AIエディタ Windsurf の活用
【概要】WindsurfはVS Codeベースの無料でも利用できるAIエディタである。DeepSeek-V3-0324は無料利用できる。Ctrl+LでCascade機能を起動し、日本語でさまざまな依頼が可能である。API Key不要でアカウント登録のみで使用できる。
【目次】
- メリットと機能
- 基本機能とショートカットキー
- 無料プランの機能
- API Key 要件
- Cursor と Windsurf の比較
- 事前準備
- Windsurf の起動と初回設定
- Windsurf の推奨モデル
- DeepSeek-V3-0324 モデルの選択手順
- Windsurf をエディタとして活用する
- Windsurf の AI 機能の活用
- Windsurf の重要機能一覧
【資料】旧版のWord windsurf.docx、PDF windsurf.pdf(このページの記事が最新版である)
【サイト内のPython関連主要ページ】
- Windows AI支援Python開発環境構築ガイド: 別ページ »で説明
- AIエディタ Windsurf の活用: 別ページ »で説明
- AIエディタCursorガイド: 別ページ »で説明
- Google Colaboratory: 別ページ »で説明
- Python(Google Colaboratoryを含む)のまとめ: 別ページ »で説明
- 機械学習の Python 実現ガイド: 別ページ »で説明
- 行列計算の Python 実現ガイド: 別ページ »で説明
- 統計分析のPython での実現ガイド: 別ページ »で説明
- 音声信号処理の Python 実現ガイド: 別ページ »で説明
- カラー画像処理の Python 実現ガイド: 別ページ »で説明
- Python 言語によるとても簡単なアドベンチャーゲーム(変数,式,if,while,関数,print,time.sleep, def, global を使用): 別ページ »で説明
- Pythonプログラミング講座:基礎から応用まで(授業資料,全15回): 別ページ »で説明
- Pythonプログラミングの例と実践ガイド: 別ページ »で説明
【外部リソース】
- Pythonの公式サイト: https://www.python.org
- 東京大学の「Pythonプログラミング入門」: https://utokyo-ipp.github.io/IPP_textbook.pdf
- ITmedia社の「Pythonチートシート」の記事: https://atmarkit.itmedia.co.jp/ait/articles/2004/20/news015.html
1. メリットと機能
WindsurfはVS Codeをベースとした統合開発環境であり、AI機能を標準搭載している。無料プランが提供されており、学生や個人開発者にとって利用しやすい環境となっている。VS Codeと操作法が類似しているため、既存のVS Code利用者は移行が容易である。全てではないが、VS Codeの多くの拡張機能をそのまま利用できる点も特徴である。
Windsurf Tabと呼ばれるコード補完機能は、Tabキーを活用した効率的なコーディングを実現する。Cascade機能はコード生成や実行を支援するAI機能であり、開発作業を大幅に効率化する。
データ処理時の注意事項として、個人情報を含む画像やデータを使用する場合は、適切な匿名化処理を行い、データ保護法に従って取り扱う必要がある。
