Octave でのグラフ作成
- CSV ファイルを読み込み,データを Octave の変数に格納,
- 読み込んだデータからのグラフの作成(散布図を例として説明),
- グラフへの線,凡例の重ね書き,
- グラフのファイルへの保存
前準備
必要となるソフトウェア
前もって決めておく事項
- データを置くディレクトリ: このページでは,C:\octave と書く.
CSVファイルを読み込み,テーブルに格納
- (前準備) 使用する CSV ファイルの作成
* ここでは Book1.csv をダウンロードし,分かりやすいディレクトリに置く
(参考: 「外国為替データ(時系列データ)の情報源の紹介」の Web ページ)
以下の説明では、
- Windows の場合: データファイル名: C:\R\Book1.csv
- Linuxの場合: データファイル名: /tmp/Book1.csv
として説明を続ける.
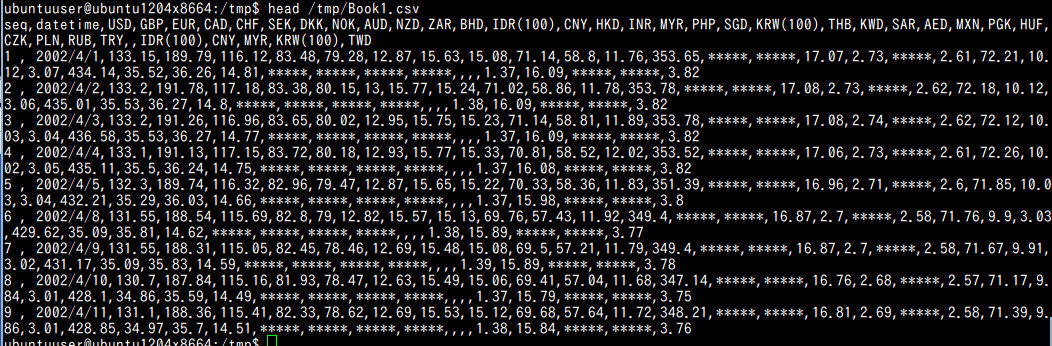
- 使用する CSV ファイルの確認
属性名として seq, date, USD, EUR, AUD の5つが, CSV ファイルの1行目に書かれていることを確認する.
- octave の起動
octave
- octave におけるパッケージの読み込み
次のコマンドを実行.
pkg load io

- 「read.table」を用いて,CSV ファイルを R のデータフレームに読み込み
◆ Windows の場合のOctaveコマンドの例
A = dlmread( "C:\\octave\\Book1.csv", ",/", 1, 0 );
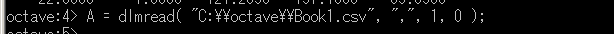
◆ Linux の場合のOctaveコマンドの例
A = dlmread( "/tmp/Book1.csv", ",/", 1, 0 );

- A <- ・・・ 変数 A に読み込むという意味
- C:\\octave\\Book1.csv, /tmp/Book1.csv ・・・ 読み込む CSV ファイル名.Windows では区切りには「\\」を使う.
- seq=",/" ・・・ 列を区切る記号は「,」と「/」.CSV ファイルだから「,」.日付の部分は「01/01/2007」のようになっているから「/」も区切り記号
- 1, 0 ・・・ 1行目から読む(0行目は読み飛ばす).0列目から読む(列の読み飛ばしは無い)
- 変数 A の中身の確認
例えば,次のコマンドを実行する.これは,Aの2行目と3行目と4行目と5行目と6行目と7行目である.
