SQLite 3の利用
【概要】SQLite 3は高性能かつ信頼性に優れたリレーショナルデータベース管理システムである。本ガイドでは、データベース環境の構築から実践的な操作方法、データ整合性の確保、クエリ最適化まで、SQLite 3の主要機能と活用方法について体系的に解説する。
【目次】
- データベース環境の構築と前準備
- 実践的なデータベース操作ガイド
- データベース作成手順
- 既存データベースの活用方法
- データベース設計とデータ整合性の確保
- データの登録と管理
- データ整合性の検証と管理
- データ検索と分析
- データ更新手法
- データの削除方法
- データのエクスポートと保護
- クエリパフォーマンスの最適化
- SQLスクリプトの実行
- データベース構造の分析と管理
- データベースの保守と復旧対策
Windows環境におけるSQLite 3のインストール手順については、専用のセットアップガイドで詳しく解説している。
1. データベース環境の構築と前準備
SQLite 3の詳細情報: SQLite 3技術解説 »
データベース設定の基本事項
データベース運用を実現するため、以下の基本的な設定を行う。
- データベース名の設定: mydb
データベース名は、プロジェクトの特性を反映した半角英数字のみを使用することを推奨する。スペースは使用できない。
- データベースの保存場所: C:\SQLite(Windows環境)、/tmp(Linux環境)
保存場所は管理の容易な場所を選択し、半角英数字のみを使用する。スペースは使用できない。
2. 実践的なデータベース操作ガイド
- SQLite 3データベースの新規作成手順
- 既存データベースの活用方法
- データベース設計とデータ整合性の実装
リレーショナルスキーマの定義例: order_records(id, year, month, day, customer_name, product_name, unit_price, qty)
SQL実装コードについては、セクション5で詳しく解説する。
- データ登録手法
- データ整合性の検証方法
- データ検索技術
- データ更新の実装
- データの削除手順
- データのバックアップと保護
- クエリ実行の最適化手法
- SQLスクリプトの実行方法
- データベース構造の解析
- データベースの保守と復元手順
3. データベース作成手順
Windows環境でのSQLite 3起動手順
Windows環境での具体的な操作手順について解説する。
以下の手順に従って、新規のSQLite 3データベースC:\SQLite\mydbを作成する。
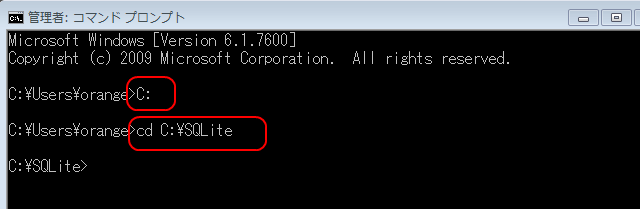
- Windowsのコマンドプロンプトで以下の操作を実行する。
SQLite 3のデータベースディレクトリC:\SQLiteに移動する。
cd /d C:\SQLite
- sqlite3.exeの起動と初期設定
新規データベースを作成するため、sqlite3.exe起動時に新しいデータベースファイル名を指定する。
データベースファイル名は、半角英数字のみを使用することを推奨する。
具体例として、データベースファイル名をmydbとする場合の操作手順を示す。
.\sqlite3.exe mydb
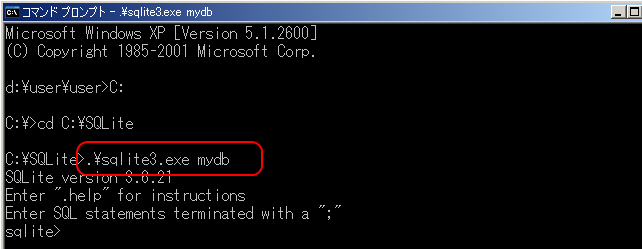
この操作により、mydbという名前のデータベースファイルが存在しない場合、自動的に新規作成される。
データベースファイルは、テーブル定義などのデータベース更新操作時に生成される。起動直後にファイルが見当たらなくても問題ない。
Ubuntu環境でのSQLite 3起動手順
Ubuntu環境での具体的な操作手順について解説する。
以下の手順に従って、新規のSQLite 3データベース/tmp/mydbを作成する。
- Ubuntuの端末で以下の操作を実行する。
SQLite 3のデータベースディレクトリ/tmpに移動する。
cd /tmp
- SQLite 3の起動と初期設定
新規データベースを作成するため、sqlite3の起動時に新しいデータベースファイル名を指定する。
データベースファイル名は、半角英数字のみを使用することを推奨する。
具体例として、データベースファイル名をmydbとする場合の操作手順を示す。
sqlite3 /tmp/mydb