2. 基本機能とショートカットキー
Cascade 機能
Cascadeはコード生成や実行を支援するAI機能である。Ctrl + Lキーを同時押しすることでCascadeパネルを開くことができる。日本語でのリクエストに対応しており、例えば「Pythonで折れ線グラフのサンプルコードを作成して」のように自然言語で指示を出すことができる。
主要ショートカットキー
Windsurfの主要なショートカットキーは以下の通りである。
Ctrl + LでCascade(AI対話)パネルを開くCtrl + IでAIコード生成機能を起動するCtrl + `で統合ターミナルを開くF5でデバッグを開始するTabでコード補完候補を選択する
3. 無料プランの機能
Windsurfの無料プランでは、月25クレジットのプロンプトクレジットが提供される。これはGPT-4.1プロンプト約100回分に相当する。利用可能なAIモデルとして、GPT-4.1(0.25クレジット/プロンプト)、Claude 3.7 Sonnet(1クレジット/プロンプト)、DeepSeek-V3-0324(無料)などの複数のモデルを選択できる。
無制限のFast TabやSWE-1 Liteなどの機能も無料プランに含まれている。
4. API Key 要件
Windsurfではサードパーティの API キー(外部サービスにアクセスするための認証キー)は不要である。Windsurfアカウントの作成のみで利用を開始できる。アカウント登録は無料で行うことができ、登録完了後すぐに利用開始が可能である。
5. Cursor と Windsurf の比較
Claude 3.7 Sonnetの利用回数について、Cursor無料版は月50回、Windsurf無料版は月約25回利用可能である。ただしWindsurfでは、無料(0クレジット)のモデル(DeepSeek-V3-0324など)が無制限で利用できる点が特徴的である。
6. 事前準備
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照されたい。
Python 3.12 のインストール
インストール済みの場合は実行不要である。
管理者権限でコマンドプロンプトを起動する。起動手順は、Windowsキーまたはスタートメニューから「cmd」と入力し、右クリックで「管理者として実行」を選択する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。以下のコマンドを実行する。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】Python の公式ページ: https://www.python.org/
AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AIエディタの利用を推奨する。ここでは、Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動する。起動手順は、Windowsキーまたはスタートメニューから「cmd」と入力し、右クリックで「管理者として実行」を選択する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。以下のコマンドを実行して、Windsurfをシステム全体にインストールする。