A(:,[2 3 4 5 6 7])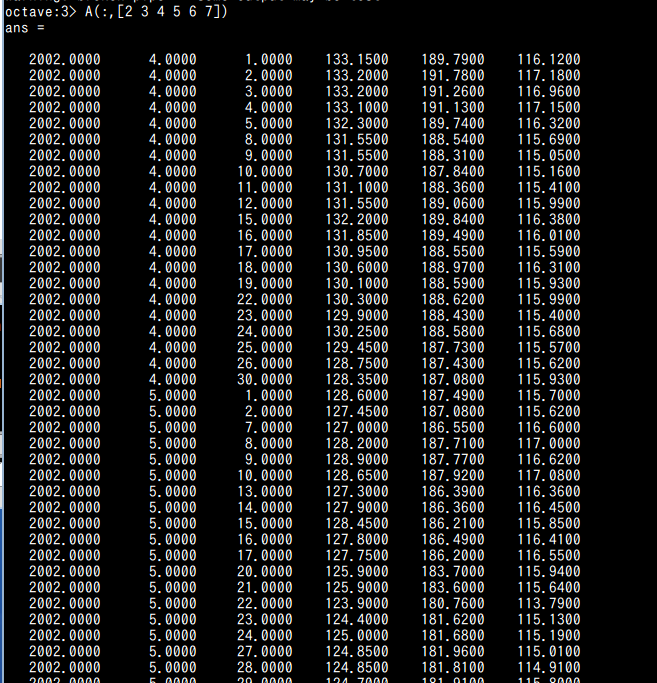
テーブルからのグラフ作成例
- x, y 値を指定しての散布図の作成
x 値を格納したベクトル,y 値を格納した行列(またはベクトル)を引数として plot() 関数を使うと,散布図が描かれます.
この場合「A(:,1)」や「A(:,[5 6 7])」という書き方で,A から列を抜き出して,ベクトルや行列を作る.
* 1本の線
x 値を格納したベクトル,y 値を格納したベクトル
plot( A(:,5), A(:,6) ) close
* 複数の線
x 値を格納したベクトル,y 値を格納した魚憂うt
plot( A(:,1), A(:,[5 6 7]) )
close
「plot( A(:,1), A(:,5), A(:,1), A(:,6), A(:,1), A(:,7) ) 」のように,X 値と Y値のベクトルを交互に並べたときと同じ結果になる.
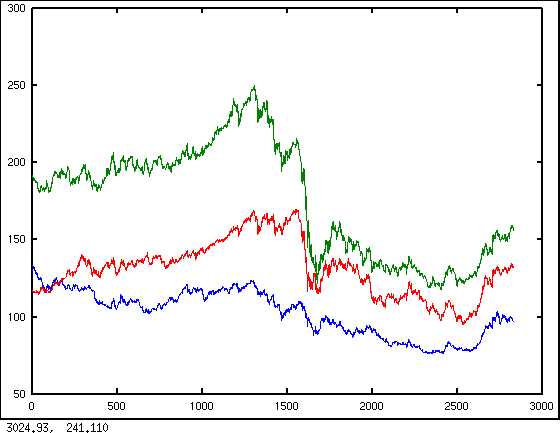
重ね書きの例
「hold on」を実行すると,plot コマンドをいくつか続いて実行したとき,前のグラフが消えないようになる.
平滑化の例
- 平均: 例えば,「filtfilt([1 1 1 1 1]/5, 1, x)」は,周辺 5 点の平均.
