VideoMAE による人物動作認識(ソースコードと説明と利用ガイド)
プログラム利用ガイド
1. このプログラムの利用シーン
このツールは、人物の動作をリアルタイムで認識するためのソフトウェアである。動画ファイルやウェブカメラの映像から人物を自動検出し、16フレームの動作シーケンスを分析して動作認識を粉う。行動分析が必要な場面で活用できる。
2. 主な機能
- リアルタイム人物検出:DETRアルゴリズムによる複数人物の同時検出と主要人物の自動選択
- 動作認識:VideoMAEによる16フレームシーケンスからのTop-5動作分類
- 異常度判定:予測の不確実性と危険動作パターンを組み合わせた異常度算出
- 可視化機能:検出結果、動作認識結果、異常度をリアルタイム表示
- 結果保存:処理結果をresult.txtファイルに自動保存
3. 基本的な使い方
- 起動と入力選択:プログラム実行後、0(動画ファイル)、1(カメラ)、2(サンプル動画)から選択してEnterキーを押す
- 動画ファイル選択:0を選択した場合、ファイルダイアログで対象動画を選択する
- 処理開始:選択後、自動的に処理が開始され、映像と解析結果が表示される
- 終了方法:映像表示画面でqキーを押すとプログラムが終了する
4. 便利な機能
- 検出率表示:人物検出の成功率をリアルタイム監視
- 処理ログ:カメラ使用時は時刻付き、動画ファイル使用時はフレーム番号付きで結果を表示
- 結果ファイル出力:全処理結果をresult.txtに保存し、後から詳細分析が可能
Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
インストール済みの場合は実行不要。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent --accept-source-agreements --accept-package-agreements
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】
Python の公式ページ: https://www.python.org/
AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AI エディタの利用を推奨する。ここでは,Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行して、Windsurfをシステム全体にインストールする。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
winget install --scope machine --id Codeium.Windsurf -e --silent --accept-source-agreements --accept-package-agreements【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
必要なライブラリをシステム領域にインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する
pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
pip install transformers pillow opencv-python numpy matplotlib
人物動作認識プログラム(VideoMAE + DETR統合版)
概要
このプログラムは、VideoMAEとDETRを組み合わせた人物動作認識システムである。動画またはカメラ映像から人物を検出し、16フレームシーケンスの動作認識を行う。そして,危険動作や予測の不確実性に基づいて異常度を算出する。
主要技術
VideoMAE(Video Masked Autoencoders)
2022年に提案された動画理解のための自己教師あり学習手法[1]。90%~95%の極めて高いマスキング比率による動画チューブマスキング戦略を用い、時間的冗長性を活用して動画表現学習を実現する。
DETR(Detection Transformer)
2020年に提案されたTransformerベースのエンドツーエンド物体検出手法[2]。従来の物体検出で必要だったアンカーボックス生成やNon-Maximum Suppressionを不要とし、集合予測問題として物体検出を定式化する。
実装の特色
- 複数人物検出時の信頼度と面積による主要人物選択アルゴリズム
- リアルタイム可視化とファイル出力機能
参考文献
[1] Tong, Z., Song, Y., Wang, J., & Wang, L. (2022). VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training. Advances in Neural Information Processing Systems, 35. https://arxiv.org/abs/2203.12602
[2] Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., & Zagoruyko, S. (2020). End-to-End Object Detection with Transformers. In European Conference on Computer Vision (ECCV 2020), 213-229. https://arxiv.org/abs/2005.12872
[3] Wang, L., Huang, B., Zhao, Z., Tong, Z., He, Y., Wang, Y., Wang, Y., & Qiao, Y. (2023). VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2023). https://arxiv.org/abs/2303.16727
ソースコード
"""
人物動作認識プログラム(VideoMAE + RT-DETRv2)
特徴技術名: VideoMAE(Video Masked Autoencoders)+ RT-DETRv2(Real-Time Detection Transformer v2)
出典: Tong, Z., Song, Y., Wang, J., & Wang, L. (2022). VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training. arXiv preprint arXiv:2203.12602.