winget install --scope machine Codeium.Windsurf -e --silent【関連する外部ページ】Windsurf の公式ページ: https://windsurf.com/
Ubuntu環境での設定
ターミナルを開き、以下のコマンドを実行する。
# システムの更新
sudo apt update && sudo apt upgrade -y
# Python3と開発環境のインストール
sudo apt install -y python3 python3-pip python3-venv python3-dev build-essential
# Windsurf(Cursor系エディタ)のインストール
# 公式サイトからダウンロードするか、以下の方法でインストール
wget -qO- https://download.codeium.com/windsurf/linux/install.sh | sh
7. Windsurf の起動と初回設定
Windsurfの初回起動時には、いくつかの設定手順を実行する必要がある。
- Windsurfを起動する。スタートメニューから起動するか、コマンドラインで「windsurf」コマンドを実行する。
- 「Get Started」をクリックする。
- VS Codeから設定を引き継ぎたい場合は「Import from VS Code」を選択し、そうでない場合は「Start fresh」を選択する。
- 設定を続行する。
- 「Log in to Windsurf」の画面で、「Sign up」をクリックしてアカウントを新規作成する。この登録情報は記録しておき、次回からは「Log in」でログインする。Googleアカウントを使用してWindsurfのアカウント登録も可能である。これでインストールと初期設定は完了である。
- Getting Started(始めよう)の画面を確認する。
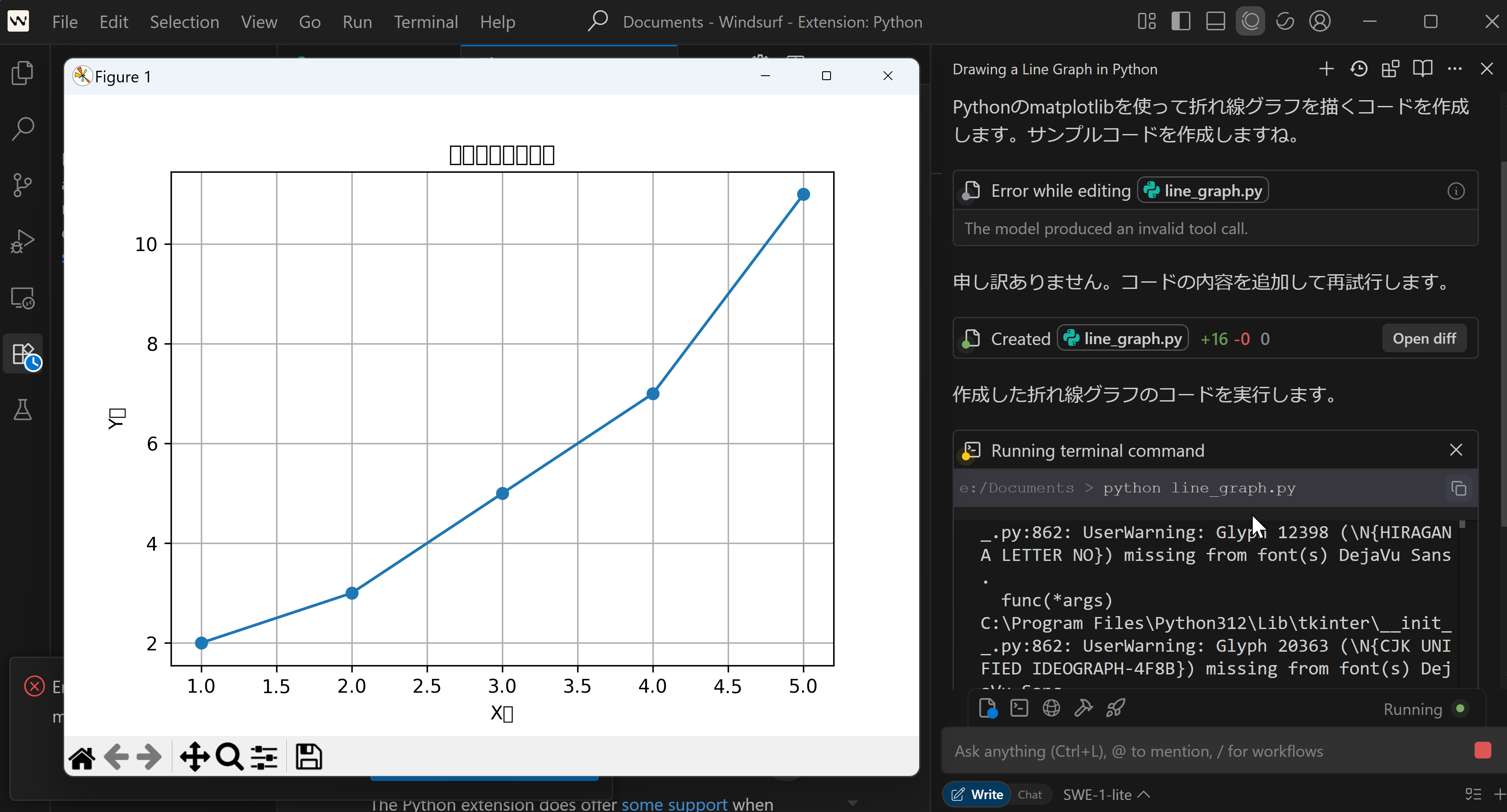
- 動作確認のため、Ctrl + Lを同時押ししてCascadeを開き、「折れ線グラフを描くコードを出して」などと入力し、Enterキーを押す。
コードが出力される。
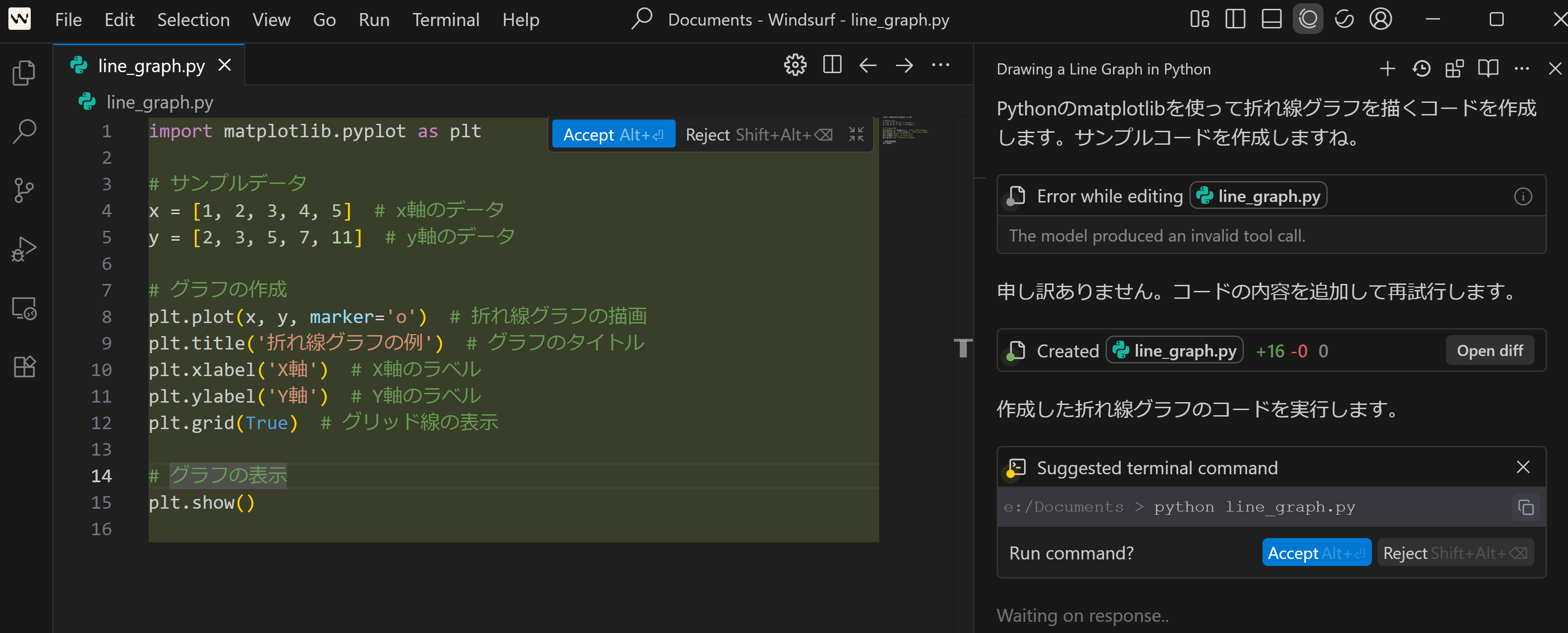
このとき、左下に「Do you want to install the recommended 'Python' extension...」という画面が出る場合がある。「Install」をクリックする。インストール終了を待つ。
AIパネルには「コードを実行します」のように表示される。実行する場合は「Accept」をクリックする。
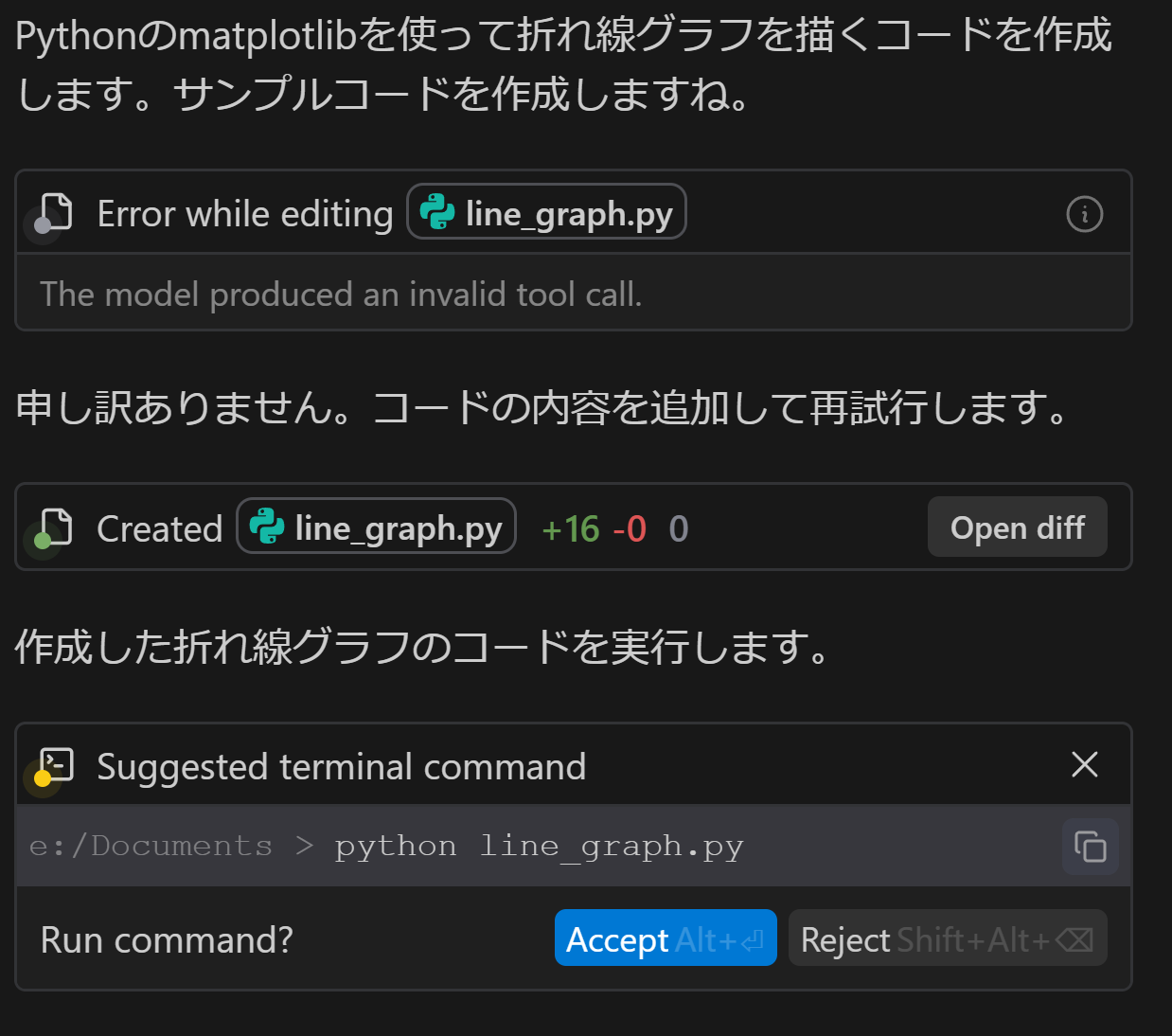
実行結果を確認する。
8. Windsurf の推奨モデル
クレジットを節約するため、以下のモデルの利用を推奨する。
- DeepSeek-V3-0324(0クレジット・恒久的)
- SWE-1(0クレジット・期間限定)
- SWE-1-lite(0クレジット・軽量版)
9. DeepSeek-V3-0324 モデルの選択手順
DeepSeek-V3-0324モデルを選択する手順は以下の通りである。
- Cascadeパネル(Ctrl + Lを同時押し)を開く。
- 入力欄上部のモデル選択ドロップダウンをクリックする。
- 使用モデル(例:「DeepSeek-V3-0324」)を選択する。
10. Windsurf をエディタとして活用する
ここでは、Windsurfで、ファイル作成、コード編集、実行を行う。
