XGBoost機械学習体験
【概要】XGBoostによるIrisデータセットの分類。決定木の数を変更して予測精度の変化を観察。機械学習の弱学習器組み合わせ概念を体験する。
目次
概要
機械学習基礎概念:機械学習では、過学習(モデルが訓練データに過度に適合し、新しいデータで性能が低下する現象)を防ぐため、正則化(モデルの複雑さに対するペナルティ)を導入する。アンサンブル学習(複数の学習器を組み合わせる手法)により、単一モデルより高い予測精度を実現する。
主要技術:XGBoost(Extreme Gradient Boosting)は、勾配ブースティング決定木(複数の弱い決定木を順次組み合わせる手法)の拡張アルゴリズムである。従来手法からの主な改良点は、正則化による過学習抑制、二次近似による高速化、列サンプリングによる精度向上である。
論文:Chen, T., & Guestrin, C. (2016). XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining (pp. 785-794).
応用例:金融リスク評価、医療診断支援、マーケティング顧客分析、画像認識の後処理分類器
学習目標:決定木の数を変更することで予測精度の変化を観察し、アンサンブル学習の概念を理解する。Irisデータセットの花弁データを用いた3クラス分類により、分類境界の形成過程を体験する。
Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
インストール済みの場合は実行不要。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent --accept-source-agreements --accept-package-agreements
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】
Python の公式ページ: https://www.python.org/
AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AI エディタの利用を推奨する。ここでは,Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行して、Windsurfをシステム全体にインストールする。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
winget install --scope machine --id Codeium.Windsurf -e --silent --accept-source-agreements --accept-package-agreements【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
必要なライブラリのインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」を選択)し、以下を実行する。
pip install xgboost scikit-learn matplotlib japanize-matplotlib numpy
プログラムコード
概要