特徴機能: 高いマスキング比率(90%~95%)による動画チューブマスキング戦略を用いた自己教師あり学習による動画理解。時間的冗長性を活用し、従来の画像ベース手法より高いマスキング比率を目指す。
学習済みモデル:
- VideoMAE: MCG-NJU/videomae-base-finetuned-kinetics(Kinetics-400データセットで事前学習済み、16フレームシーケンス対応)
- RT-DETRv2: PekingU/rtdetr_v2_r50vd(COCO 2017データセットで学習済み、ResNet-50バックボーン、人物検出用)
- URL: https://huggingface.co/MCG-NJU/videomae-base-finetuned-kinetics、https://huggingface.co/PekingU/rtdetr_v2_r50vd
特徴技術および学習済みモデルの利用制限: **学術研究目的での利用を推奨。商用利用の場合は各モデルのライセンス(Apache 2.0等)を確認のこと。必ず利用者自身で利用制限を確認すること。**
方式設計:
関連利用技術:
- RT-DETRv2(Real-Time Detection Transformer v2): 改良されたTransformerベースエンドツーエンド物体検出、NMS不要、高速・高精度を両立
- OpenCV: リアルタイム映像処理、カメラ入力、画像前処理
- PyTorch: 深層学習フレームワーク、GPU加速処理
- Transformers Library: Hugging Face製、事前学習済みモデルの統一インターフェース
入力と出力: 入力: 動画(ユーザは「0:動画ファイル,1:カメラ,2:サンプル動画」のメニューで選択.0:動画ファイルの場合はtkinterでファイル選択.1の場合はOpenCVでカメラが開く.2の場合はhttps://raw.githubusercontent.com/opencv/opencv/master/samples/data/vtest.aviを使用)、出力: 動作認識結果、処理結果のテキストファイル保存
処理手順:
1. RT-DETRv2 による人物検出(複数人物対応、面積と信頼度による主要人物選択)
2. 人物領域のクロップと16フレームシーケンス蓄積
3. VideoMAE による動作認識(Top-5予測結果出力)
4. 予測確率分布と危険動作検出による異常度算出
5. リアルタイム可視化と結果出力
前処理、後処理:
- 前処理: 人物領域の動的クロップ、224×224リサイズ、BGR→RGB変換、PIL Image変換
- 後処理: Top-5動作認識結果の確率分析、不確実性と危険動作の統合による異常度計算
追加処理:
- 複数人物検出時の主要人物選択(信頼度0.7×面積0.3の重み付けスコア)
- 検出失敗時のフルフレームフォールバック機能
- 連続検出失敗カウントによる適応的処理切替
- フレーム補完機能(無効フレーム時の最後有効フレーム再利用)
調整を必要とする設定値:
- PERSON_CONFIDENCE_THRESHOLD(人物検出信頼度閾値、デフォルト0.7)
- MIN_PERSON_SIZE(最小人物サイズピクセル、デフォルト20)
- SEQUENCE_LENGTH(動作認識用フレーム数、デフォルト16)
将来方策: PERSON_CONFIDENCE_THRESHOLD自動調整機能(環境光量や被写体サイズに基づく動的閾値設定、検出成功率のリアルタイム監視による自動最適化)
その他の重要事項:
- GPU使用推奨(CUDA対応)
- リアルタイム処理のため数フレームごとに人物検出実行(skip_frames=3)
- カメラ解像度640x480固定
前準備:
pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
pip install transformers pillow opencv-python numpy matplotlib
"""
import cv2
import torch
import numpy as np
from transformers import VideoMAEImageProcessor, VideoMAEForVideoClassification
from transformers import RTDetrImageProcessor, RTDetrV2ForObjectDetection
from collections import defaultdict, deque
import warnings
from PIL import Image, ImageFont, ImageDraw
import tkinter as tk
from tkinter import filedialog
import urllib.request
import os
import time
from datetime import datetime
warnings.filterwarnings("ignore")
# GPU/CPU自動選択
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'デバイス: {str(device)}')
# GPU使用時の最適化
if device.type == 'cuda':
torch.backends.cudnn.benchmark = True
# VideoMAEモデル読み込み
model_name = "MCG-NJU/videomae-base-finetuned-kinetics"
print("Loading VideoMAE model...")
try:
image_processor = VideoMAEImageProcessor.from_pretrained(model_name)
model = VideoMAEForVideoClassification.from_pretrained(model_name).to(device)
model.eval()
print("VideoMAE model loaded successfully")
except Exception as e:
print(f"Failed to load VideoMAE model: {e}")
exit(1)
# RT-DETRv2人物検出モデル読み込み
detr_model_name = "PekingU/rtdetr_v2_r50vd"
print("Loading RT-DETRv2 model...")