1. Windsurf の起動
Windsurfを起動する。スタートメニューなどを使用する。起動直後にログインを求められた場合はログインする。通常は自動ログインされる。最初の起動では、サインイン(IDとパスワードの登録)が必要である。サインインの際は、Googleアカウントの利用を推奨する。
2. 新規ファイルの作成
- 新規ファイルを作成する。メニューで「File」>「New File」を選択する。
- ファイル名を設定する。例えば
a.pyとする。このとき、拡張子を「.py」に設定する。これはPythonファイルとして認識させるためである。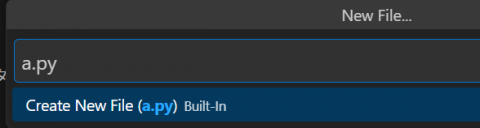
- ファイル作成を確定する。Enterキーを押し、「Create File」をクリックする。
3. プログラムの入力と実行
- Windsurfの
a.py画面で、以下のプログラムを入力する。
print(100 + 200)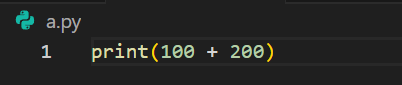
このとき、左下に「Do you want to install the recommended 'Python' extension...」という画面が出る場合がある。「Install」をクリックする。インストール終了を待つ。
- プログラムを実行する。画面上部の三角形の実行ボタンをクリックする。実行ボタンがない場合は、Python extensionをインストールする。
- 実行結果として「300」が表示されることを確認する。ターミナルがない場合には、「View」メニュー > 「Terminal」を選択する。
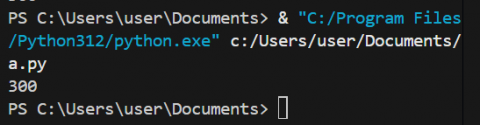
print()はPythonの関数であり、括弧内の値や計算結果を画面に表示する。この例では、100 + 200の計算結果である300が出力される。
11. Windsurf の AI 機能の活用
ここでは、Windsurfで本格的なプログラム実行(AIによる画像分類を行うプログラム)とAIとの対話を行う。
1. AI による画像分類プログラムのための必要なライブラリのインストール
管理者権限で起動したコマンドプロンプト(手順:Windowsキーまたはスタートメニュー > cmdと入力 > 右クリック > 「管理者として実行」)で以下を実行する。
pip install torch torchvision matplotlib numpy pillow japanize-matplotlibpipはPythonのパッケージ管理システムである。インターネット上のライブラリを自動的にダウンロードし、インストールする機能を持っている。
ライブラリとは、プログラミングにおいて、再利用可能なプログラムの集合体である。機械学習や画像処理などの複雑な処理を簡単に実装できる。
各ライブラリの役割は以下の通りである。
- PyTorch (torch)はFacebookが開発した機械学習フレームワーク(プログラム開発を効率化するための基盤ソフトウェア)である。深層学習の実装に使用される。
- torchvisionはPyTorchの画像処理用ライブラリである。画像データの前処理やデータセットの読み込みに使用される。
- Matplotlibはグラフや図表を作成するライブラリである。データの可視化に使用される。
- NumPyは数値計算ライブラリである。多次元配列の操作や数学関数を提供する。
- Pillowは画像処理ライブラリである。画像の読み込み、編集、保存が可能である。