このプログラムは、XGBoostアルゴリズムを使用してIrisデータセット(アヤメの品種データ)の分類を行う。Irisデータセットに含まれる3種類のアヤメ(setosa、versicolor、virginica)を、花弁の長さと幅を主要な特徴量として自動分類する。プログラム内でモデルの学習から評価、結果の可視化までを一貫して実行する。
主要技術
XGBoost(eXtreme Gradient Boosting)
XGBoostは、Chen and Guestrinによって2016年に発表された勾配ブースティング決定木アルゴリズムである[1]。このアルゴリズムは、複数の弱学習器(決定木)を逐次的に学習させる手法を採用している。各決定木は前の木の予測誤差に着目して学習を行い、最終的な予測は全ての木の出力を統合して生成される。正則化項の導入により過学習を抑制し、並列処理による計算効率の向上を実現している[1]。
技術的特徴
- 過学習防止機構:max_depth=2という浅い決定木を使用することで、モデルの複雑度を制限し、過学習を防止する
- 再現性の確保:random_seed=42を固定することで、実行ごとに同一の結果を得られるようにしている
- パラメータ調整機能:n_estimators(ブースティング木の数)を対話的に設定可能とし、モデルの複雑度を調整できる
- データ分割:scikit-learnのtrain_test_split関数を使用し、データの70%を訓練用、30%をテスト用に分割[2]
実装の特色
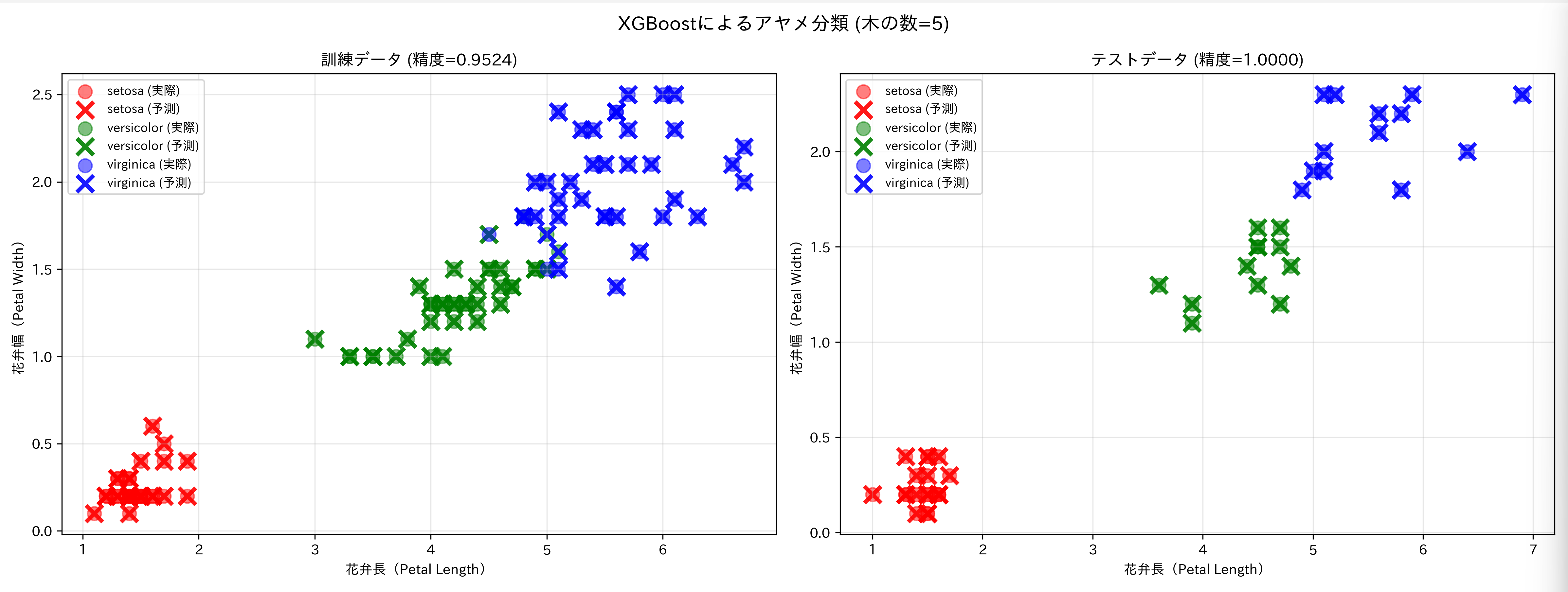
- 2画面並列可視化:matplotlibのsubplots機能を活用し、訓練データとテストデータの分類結果を左右に並べて表示する。これにより、過学習の有無を視覚的に確認できる
- 直感的な結果表示:花弁長(Petal Length)と花弁幅(Petal Width)の2次元散布図で結果を表示。実際のクラスを円形マーカー、予測結果を×マーカーで区別し、分類の成否を一目で判断可能にしている
- 色分けによる品種識別:3種類のアヤメを赤(setosa)、緑(versicolor)、青(virginica)で色分けし、視覚的な理解を促進
- 処理結果の保存:実行時刻、パラメータ設定、精度評価結果をresult.txtファイルに自動保存し、実験の記録と再現を容易にしている
性能評価
プログラムは訓練データとテストデータの両方で精度を算出し、モデルの汎化性能を評価する。scikit-learnのaccuracy_score関数を使用して分類精度を計算し[2]、結果を数値と視覚的表現の両方で提示する。典型的な実行では、適切なn_estimatorsの設定により90%以上の分類精度を達成する。
参考文献
[1] Chen, T., & Guestrin, C. (2016). XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 785-794). ACM. https://doi.org/10.1145/2939672.2939785
[2] Pedregosa, F., et al. (2011). Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research, 12, 2825-2830. https://jmlr.org/papers/v12/pedregosa11a.html