try:
detr_processor = RTDetrImageProcessor.from_pretrained(detr_model_name)
detr_model = RTDetrV2ForObjectDetection.from_pretrained(detr_model_name).to(device)
detr_model.eval()
print("RT-DETRv2 model loaded successfully")
except Exception as e:
print(f"Failed to load RT-DETRv2 model: {e}")
exit(1)
# VideoMAEモデル設定の動的取得
try:
MODEL_NUM_FRAMES = getattr(model.config, "num_frames", 16)
print(f'VideoMAEモデル設定のフレーム数: {MODEL_NUM_FRAMES}')
if MODEL_NUM_FRAMES != 16:
print(f'警告: モデルのフレーム数が16ではありません ({MODEL_NUM_FRAMES}フレーム)')
print('このプログラムは16フレーム用に最適化されています')
SEQUENCE_LENGTH = MODEL_NUM_FRAMES
except Exception as e:
print(f'モデル設定取得エラー: {e}')
print('デフォルトの16フレームを使用します')
SEQUENCE_LENGTH = 16
# パラメータ
# 設定値の明示化
PERSON_CONFIDENCE_THRESHOLD = 0.7 # 人物検出信頼度閾値
MIN_PERSON_SIZE = 20 # 最小人物サイズ(ピクセル)
PERSON_CLASS_ID = 0 # COCOデータセットにおけるPersonクラスのID(RT-DETRv2)
PERSON_TRACKING_THRESHOLD = 100 # 人物追跡のための距離閾値(ピクセル)
print(f"設定フレーム数: {SEQUENCE_LENGTH}")
# フレームバッファの初期化(複数人物対応)
# バッファ管理
frame_count = 0
results_log = []
person_frame_buffers = defaultdict(lambda: deque(maxlen=SEQUENCE_LENGTH))
person_action_states = defaultdict(lambda: {'current_action': None, 'action_start_time': None})
previous_persons = []
next_person_id = 0
def preprocess_person_frame(cropped_frame):
"""人物フレームの前処理(リサイズ→色変換→PIL変換)"""
try:
resized_frame = cv2.resize(cropped_frame, (224, 224))
rgb_frame = cv2.cvtColor(resized_frame, cv2.COLOR_BGR2RGB)
rgb_frame = rgb_frame.astype(np.uint8)
return Image.fromarray(rgb_frame)
except Exception as e:
print(f"フレーム前処理エラー: {e}")
return None
def draw_person_info(frame, person_id, bbox, confidence, action_result=None, buffer_status=None):
"""人物情報の統一描画処理"""
x1, y1, x2, y2 = bbox
# バウンディングボックス描画
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
# Person ID と信頼度表示
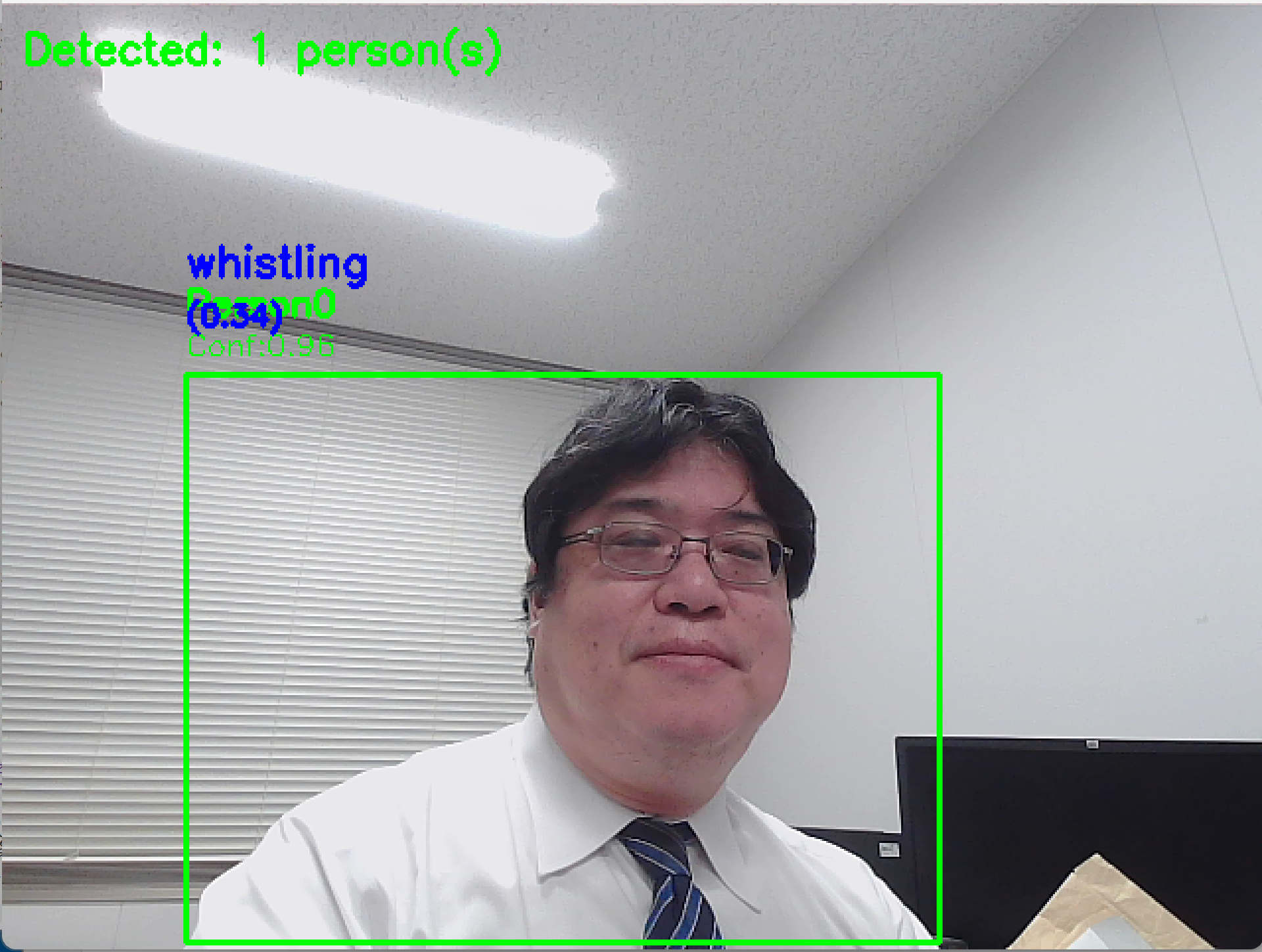
cv2.putText(frame, f"Person{person_id}", (x1, y1-30), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
cv2.putText(frame, f"Conf:{confidence:.2f}", (x1, y1-10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 1)
if action_result:
# 動作認識結果を画面に表示
top1_text = f"{action_result['top1_action']}"
conf_text = f"({action_result['top1_confidence']:.2f})"
cv2.putText(frame, top1_text, (x1, y1-50), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 0, 0), 2)
cv2.putText(frame, conf_text, (x1, y1-25), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 2)
elif buffer_status:
# フレーム蓄積中表示
cv2.putText(frame, buffer_status, (x1, y1-25), cv2.FONT_HERSHEY_SIMPLEX, 0.4, (255, 255, 255), 1)
