安定させるため、CUDA Toolkitインストール後にも再起動を推奨する。
sudo /sbin/shutdown -r now
6. NVIDIA cuDNN 8 のインストール
CUDA Toolkit 11.8 に対応するcuDNN 8をインストールする。
6.1 Ubuntu 22.04、Ubuntu 20.04 の場合
これらのバージョンでは、通常 CUDA Toolkit のリポジトリに含まれるcuDNNパッケージをインストールできる。
-
インストール可能なcuDNNパッケージの確認(任意):
apt-cache search libcudnn8
-
cuDNN 8 のインストール:
(注意)
libcudnn8パッケージはCUDA 11.x 系に対応する。必ずCUDA 11.8 と互換性のあるバージョン(例: cuDNN 8.x.x for CUDA 11.x)がインストールされることを確認すること。apt-cache policy libcudnn8で利用可能なバージョンを確認できる。# パッケージリストの情報を更新 sudo apt update sudo apt -y install libcudnn8=8.x.x.x-1+cuda11.x # バージョンを明示的に指定する場合(バージョン番号は apt-cache policy で確認) sudo apt -y install libcudnn8-dev=8.x.x.x-1+cuda11.x # 開発用ヘッダファイルもインストール # または、バージョン指定なしでインストール(リポジトリのデフォルトに依存) # sudo apt -y install libcudnn8 libcudnn8-dev
-
インストールされたパッケージの確認:
dpkg -l | grep cudnn
6.2 cuDNNバージョンの確認(ヘッダファイルから)
インストールされたcuDNNのバージョンをヘッダファイルから確認する(開発用パッケージ libcudnn8-dev が必要)。
cat /usr/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
# または cat /usr/include/x86_64-linux-gnu/cudnn_v8.h | grep CUDNN_MAJOR -A 2(パスは環境による)
7. 動作確認(nvccコンパイラ)
簡単なCUDA Cプログラムをコンパイル・実行し、nvccコンパイラが正しく動作するか確認する。 (参考: https://devblogs.nvidia.com/easy-introduction-cuda-c-and-c/)
-
サンプルコードの作成:
エディタ(nano、vim、gedit等)で
hello.cuという名前のファイルを作成し、以下の内容を記述して保存する。nano hello.cu
hello.cu:
#include <iostream> #include <vector> #include <numeric> #include <cuda_runtime.h> // CUDA Kernel function to add two vectors __global__ void vectorAdd(const float *A, const float *B, float *C, int numElements) { int i = blockDim.x * blockIdx.x + threadIdx.x; if (i < numElements) { C[i] = A[i] + B[i]; } } int main(void) { int numElements = 50000; size_t size = numElements * sizeof(float); printf("[Vector addition of %d elements]\n", numElements); // Allocate host memory float *h_A = (float *)malloc(size); float *h_B = (float *)malloc(size); float *h_C = (float *)malloc(size); // Initialize host vectors for (int i = 0; i < numElements; ++i) { h_A[i] = rand() / (float)RAND_MAX; h_B[i] = rand() / (float)RAND_MAX; } // Allocate device memory float *d_A = NULL; cudaMalloc((void **)&d_A, size); float *d_B = NULL; cudaMalloc((void **)&d_B, size); float *d_C = NULL; cudaMalloc((void **)&d_C, size); // Copy host vectors to device cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice); cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice); // Launch the kernel int threadsPerBlock = 256; int blocksPerGrid = (numElements + threadsPerBlock - 1) / threadsPerBlock; vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, numElements); // Copy result back to host cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost); // Verify result float maxError = 0.0f; for (int i = 0; i < numElements; ++i) { maxError = fmax(maxError, fabs(h_C[i] - (h_A[i] + h_B[i]))); } printf("Max error: %f\n", maxError); // Cleanup cudaFree(d_A); cudaFree(d_B); cudaFree(d_C); free(h_A); free(h_B); free(h_C); return 0; }
-
コンパイルと実行:
nvccコマンドでコンパイルし、生成された実行ファイル(hello_cudaまたはa.out)を実行する。nvcc hello.cu -o hello_cuda # コンパイル(出力ファイル名を指定) # または nvcc hello.cu(デフォルトで a.out が生成される)

./hello_cuda # 実行(または ./a.out)
実行結果として
Max error: 0.000000のような表示が出れば、CUDA Toolkitが正常に動作していることを確認できる。