ソースコード
# プログラム名: XGBoostによるIrisデータセット分類
# 特徴技術名: XGBoost(eXtreme Gradient Boosting)
# 出典: Chen, T., & Guestrin, C. (2016). XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 785-794). ACM.
# 特徴機能: 勾配ブースティング決定木による分類。前の木の予測誤差を次の木で修正する逐次学習により、単一の決定木より高い予測精度を実現
# 学習済みモデル: なし(プログラム内でIrisデータセットを用いて学習)
# 方式設計:
# - 関連利用技術: scikit-learn(データセット読み込み、データ分割、評価指標)、matplotlib(結果可視化)、japanize-matplotlib(日本語表示)、numpy(数値計算)
# - 入力と出力: 入力: なし(内蔵データセット使用)、出力: 分類結果の可視化グラフとテキスト
# - 処理手順: 1)Irisデータセット読み込み、2)訓練・テストデータ分割、3)XGBoostモデル学習、4)テストデータで予測、5)精度評価、6)結果可視化
# - 前処理、後処理: 前処理: train_test_splitによるデータ分割(過学習防止)、後処理: 花弁長・幅による2次元可視化(理解しやすさ向上)
# - 追加処理: ブースティング木の概念説明表示(教育効果向上)、図の読み方説明表示(結果解釈支援)
# - 調整を必要とする設定値: n_estimators(ブースティング木の数、デフォルト5、範囲1-100推奨)
# 将来方策: グリッドサーチによる最適n_estimators自動探索機能の実装(交差検証による精度最大化)
# その他の重要事項: max_depth=2で浅い木を使用(過学習防止)、random_seed固定で再現性確保
# 前準備: pip install xgboost scikit-learn matplotlib japanize-matplotlib numpy
import matplotlib.pyplot as plt
import japanize_matplotlib
import numpy as np
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
import time
# 定数定義
RANDOM_SEED = 42
DEFAULT_N_ESTIMATORS = 5
TEST_SIZE = 0.3
MAX_DEPTH = 2
# 可視化用定数
COLORS = ['red', 'green', 'blue']
TARGET_NAMES = ['setosa', 'versicolor', 'virginica']
# プログラム開始時の概要表示
print('=' * 60)
print('XGBoostによるIrisデータセット分類プログラム')
print('=' * 60)
print('概要: XGBoostを使用してアヤメの品種を分類します')
print('特徴: 勾配ブースティング決定木による分類')
print('入力: Irisデータセット(プログラム内蔵)')
print('出力: 分類結果の可視化と精度評価')
print('=' * 60)
# 結果記録用リスト
results = []
print('\n【ブースティング木とは】')
print('複数の弱い決定木を順次学習し、前の木の誤りを次の木で修正する手法')
print('・各木は前の木の予測誤差に注目して学習')
print('・最終予測は全ての木の予測を重み付き平均で統合')
print('・単一の木より高精度、過学習しにくい特性')
print('=' * 60)
# パラメータ設定
inp = input(f'\nn_estimators(ブースティング木の数、デフォルト{DEFAULT_N_ESTIMATORS})を入力してください: ')
if inp.strip() and inp.strip().isdigit() and int(inp.strip()) > 0:
n_estimators = int(inp.strip())
else:
n_estimators = DEFAULT_N_ESTIMATORS
# 処理開始
start_time = time.time()
results.append(f'処理開始時刻: {time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())}')
results.append(f'設定パラメータ: n_estimators={n_estimators}')
# データ読み込み
print('\nデータ読み込み中...')
X, y = load_iris(return_X_y=True)
results.append(f'データサイズ: {X.shape[0]}サンプル, {X.shape[1]}特徴量')
time.sleep(1)
# データ分割
print('データ分割中...')
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=TEST_SIZE, random_state=RANDOM_SEED)
results.append(f'訓練データ: {X_train.shape[0]}サンプル')
results.append(f'テストデータ: {X_test.shape[0]}サンプル')
time.sleep(1)
# モデル学習
print('モデル学習中...')
model = XGBClassifier(
n_estimators=n_estimators,
max_depth=MAX_DEPTH,
random_state=RANDOM_SEED
)
model.fit(X_train, y_train)
results.append('モデル学習完了')
time.sleep(1)
# 予測と評価
print('予測実行中...')