def safe_model_operation(operation_name, operation_func, *args, **kwargs):
"""統一エラーハンドリング付きモデル操作"""
try:
return operation_func(*args, **kwargs)
except Exception as e:
print(f"{operation_name}エラー: {e}")
return None
def calculate_person_distance(person1, person2):
"""2つの人物間の中心点距離を計算"""
# person1とperson2のbboxから中心点を計算
x1_center = (person1['bbox'][0] + person1['bbox'][2]) / 2
y1_center = (person1['bbox'][1] + person1['bbox'][3]) / 2
x2_center = (person2['bbox'][0] + person2['bbox'][2]) / 2
y2_center = (person2['bbox'][1] + person2['bbox'][3]) / 2
# ユークリッド距離
distance = np.sqrt((x1_center - x2_center)**2 + (y1_center - y2_center)**2)
# サイズ変化も考慮
area1 = (person1['bbox'][2] - person1['bbox'][0]) * (person1['bbox'][3] - person1['bbox'][1])
area2 = (person2['bbox'][2] - person2['bbox'][0]) * (person2['bbox'][3] - person2['bbox'][1])
size_ratio = abs(area1 - area2) / max(area1, area2)
# サイズ変化が大きすぎる場合は距離にペナルティ
if size_ratio > 0.5: # 50%以上のサイズ変化
distance *= (1 + size_ratio)
return distance
def assign_person_ids(detected_persons):
"""人物IDの割り当て(簡易追跡機能付き)"""
global previous_persons, next_person_id
if not previous_persons:
# 初回検出時
for i, person in enumerate(detected_persons):
person['person_id'] = next_person_id
next_person_id += 1
else:
# 前フレームとの対応付け
assigned_ids = set()
for person in detected_persons:
best_match_id = None
min_distance = float('inf')
# 前フレームの各人物との距離を計算
for prev_person in previous_persons:
if prev_person['person_id'] not in assigned_ids:
distance = calculate_person_distance(person, prev_person)
if distance < PERSON_TRACKING_THRESHOLD and distance < min_distance:
min_distance = distance
best_match_id = prev_person['person_id']
if best_match_id is not None:
person['person_id'] = best_match_id
assigned_ids.add(best_match_id)
else:
# 新しい人物
person['person_id'] = next_person_id
next_person_id += 1
previous_persons = detected_persons.copy()
return detected_persons
def video_frame_processing(frame):
global frame_count
current_time = time.time()
frame_count += 1
# RT-DETRv2による人物検出
detected_persons = detect_persons_detr(frame)
# 人物検出結果の表示
result_texts = []
action_results = []
if not detected_persons:
# 人物検出失敗時
result_texts.append(f"フレーム{frame_count}: 人物検出なし")
cv2.putText(frame, "No Person Detected", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
else:
# 各人物の処理
for person in detected_persons:
person_id = person['person_id']
x1, y1, x2, y2 = person['bbox']
# 人物領域をクロップ
padding = 20
h, w = frame.shape[:2]
crop_x1 = max(0, x1 - padding)
crop_y1 = max(0, y1 - padding)
crop_x2 = min(w, x2 + padding)
crop_y2 = min(h, y2 + padding)