この操作により、mydbという名前のデータベースファイルが存在しない場合、自動的に新規作成される。
データベースファイルは、テーブル定義などのデータベース更新操作時に生成される。起動直後にファイルが見当たらなくても問題ない。
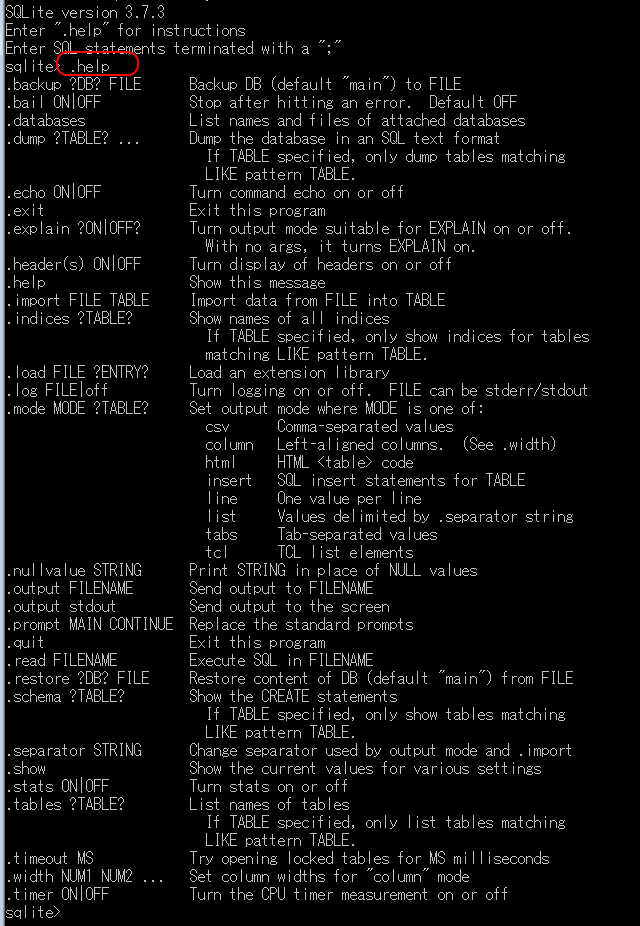
SQLite 3のヘルプ機能
.helpコマンドを実行すると、利用可能な全コマンドとその使用方法が表示される。
文字エンコーディングの設定と確認
現在使用中のデータベースの文字エンコーディングを確認するには、以下の手順を実行する。
PRAGMA encoding;コマンドを実行すると、現在の文字エンコーディング設定が表示される。
データベースの削除手順
データベースを削除する場合は、対応するデータベースファイルを直接削除する。
SQLite 3の終了手順
.exitコマンドを実行することで、データベースを終了できる。