# 訓練データの予測
train_preds = model.predict(X_train)
train_accuracy = accuracy_score(y_train, train_preds)
# テストデータの予測
test_preds = model.predict(X_test)
test_accuracy = accuracy_score(y_test, test_preds)
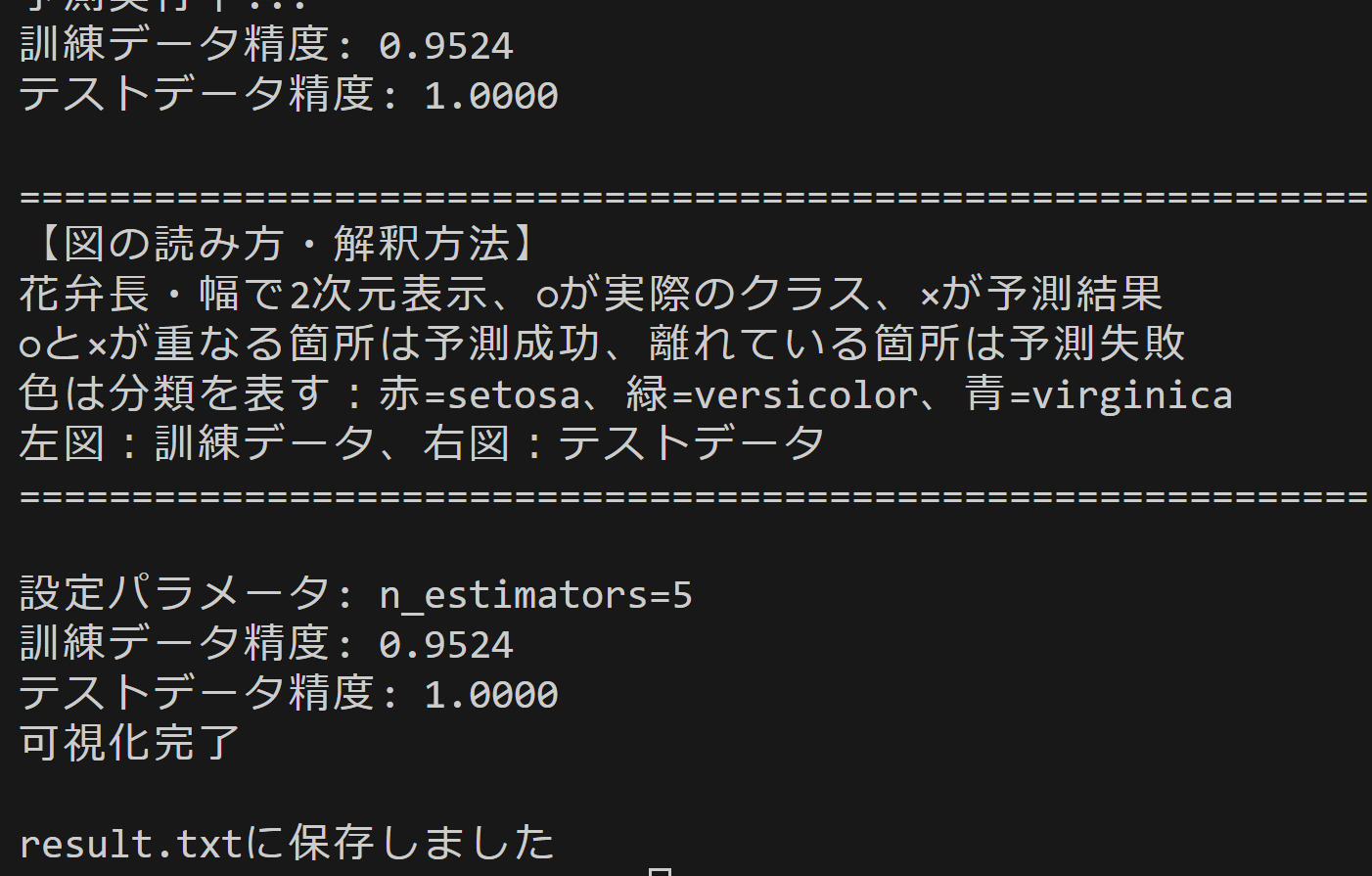
results.append(f'訓練データ精度: {train_accuracy:.4f}')
results.append(f'テストデータ精度: {test_accuracy:.4f}')
print(f'訓練データ精度: {train_accuracy:.4f}')
print(f'テストデータ精度: {test_accuracy:.4f}')
time.sleep(1)
# 処理時間計算
elapsed = time.time() - start_time
results.append(f'処理時間: {elapsed:.2f}秒')
# 結果出力
print('\n' + '=' * 60)
print('【図の読み方・解釈方法】')
print('花弁長・幅で2次元表示、○が実際のクラス、×が予測結果')
print('○と×が重なる箇所は予測成功、離れている箇所は予測失敗')
print('色は分類を表す:赤=setosa、緑=versicolor、青=virginica')
print('左図:訓練データ、右図:テストデータ')
print('=' * 60)
# 可視化(2画面表示)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 6))
# 凡例用のフラグ(重複を避けるため)
legend_actual_added = [False, False, False]
legend_pred_added = [False, False, False]
# 訓練データの可視化
ax1.set_title(f'訓練データ (精度={train_accuracy:.4f})')
for i, (color, name) in enumerate(zip(COLORS, TARGET_NAMES)):
# 実際のクラス
train_mask_actual = y_train == i
if np.any(train_mask_actual):
ax1.scatter(X_train[train_mask_actual, 2], X_train[train_mask_actual, 3],
c=color, marker='o', label=f'{name} (実際)', alpha=0.5, s=100)
legend_actual_added[i] = True
# 予測結果
train_mask_pred = train_preds == i
if np.any(train_mask_pred):
label = f'{name} (予測)' if not legend_pred_added[i] else None
ax1.scatter(X_train[train_mask_pred, 2], X_train[train_mask_pred, 3],
c=color, marker='x', label=label, s=150, linewidth=3, alpha=0.9)
legend_pred_added[i] = True
ax1.set_xlabel('花弁長(Petal Length)')
ax1.set_ylabel('花弁幅(Petal Width)')
ax1.legend(loc='upper left', fontsize=9)
ax1.grid(True, alpha=0.3)
# 凡例フラグをリセット
legend_actual_added = [False, False, False]
legend_pred_added = [False, False, False]
# テストデータの可視化
ax2.set_title(f'テストデータ (精度={test_accuracy:.4f})')
for i, (color, name) in enumerate(zip(COLORS, TARGET_NAMES)):