cropped_person = frame[crop_y1:crop_y2, crop_x1:crop_x2]
if cropped_person.shape[0] > 0 and cropped_person.shape[1] > 0:
# 人物別フレームバッファに追加
pil_frame = preprocess_person_frame(cropped_person)
if pil_frame:
person_frame_buffers[person_id].append(pil_frame)
current_buffer_size = len(person_frame_buffers[person_id])
# フレーム数蓄積後に動作認識実行
if current_buffer_size == SEQUENCE_LENGTH:
person_frames = list(person_frame_buffers[person_id])
action_result = recognize_action_for_person(person_frames, person_id, current_time)
if action_result:
action_results.append(action_result)
result_texts.append(action_result['result_text'])
# 人物情報描画(動作認識結果付き)
draw_person_info(frame, person_id, (x1, y1, x2, y2), person['confidence'], action_result)
else:
# 人物情報描画(バッファ状況付き)
buffer_text = f"Loading {current_buffer_size}/{SEQUENCE_LENGTH}"
draw_person_info(frame, person_id, (x1, y1, x2, y2), person['confidence'],
buffer_status=buffer_text)
buffer_status = f"Person{person_id}: {current_buffer_size}/{SEQUENCE_LENGTH}フレーム蓄積中"
result_texts.append(buffer_status)
# 全体の検出状況表示
cv2.putText(frame, f"Detected: {len(detected_persons)} person(s)",
(10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
# 結果文字列の結合
if result_texts:
combined_result = " | ".join(result_texts)
else:
combined_result = f"フレーム{frame_count}: 処理中"
return frame, combined_result, current_time
def recognize_action_for_person(person_frames, person_id, current_time):
"""個別人物の動作認識"""
return safe_model_operation(
f"Person{person_id}動作認識",
_perform_action_recognition,
person_frames, person_id, current_time
)
def _perform_action_recognition(person_frames, person_id, current_time):
"""動作認識の実際の処理"""
# 前処理
inputs = image_processor(person_frames, return_tensors="pt")
inputs = {k: v.to(device) for k, v in inputs.items()}
# 推論実行
with torch.no_grad():
outputs = model(**inputs)
probabilities = torch.nn.functional.softmax(outputs.logits, dim=-1)
# 上位5クラス取得
top5_prob, top5_indices = torch.topk(probabilities, 5)
# 結果整形
top5_predictions = []
for i in range(5):
class_idx = top5_indices[0][i].item()
confidence = top5_prob[0][i].item()
class_name = model.config.id2label[class_idx]
top5_predictions.append((class_name, confidence))
# Top-1動作取得
top1_action, top1_confidence = top5_predictions[0]
# 動作継続時間管理
person_state = person_action_states[person_id]
if person_state['current_action'] != top1_action:
person_state['current_action'] = top1_action
person_state['action_start_time'] = current_time
duration = 0.0
else:
duration = current_time - person_state['action_start_time'] if person_state['action_start_time'] else 0.0