4. 既存データベースの活用方法
以下の手順に従って、既存のデータベースファイルC:\SQLite\mydbにアクセスする。
- Windowsのコマンドプロンプトで以下の操作を実行する。
SQLite 3のデータベースディレクトリC:\SQLiteに移動する。
cd /d C:\SQLite
- sqlite3.exeの起動とデータベース接続
sqlite3.exe起動時に、アクセスするデータベースファイル名を明示的に指定する。例えば、mydbという既存のデータベースに接続する場合は、以下のコマンドを実行する。
.\sqlite3.exe mydb
5. データベース設計とデータ整合性の確保
SQLを使用して、order_recordsテーブルを定義し、データの整合性を確保する。
リレーショナルスキーマ定義: order_records(id, year, month, day, customer_name, product_name, unit_price, qty)
- テーブル定義用SQLの実行
create table order_records ( id INTEGER PRIMARY KEY autoincrement not null, year INTEGER not null CHECK ( year > 2008 ), month INTEGER not null CHECK ( month >= 1 AND month <= 12 ), day INTEGER not null CHECK ( day >= 1 AND day <= 31 ), customer_name TEXT not null, product_name TEXT not null, unit_price REAL not null CHECK ( unit_price > 0 ), qty INTEGER not null DEFAULT 1 CHECK ( qty > 0 ), created_at DATETIME not null, updated_at DATETIME, CHECK ( ( unit_price * qty ) < 200000 ) );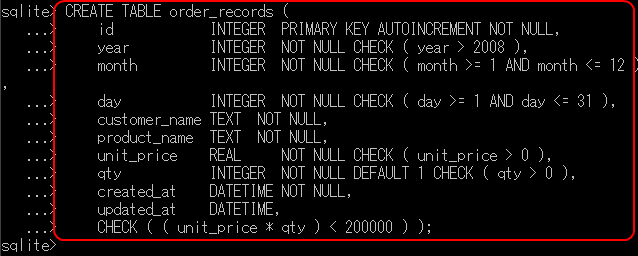
この操作により、C:\SQLiteディレクトリ内に、データベースファイルmydbが自動的に生成される。

SQLiteでは、初回のデータベース更新操作時に自動的にデータベースファイルが生成される。ファイル名はデータベース名と同一になる。
データベースファイルの生成はテーブル定義などの更新操作時に実行される。そのため、起動直後にファイルが存在しなくても問題ない。
6. データの登録と管理
以下のような構造を持つorder_recordsテーブルを作成する。
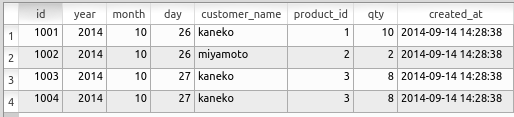
以下の手順に従って、SQLを使用したデータ登録を実行する。
- データ登録用SQLの実行
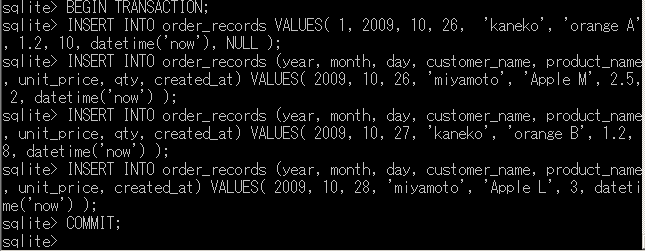
insert into文を使用してデータを登録する。複数のSQL文をトランザクション(複数の操作を一つの処理単位にまとめる仕組み)として実行するため、begin transactionとcommitで処理全体を囲む。
データ整合性の確保: 登録処理の開始前にbegin transaction;を実行し、すべての登録が完了後にcommit;を実行することで、データの整合性を維持する。トランザクションは、すべての操作が成功した場合のみデータベースに反映され、途中で問題が発生した場合は、すべての操作が取り消される。
begin transaction; insert into order_records (year, month, day, customer_name, product_name, unit_price, qty, created_at) values( 2019, 10, 26, 'kaneko', 'orange A', 1.2, 10, datetime('now', 'localtime') ); insert into order_records (year, month, day, customer_name, product_name, unit_price, qty, created_at) values( 2019, 10, 26, 'miyamoto', 'Apple M', 2.5, 2, datetime('now', 'localtime') ); insert into order_records (year, month, day, customer_name, product_name, unit_price, qty, created_at) values( 2019, 10, 27, 'kaneko', 'orange B', 1.2, 8, datetime('now', 'localtime') ); insert into order_records (year, month, day, customer_name, product_name, unit_price, created_at) values( 2019, 10, 28, 'miyamoto', 'Apple L', 3, datetime('now', 'localtime') ); commit;datetime('now', 'localtime')関数は現在の日時を取得し、DATETIME型としてYYYY-MM-DD HH:MM:SS形式で保存する。
データ登録には、以下の2つの主要な方式がある。
1. 全カラム指定方式: テーブル定義の順序に従ってすべての値を指定
insert into order_records values( 1, 2019, 10, 26, 'kaneko', 'orange A', 1.2, 10, datetime('now', 'localtime'), NULL );2. カラム名指定方式: 登録するカラムを明示的に指定
insert into order_records (year, month, day, customer_name, product_name, unit_price, qty, created_at) values( 2019, 10, 26, 'miyamoto', 'Apple M', 2.5, 2, datetime('now', 'localtime') );カラム名指定方式では、id列を省略することで、autoincrementにより自動的に連番が割り当てられる。明示的に指定されていないカラムには、定義されたデフォルト値が自動的に適用される。本ガイドでは、autoincrement設定されている主キー列は省略し、データベースに自動採番させるカラム名指定方式を採用している。
7. データ整合性の検証と管理
ここでは、データ整合性制約に違反する更新操作を意図的に試行し、データベース管理システムによる整合性保護機能を検証する。以下の例では、制約の動作を確認するため、id列を明示的に指定している。
主キー制約の検証(PRIMARY KEY)
begin transaction;
insert into order_records (id, year, month, day, customer_name, product_name, unit_price, qty, created_at) values( 3, 2019, 10, 30, 'kaneko', 'banana', 10, 3, datetime('now', 'localtime') );
ROLLBACK;
既存のid値と重複するため、主キー制約(PRIMARY KEY)に違反し、エラーが発生する。