- japanize-matplotlibはMatplotlibで日本語を正しく表示するためのライブラリである。
2. 画像分類プログラムの実装
画像分類とは、コンピュータが画像を見て、その画像に写っているものが何かを自動的に判断する技術である。人工知能の代表的な応用分野の一つである。
- 必要なライブラリのインストール
管理者権限でコマンドプロンプトを起動する。起動手順は、Windowsキーまたはスタートメニュー > cmdと入力 > 右クリック > 「管理者として実行」を選択する。以下を実行する。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126 pip install matplotlib numpy japanize-matplotlib - 元のプログラムを削除する。Windsurfエディタ画面内で削除する。
- Windsurfエディタ画面に、以下のプログラムをコピーして貼り付ける。
# CIFAR-10画像分類プログラム
# CNNによる10クラス画像分類と学習過程の可視化
# 論文: "Deep Residual Learning for Image Recognition" (CVPR 2016)
# GitHub: https://github.com/pytorch/vision/tree/main/torchvision/models
# 特徴: 畳み込みニューラルネットワーク(CNN)は画像の局所的特徴を効率的に抽出
# CIFAR-10データセットで約70-80%の精度、並列処理により高速学習
# 前準備: pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
# pip install matplotlib numpy japanize-matplotlib
# (管理者権限のコマンドプロンプトで実行)
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import japanize_matplotlib
# 定数定義
BATCH_SIZE = 32
EPOCHS = 5
LEARNING_RATE = 0.001
RANDOM_SEED = 42
# 再現性確保のためのシード設定
torch.manual_seed(RANDOM_SEED)
np.random.seed(RANDOM_SEED)
# データセットのクラス名
CLASSES = ['飛行機', '自動車', '鳥', '猫', '鹿', '犬', 'カエル', '馬', '船', 'トラック']
# デバイス設定
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'使用デバイス: {device}')
if torch.cuda.is_available():
print('GPUを使用して学習を実行します')
else:
print('CPUを使用して学習を実行します')
# データの前処理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# CIFAR-10データセットの読み込み
print("データセットを読み込み中...")
trainset = torchvision.datasets.CIFAR10(
root='./data', train=True, download=True, transform=transform