# 結果文字列作成
predicted_actions = [f"{name}({conf:.3f})" for name, conf in top5_predictions]
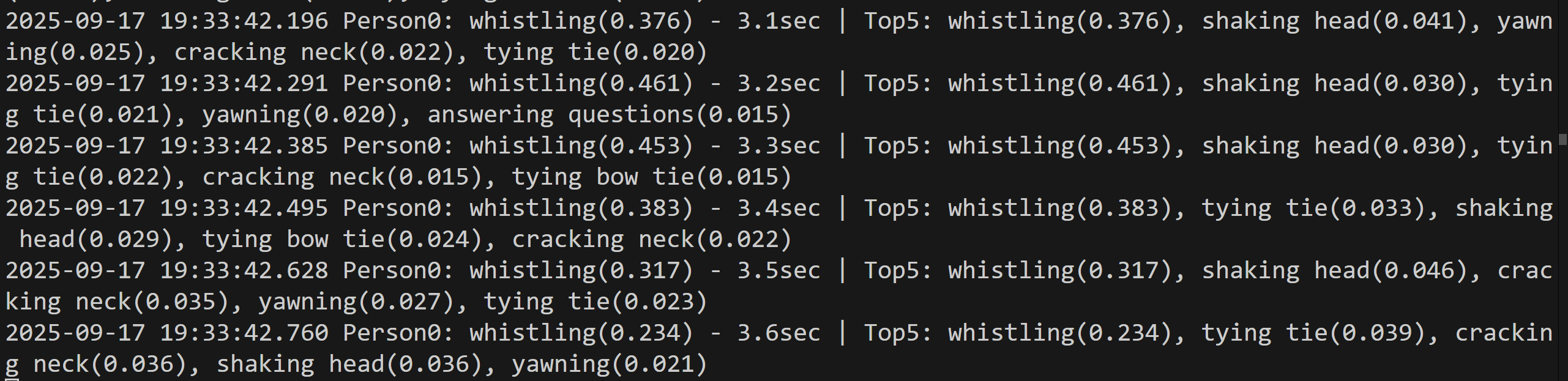
result = f"Person{person_id}: {top1_action}({top1_confidence:.3f}) - {duration:.1f}sec | Top5: {', '.join(predicted_actions)}"
return {
'person_id': person_id,
'top1_action': top1_action,
'top1_confidence': top1_confidence,
'duration': duration,
'top5_predictions': top5_predictions,
'result_text': result
}
def draw_text(frame, text, position, font_scale=0.5, color=(255, 255, 255), thickness=1):
"""統一的なテキスト描画処理"""
cv2.putText(frame, text, position,
cv2.FONT_HERSHEY_SIMPLEX, font_scale, color, thickness)
def detect_persons_detr(frame):
"""RT-DETRv2 による人物検出(複数人物対応)"""
def _detect_persons():
rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
pil_image = Image.fromarray(rgb_frame)
inputs = detr_processor(images=pil_image, return_tensors="pt")
inputs = {k: v.to(device) for k, v in inputs.items()}
with torch.no_grad():
outputs = detr_model(**inputs)
# RT-DETRv2用のtarget_sizes設定
h, w = frame.shape[:2]
target_sizes = torch.tensor([[h, w]], dtype=torch.float32).to(device)
results = detr_processor.post_process_object_detection(
outputs, target_sizes=target_sizes, threshold=PERSON_CONFIDENCE_THRESHOLD
)[0]
persons = []
if len(results['labels']) > 0:
boxes = results['boxes'].cpu().numpy()
scores = results['scores'].cpu().numpy()
labels = results['labels'].cpu().numpy()
# Personクラスのみフィルタリング
person_indices = labels == PERSON_CLASS_ID
if np.any(person_indices):
person_boxes = boxes[person_indices]
person_scores = scores[person_indices]
# 信頼度でソート(降順)
sorted_indices = np.argsort(person_scores)[::-1]
person_boxes = person_boxes[sorted_indices]
person_scores = person_scores[sorted_indices]
# 各人物の処理
for i, (box, score) in enumerate(zip(person_boxes, person_scores)):
x1, y1, x2, y2 = map(int, box[:4])
# 最小サイズチェック
if (x2 - x1) >= MIN_PERSON_SIZE and (y2 - y1) >= MIN_PERSON_SIZE:
persons.append({
'bbox': (x1, y1, x2, y2),
'confidence': float(score)
})
# 人物ID割り当て(追跡機能付き)
persons = assign_person_ids(persons)
return persons
return safe_model_operation("人物検出", _detect_persons) or []
def select_primary_person(person_detections):
"""複数人物から主要人物を選択(面積と信頼度の組み合わせ)"""
if not person_detections:
return None
max_area = max(p['area'] for p in person_detections)
for person in person_detections:
normalized_area = person['area'] / max_area
person['combined_score'] = person['confidence'] * 0.7 + normalized_area * 0.3