エラー発生時の対処方法
データベース操作でエラーが発生した場合、ROLLBACKコマンドを使用して、トランザクション開始以降のすべての変更を取り消すことができる。ROLLBACKは、データベースをトランザクション開始前の状態に戻す操作である。これにより、エラーによる不完全なデータがデータベースに残ることを防ぐ。
非NULL制約の検証(not null)
begin transaction;
insert into order_records (id, year, month, day, customer_name, product_name, unit_price, qty, created_at) values( 5, 2019, 10, 30, NULL, 'melon', 10, 3, datetime('now', 'localtime') );
ROLLBACK;
customer_name列にはnot null制約が設定されているため、NULL値の挿入はできない。エラー発生後、ROLLBACKによりトランザクションを取り消す。

データ値制約の検証
制約違反の例1: 年度範囲の制約
begin transaction;
insert into order_records (id, year, month, day, customer_name, product_name, unit_price, qty, created_at) values( 6, 1009, 10, 30, 'kaneko', 'melon', 10, 3, datetime('now', 'localtime') );
ROLLBACK;
CHECK ( year > 2008 )制約に違反するため、エラーが発生する。ROLLBACKにより変更を取り消す。

制約違反の例2: 取引金額の制約
begin transaction;
insert into order_records (id, year, month, day, customer_name, product_name, unit_price, qty, created_at) values( 7, 2019, 10, 31, 'kaneko', 'strawberry', 4.6, 100000, datetime('now', 'localtime') );
ROLLBACK;
CHECK ( ( unit_price * qty ) < 200000 )制約に違反するため、エラーが発生する。ROLLBACKにより変更を取り消す。

8. データ検索と分析
ここでは、SQLを使用したデータ検索手法について具体例を交えて解説する。
全データの取得と確認
SELECT * FROM order_records;

条件付きデータ検索の実装
SELECT * FROM order_records WHERE product_name = 'orange A';

SELECT * FROM order_records WHERE product_name LIKE 'orange%';
LIKE演算子を使用したパターンマッチング検索の実装例である。LIKE演算子は、文字列の部分一致検索を可能にする。%記号は任意の文字列(0文字以上)を表すワイルドカードである。