- Savitsky-Golay 平滑化 (smoothing) フィルタ: 「sgoleyfilt(x)」 は,Savitsky-Golay 平滑化 (smoothing) フィルタ. sgolayfilt(x, p, n, m, ts) で,p は次数 (polynominal order), n は多項式の項数,
- Spencer's 15 point moving average: spencer
* 平均
x = [zeros(1,20), ones(1,10), zeros(1,20)]
pkg load signal
plot([1:50], x, [1:50], filtfilt([1 1 1 1 1]/5, 1, x))
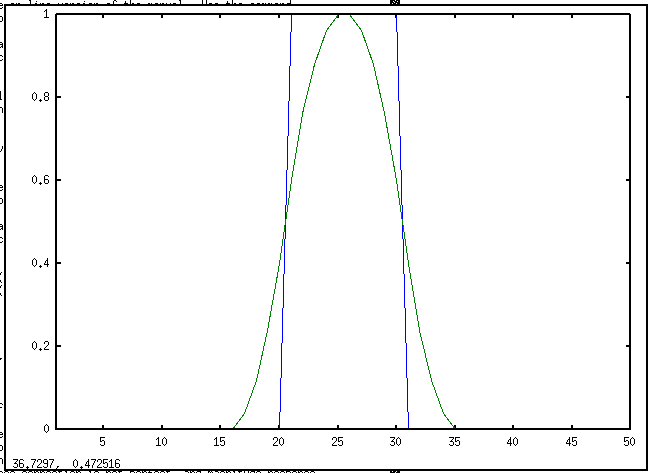
* Savitsky-Golay 平滑化 (smoothing) フィルタ
x = [zeros(1,20), ones(1,10), zeros(1,20)]
pkg load signal
plot([1:50], x, [1:50], sgoleyfilt(x), [1:50], filtfilt([1 1 1 1 1]/5, 1, x))
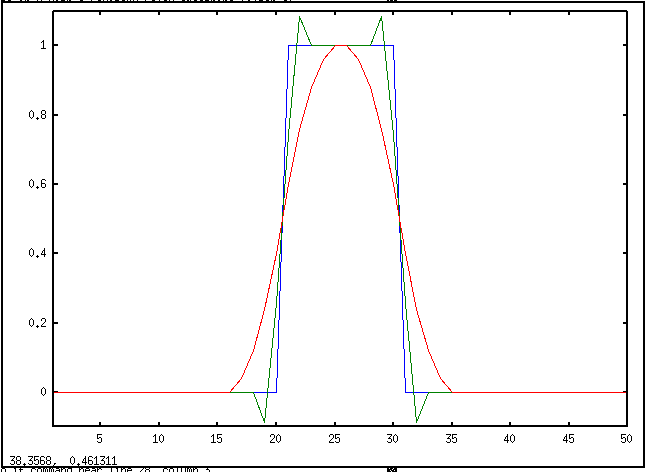
* Spencer's 15 point moving average
x = [zeros(1,20), ones(1,10), zeros(1,20)]
pkg load signal
plot([1:50], x, [1:50], spencer(x), [1:50], filtfilt([1 1 1 1 1]/5, 1, x))