best_person = max(person_detections, key=lambda x: x['combined_score'])
return best_person
def calculate_anomaly_from_predictions(top5_results):
"""Top-5結果から異常度を判定する最善ルール"""
top1_class, top1_prob = top5_results[0]
uncertainty_score = (1 - top1_prob) * 100
dangerous_actions = ["falling", "fighting", "punching", "kicking", "wrestling",
"sword fighting", "fencing", "slapping", "headbanging"]
danger_bonus = 50 if any(action in top1_class.lower() for action in dangerous_actions) else 0
probs = [result[1] for result in top5_results]
prob_variance = np.var(probs)
anomaly_score = uncertainty_score + danger_bonus + prob_variance
return anomaly_score
print("0: 動画ファイル")
print("1: カメラ")
print("2: サンプル動画")
choice = input("選択: ")
if choice == '0':
root = tk.Tk()
root.withdraw()
path = filedialog.askopenfilename()
if not path:
exit()
cap = cv2.VideoCapture(path)
elif choice == '1':
cap = cv2.VideoCapture(0, cv2.CAP_DSHOW)
if not cap.isOpened():
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
else:
SAMPLE_URL = 'https://raw.githubusercontent.com/opencv/opencv/master/samples/data/vtest.avi'
SAMPLE_FILE = 'vtest.avi'
urllib.request.urlretrieve(SAMPLE_URL, SAMPLE_FILE)
cap = cv2.VideoCapture(SAMPLE_FILE)
if not cap.isOpened():
print('動画ファイル・カメラを開けませんでした')
exit()
# グローバル変数は既に上部で初期化済み
# メイン処理
print('\n=== 動画処理開始 ===')
print('操作方法:')
print(' q キー: プログラム終了')
print(f'人物検出信頼度閾値: {PERSON_CONFIDENCE_THRESHOLD}')
print(f'最小人物サイズ: {MIN_PERSON_SIZE}px')
print(f'人物追跡閾値: {PERSON_TRACKING_THRESHOLD}px')
try:
while True:
ret, frame = cap.read()
if not ret:
break
MAIN_FUNC_DESC = "VideoMAE + RT-DETRv2 複数人物動作認識システム"
processed_frame, result, current_time = video_frame_processing(frame)
cv2.imshow(MAIN_FUNC_DESC, processed_frame)
if choice == '1': # カメラの場合
print(datetime.fromtimestamp(current_time).strftime("%Y-%m-%d %H:%M:%S.%f")[:-3], result)
else: # 動画ファイルの場合
print(frame_count, result)
results_log.append(result)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
finally:
print('\n=== プログラム終了 ===')
cap.release()
cv2.destroyAllWindows()
if results_log:
with open('result.txt', 'w', encoding='utf-8') as f:
f.write('=== VideoMAE + RT-DETRv2 複数人物動作認識結果 ===\n')
f.write(f'処理フレーム数: {frame_count}\n')
f.write(f'設定フレーム数: {SEQUENCE_LENGTH}\n')
f.write(f'人物検出閾値: {PERSON_CONFIDENCE_THRESHOLD}\n')
f.write(f'人物追跡閾値: {PERSON_TRACKING_THRESHOLD}px\n')
f.write(f'使用デバイス: {str(device).upper()}\n')
if device.type == 'cuda':
f.write(f'GPU: {torch.cuda.get_device_name(0)}\n')
f.write('\n')
f.write('\n'.join(results_log))
print(f'\n処理結果をresult.txtに保存しました')