SELECT * FROM order_records WHERE unit_price > 2;

SELECT * FROM order_records WHERE qty > 9 AND customer_name = 'kaneko';

9. データ更新手法
SQLを使用したデータ更新(update)の実装方法について解説する。
UPDATE <table-name> SET <attribute-name>=<expression> WHERE <expression>構文を使用し、トランザクション処理でデータ更新を実行する。
- 更新用SQLの実行
UPDATE ... SET ...構文でデータを更新する。トランザクション管理のため、begin transactionとcommitで処理全体を囲む。
begin transaction; UPDATE order_records SET qty=12, updated_at=datetime('now', 'localtime') WHERE id = 1; commit;
- 更新結果の確認と検証

10. データの削除方法
SQLを使用したデータ削除(delete row(s))の実装方法について解説する。
DELETE FROM <table-name> WHERE <expression>;構文を使用し、トランザクション処理でデータ削除を実行する。
- 削除用SQLの実行
begin transaction; DELETE FROM order_records WHERE id = 2; commit;

- 削除結果の確認と検証

11. データのエクスポートと保護
- CSVフォーマットの設定とファイル出力の指定を行い、SELECT * FROM ...を実行する。
.mode csv .output order_records.csv SELECT * FROM order_records;
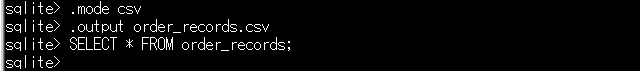
- データの安全性を確保するため、出力先を標準出力に戻す操作を実行する。
.output stdout
- エクスポートされたデータをMicrosoft Excelで開いて内容を確認する。