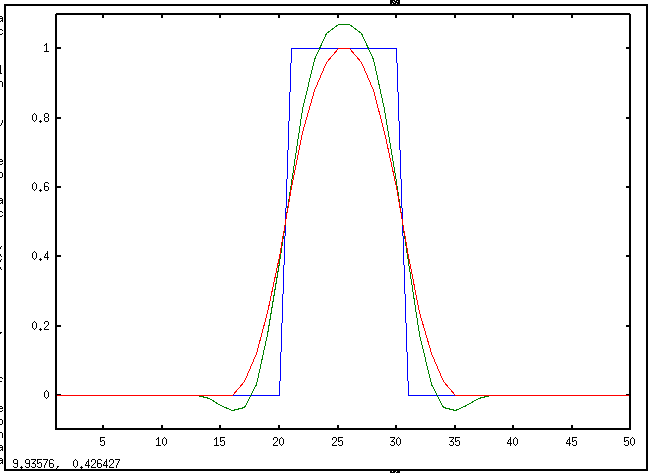
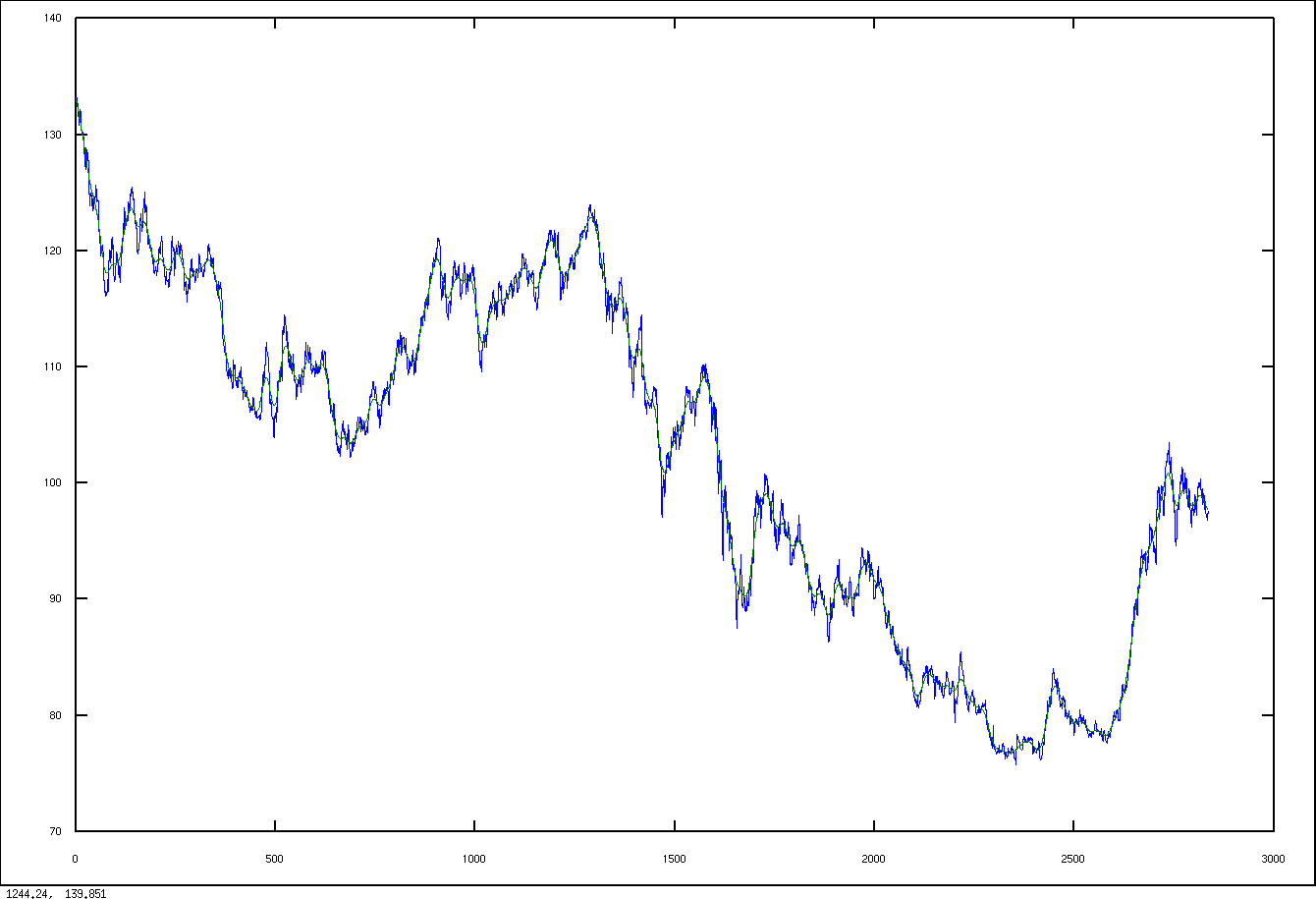
* 「外国為替データ(時系列データ)」の平滑化(例) 「filtfilt ...の部分は,周辺 20 点の平均.
pkg load signal
plot(A(:,1), A(:,5), A(:,1), filtfilt(ones(1,20)/20, 1, A(:,5)))
タイトル,ラベル,範囲指定,格子
次の関数を使う
- title : グラフのタイトル
- xlabel : グラフの x 軸のラベル
- ylabel : グラフの y 軸のラベル
- zlabel : グラフの z 軸のラベル
- axis : グラフの範囲の指定
- grid : グラフに格子 (grid) を表示
- legend : グラフのラベル
凡例
- x 座標
- y 座標
- 凡例として表示する文字列ベクトル
- オプション
plot( X[,c("seq")], X[,c("USD")] )
lines(lowess( X[,c("seq")], X[,c("USD")] ), col = "red")
lines(lowess( X[,c("seq")], X[,c("USD")], f=0.2 ), col = "green")
legend( 5, 105, c( "f = 2/3", "f = 0.2" ), lty = 1, col = c("red", "green") )
テキストを書くこともできる.
text(locator(1), labels = "ほげほげ")