)
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=BATCH_SIZE, shuffle=True
)
testset = torchvision.datasets.CIFAR10(
root='./data', train=False, download=True, transform=transform
)
testloader = torch.utils.data.DataLoader(
testset, batch_size=BATCH_SIZE, shuffle=False
)
# CNNモデルの定義
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
self.conv3 = nn.Conv2d(64, 64, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(64 * 8 * 8, 64)
self.fc2 = nn.Linear(64, 10)
self.relu = nn.ReLU()
def forward(self, x):
x = self.pool(self.relu(self.conv1(x)))
x = self.pool(self.relu(self.conv2(x)))
x = self.relu(self.conv3(x))
x = x.view(-1, 64 * 8 * 8)
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
model = CNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
# メイン処理
print("学習を開始します...")
train_losses = []
val_losses = []
model.train()
for epoch in range(EPOCHS):
# 訓練フェーズ
model.train()
running_train_loss = 0.0
for inputs, labels in trainloader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_train_loss += loss.item()
# 検証フェーズ
model.eval()
running_val_loss = 0.0
with torch.no_grad():
for inputs, labels in testloader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
running_val_loss += loss.item()
epoch_train_loss = running_train_loss / len(trainloader)
epoch_val_loss = running_val_loss / len(testloader)
train_losses.append(epoch_train_loss)
val_losses.append(epoch_val_loss)
print(f'エポック {epoch+1}/{EPOCHS}: 訓練損失 = {epoch_train_loss:.4f}, 検証損失 = {epoch_val_loss:.4f}')
print("評価を実行中...")