# 実際のクラス
test_mask_actual = y_test == i
if np.any(test_mask_actual):
ax2.scatter(X_test[test_mask_actual, 2], X_test[test_mask_actual, 3],
c=color, marker='o', label=f'{name} (実際)', alpha=0.5, s=100)
legend_actual_added[i] = True
# 予測結果
test_mask_pred = test_preds == i
if np.any(test_mask_pred):
label = f'{name} (予測)' if not legend_pred_added[i] else None
ax2.scatter(X_test[test_mask_pred, 2], X_test[test_mask_pred, 3],
c=color, marker='x', label=label, s=150, linewidth=3, alpha=0.9)
legend_pred_added[i] = True
ax2.set_xlabel('花弁長(Petal Length)')
ax2.set_ylabel('花弁幅(Petal Width)')
ax2.legend(loc='upper left', fontsize=9)
ax2.grid(True, alpha=0.3)
plt.suptitle(f'XGBoostによるアヤメ分類 (木の数={n_estimators})', fontsize=14)
plt.tight_layout()
plt.show()
# 最終結果表示
print(f'\n設定パラメータ: n_estimators={n_estimators}')
print(f'訓練データ精度: {train_accuracy:.4f}')
print(f'テストデータ精度: {test_accuracy:.4f}')
print('可視化完了')
# result.txtに保存
with open('result.txt', 'w', encoding='utf-8') as f:
for result in results:
f.write(result + '\n')
print('\nresult.txtに保存しました')
使用方法と評価
- プログラム実行
- パラメータ入力:n_estimators(ブースティング木の数)の入力を求められる。数値を入力するか、Enterキーでデフォルト値(5)を使用する。
- 結果確認:予測精度が数値で表示され、続いてグラフが表示される。
- グラフ解釈:花弁長・花弁幅の2次元プロット上で、○印が実際のクラス、×印が予測結果を示す。
評価手法と解釈:訓練データとテストデータを分離することで、モデルの汎化性能(未知データに対する予測精度)を正しく評価する。XGBoostは複雑なモデルであるが、特徴量重要度により各特徴量の予測への寄与度を把握できる。
ハイパーパラメータの調整:n_estimators(木の数)は多いほど複雑なパターンを学習するが、過学習のリスクも増加する。max_depth(木の深さ)は深いほど詳細な分岐を可能にするが、計算コストと過学習リスクが増加する。learning_rate(学習率)は小さいほど安定した学習を行うが、収束に時間を要する。
実験・探求のアイデア
基本実験
- n_estimators:1、5、10、50、100での精度変化の観察
- max_depth:1、2、3、5での分類境界の変化
- learning_rate:0.1、0.3、1.0での学習速度と精度のトレードオフ
モデル比較とデータ処理
- XGBClassifier、RandomForestClassifier(複数の決定木を並列に学習)、DecisionTreeClassifier(単一決定木)の性能比較
- 特徴量の前処理:標準化や正規化による性能への影響観察
- 特徴量重要度分析:model.feature_importances_による4つの特徴量(萼片長・幅、花弁長・幅)の重要度ランキング可視化
発展的探求
- パラメータ効果検証:n_estimatorsを1から100まで段階的に変更し、精度の飽和点を発見する。
- ハイパーパラメータ最適化:格子探索による交差検証を使用して最適なパラメータ組み合わせを自動探索し、手動調整との違いを比較する。