出力形式の設定と管理
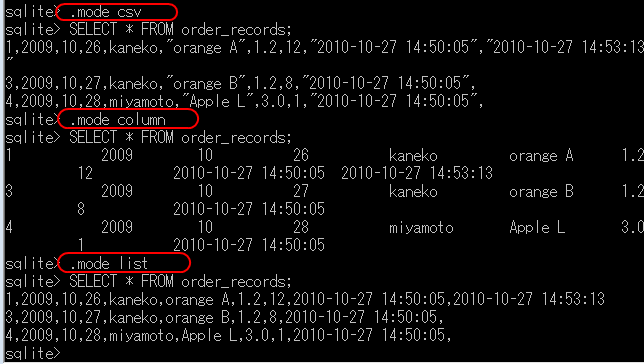
SQLite 3では、以下の主要な出力形式をサポートしている。
- .mode csv: データをカンマ区切り形式で出力
- .mode column: データを左揃えの列形式で出力
- .mode list: カスタム区切り文字を使用してデータを出力(区切り文字は.separatorコマンドで設定可能)
実行結果のファイル出力設定
SQLの実行結果を外部ファイルに保存する場合は、.outputコマンドを使用する。
- .output <ファイル名>: 指定したファイルへ出力を保存
- .output stdout: 標準出力(画面表示)へ出力を切り替え
12. クエリパフォーマンスの最適化
SQLクエリの前にexplainキーワードを付加することで、クエリの実行計画を確認できる。また、.explainコマンドを使用して表示形式を制御することが可能である。.explain onと.explain offコマンドで、実行計画の表示形式を切り替えることができる。
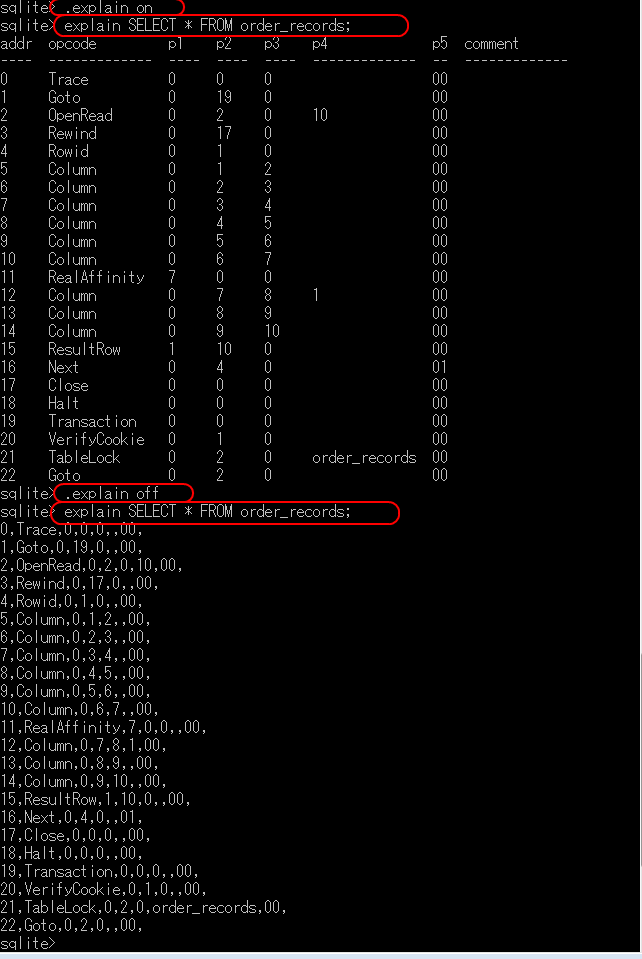
13. SQLスクリプトの実行
.readコマンドは、指定したファイルに記述されたSQL文を順次実行する。
.read <ファイル名>
14. データベース構造の分析と管理
テーブル構造の確認
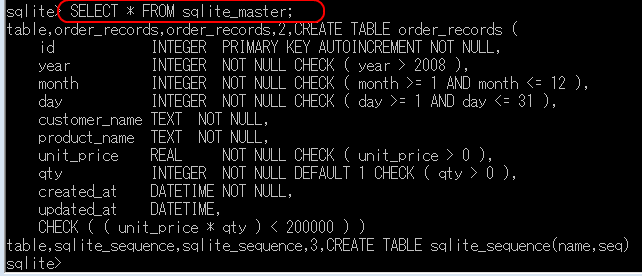
データベース内のテーブル構造を確認するには、システムテーブルsqlite_masterとsqlite_temp_masterを活用する。
- sqlite_master: 永続テーブルのスキーマ情報を管理
- sqlite_temp_master: 一時テーブルのスキーマ情報を管理
データベース構造の確認は、以下のコマンドで実行する。
SELECT * FROM sqlite_master;
SELECT * FROM sqlite_temp_master;
これらのシステムテーブルは読み取り専用である。DROP TABLE、UPDATE、INSERT、DELETE操作は実行できない。
インデックス情報の管理
SQLite 3の.indicesコマンドを使用して、インデックス情報を確認できる。
CREATE INDEX idx1 ON order_records(customer_name);
.indices

15. データベースの保守と復旧対策
.dumpコマンドを使用して、データベースのバックアップを作成する。特定のテーブルのみをバックアップする場合は、.dump テーブル名コマンドを使用する。
デフォルトでは、バックアップの内容は標準出力(画面)に表示される。
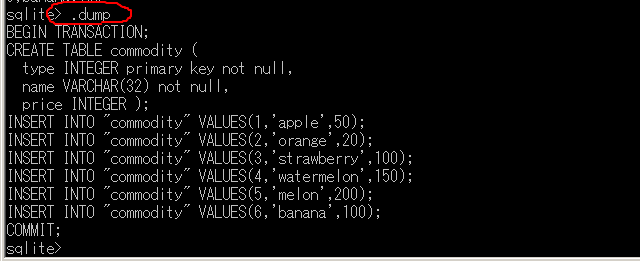
バックアップをファイルに保存する場合は、実行前に.output ファイル名コマンドを実行する。

バックアップからデータを復元する場合は、.read ファイル名コマンドを実行する。