model.eval()
correct = 0
total = 0
test_images = []
test_labels = []
predictions = []
with torch.no_grad():
for images, labels in testloader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
if len(test_images) < 5:
for j in range(min(5 - len(test_images), images.size(0))):
test_images.append(images[j].cpu())
test_labels.append(labels[j].cpu())
predictions.append(predicted[j].cpu())
accuracy = 100 * correct / total
# 結果出力
plt.figure(figsize=(15, 3))
for i in range(5):
plt.subplot(1, 5, i+1)
img = test_images[i].permute(1, 2, 0)
img = img * 0.5 + 0.5
plt.imshow(img)
plt.title(f'予測: {CLASSES[predictions[i]]}\n実際: {CLASSES[test_labels[i]]}')
plt.axis('off')
plt.tight_layout()
plt.show()
plt.figure(figsize=(8, 4))
plt.plot(range(1, EPOCHS + 1), train_losses, 'b-', label='訓練損失')
plt.plot(range(1, EPOCHS + 1), val_losses, 'r-', label='検証損失')
plt.title('学習過程')
plt.xlabel('エポック')
plt.ylabel('損失')
plt.legend()
plt.grid(True)
plt.show()
print(f"テスト精度: {accuracy:.2f}%")
プログラムの主要概念について説明する。
- CIFAR-10データセットは、10種類の物体(飛行機、自動車、鳥、猫、鹿、犬、カエル、馬、船、トラック)が写った32×32ピクセルの小さなカラー画像60,000枚で構成される標準的な画像認識用データセットである。
- データの前処理では、機械学習において、元のデータをモデルが学習しやすい形に変換する必要がある。ここでは画像の画素値を-1から1の範囲に正規化(データの値を一定の範囲に変換する処理)している。PyTorchではラベルは自動的に適切な形式に変換される。
- CNN(畳み込みニューラルネットワーク)は、画像認識に特化したディープラーニングモデルである。畳み込み層(Conv2d)で画像の特徴を抽出し、プーリング層(MaxPool2d)で情報を集約する構造を持っている。
- エポック(epochs)は、全訓練データを1回学習することを1エポックと呼ぶ。ここでは5エポック、つまり全データを5回繰り返し学習する。
- バッチサイズ(batch_size)は、一度に処理するデータの個数である。32個ずつまとめて処理することで、学習の効率と安定性を向上させる。
- デバイス設定について、PyTorchでは計算をCPUまたはGPUで実行できる。GPUが利用可能な場合は自動的にGPUを使用し、学習を高速化する。
- 損失関数と最適化手法では、CrossEntropyLoss(交差エントロピー損失)で予測と正解の差を計算し、Adam最適化手法でモデルのパラメータを更新する。
3. プログラムの実行と結果確認
- プログラムを実行する。実行ボタンを押してプログラムを開始する。
- 実行完了まで数分待機する。機械学習の処理時間が必要である。
深層学習モデルの訓練は計算量が多いため、通常のプログラムより長い時間を要する。コンピュータの性能により数分程度かかる場合がある。
実行結果の確認手順は以下の通りである。
- 最初にAIによる画像分類結果が表示される。5枚のテスト画像に対する予測結果と正解の比較が表示される。

- 画面を切り替える。確認後、右上の「x」ボタンをクリックして次へ進む。
- 学習曲線(損失の変化)が表示される。モデルの学習過程を可視化したグラフが表示される。
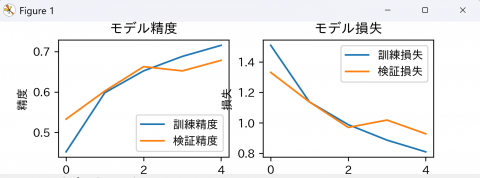
- プログラム実行を終了する。確認後、右上の「x」ボタンをクリックする。
学習曲線の見方について、左のグラフは精度(正解率)の変化を、右のグラフは損失(誤差)の変化を示す。理想的には精度が上昇し、損失が減少する傾向を示す。
4. AI 対話機能の活用
AI対話機能は、Windsurfに搭載された人工知能アシスタント機能である。プログラムに関する質問や、コードの説明、改善提案などを自然言語で対話できる。
- AI対話パネルの起動。Ctrl + Lキーを同時押しする。
- 右側にAI対話用パネルが開く。
AI対話パネルが「Loading...」と表示されて使用できない場合は、Windsurfの再起動(一度Windsurfを終了し、再起動)で解決する場合がある。これはAIサービスへの接続に時間がかかる場合に発生する現象である。
5. AI との対話例
AIへの質問として、右側の対話画面で以下の質問を試すことができる。
- 「このプログラムの機能は」(Enterキー)
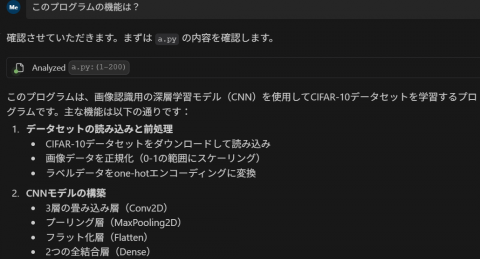
- 「このプログラムの使い方を具体的に教えて」(Enterキー)
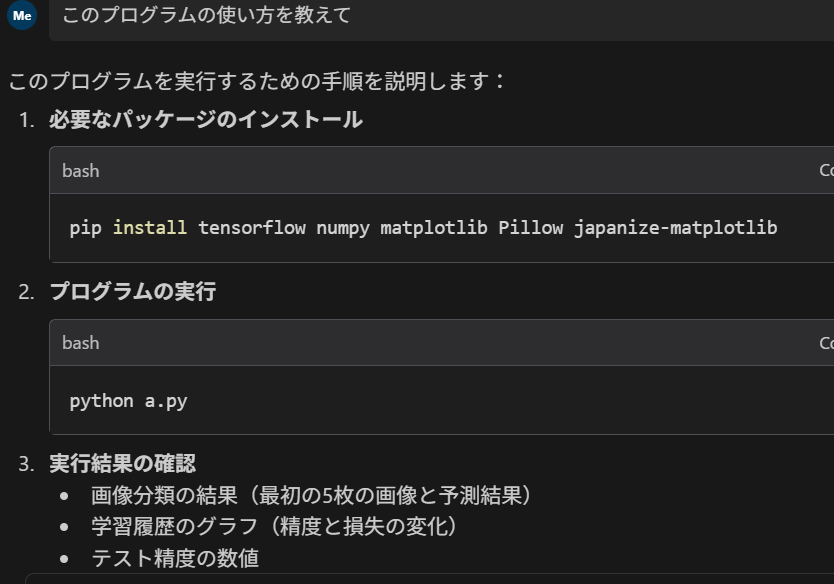
- 「このプログラムを使って何が研究できるの。研究中間発表(研究目標、研究課題、取り組み、期待される成果、独自の工夫予定)のサンプルを簡潔に教えて。そのとき、社会課題の解決を考えて。」(Enterキー)

AIとの効果的な対話について、以下の点に留意する。
- 具体的で明確な質問をする。
- 専門用語が分からない場合は「初心者向けに説明して」と付け加える。
- 複数の質問がある場合は、一つずつ順番に聞く。
- AIの回答に対してさらに詳しく聞きたい場合は「もっと詳しく教えて」と追加質問する。
12. Windsurf の重要機能一覧
AI機能
- AIコード生成機能では、
Ctrl + Iキー、またはAIパネルで「○○○のコードを生成して」と依頼する。複雑なコードの自動生成、学習時間の短縮、コーディングパターンの習得が可能である。 - AIコード解説機能では、コードを選択して右クリック > 「Explain」、またはAIパネルで質問する。理解困難なコードの詳細解説、学習効果の向上が可能である。
- AIバグ修正支援機能では、エラー箇所を選択してAIパネルで「このエラーを修正して」と依頼する。デバッグ時間の短縮、エラー原因の理解促進が可能である。
開発支援機能
- インテリセンス(自動補完)機能では、コード入力中に自動的に候補が表示され、Tabキーで選択する。タイプミス防止、開発効率の向上、関数名や変数名の正確な入力が可能である。
- 統合ターミナル機能では、「View」メニュー > 「Terminal」、または
Ctrl + `キーで起動する。エディタを離れることなくコマンド実行、ライブラリインストールが可能である。 - ファイルエクスプローラー機能では、左側のサイドバーで自動表示され、フォルダやファイルをクリックで選択する。複数ファイルの効率的な管理、プロジェクト全体の把握が可能である。
- デバッガー機能では、ブレークポイント設定でライン番号をクリックし、
F5キーでデバッグ開始する。実行時の変数値確認、ステップ実行による詳細な動作解析が可能である。 - 問題検出機能では、Problemsパネルで自動表示される警告やエラーを確認する。コンパイル前のエラー検出、コード品質の向上が可能である。