表形式データの次元削減・クラスタリング可視化(t-SNE + KMeans)(ソースコードと実行結果)
Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
インストール済みの場合は実行不要。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent --accept-source-agreements --accept-package-agreements
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】
Python の公式ページ: https://www.python.org/
AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AI エディタの利用を推奨する。ここでは,Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行して、Windsurfをシステム全体にインストールする。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
winget install --scope machine --id Codeium.Windsurf -e --silent --accept-source-agreements --accept-package-agreements【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
必要なライブラリをシステム領域にインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する
pip install pandas scikit-learn numpy matplotlib
表形式データの次元削減・クラスタリング可視化(t-SNE + KMeans)
ソースコード
# プログラム名: 表形式データの次元削減・クラスタリング可視化(t-SNE + KMeans)
# 特徴技術名: t-Distributed Stochastic Neighbor Embedding(t-SNE, scikit-learn実装)
# 出典(APA形式):
# • van der Maaten, L., & Hinton, G. (2008). Visualizing data using t-SNE. Journal of Machine Learning Research, 9, 2579–2605. https://www.jmlr.org/papers/v9/vandermaaten08a.html
# 特徴機能:
# • 局所的近傍構造の保存に基づく低次元可視化(2次元散布図)
# • t-SNE座標空間でのクラスタリングによる自然なクラスタ発見
# 学習済みモデル:
# • なし(教師なし学習のみ)
# 方式設計
# • 関連利用技術
# - pandas: CSV読み込みと前処理
# - scikit-learn: StandardScaler, TSNE, KMeans, NearestNeighbors
# - numpy: 数値演算
# - matplotlib: 可視化
# - tkinter: CSVファイル選択
# - urllib: サンプルTitanicのダウンロード
# • 入力と出力
# 入力: 表形式データ(ユーザは「0:CSVファイル,1:サンプルTitanic」のメニューで選択.0の場合はtkinterでファイル選択.1の場合はhttps://raw.githubusercontent.com/mwaskom/seaborn-data/master/titanic.csvを使用)
# 出力:
# - t-SNEの2次元散布図(クラスタID色分け + 密度ベース色分けの2画面表示)
# - コンソールに処理情報とクラスタ割当て要約
# - クラスタ特性分析(元データ属性との関係表示)
# - プログラム終了時にコンソール出力をresult.txtに保存し、保存完了をprintで通知
# • 処理手順
# 1) CSV読み込み 2) 欠損・カテゴリ処理と標準化 3) t-SNEで2次元埋め込み 4) t-SNE座標でKMeansクラスタID付与 5) 可視化と保存
# • 前処理、後処理
# - 前処理: 欠損補完(数値=中央値、非数値='missing')、one-hot、定数列除去、高カーディナリティ列除去、標準化
# - 後処理: 双方向散布図表示(クラスタID + 密度ベース色付け)
# • 追加処理
# - 定数列の自動除去(数値安定性)
# - 高カーディナリティ列の自動除去(クラスタリングに寄与しない列の除外、閾値0.8)
# - 密度ベース可視化(各点の近傍点密度による色付け)
# • 調整を必要とする設定値
# - n_clusters(KMeansのクラスタ数、t-SNE座標に適用、未入力時3)
# - perplexity(t-SNEの近傍幅、サンプル数より小さく自動補正)
# - n_iter(t-SNE反復、既定1000)
# • 算出・計算処理の検証
# - エンコード後の形状(N,D)、t-SNE出力形状(N,2)、KMeansの割当て数合計=Nを表示
# 将来方策
# • エルボー法・シルエット係数の提示、複数perplexityの比較表示、UMAP対応
# その他の重要事項
# • t-SNEは計算負荷が高い。perplexityはサンプル数より小さく設定
# • クラスタリングはt-SNE座標で実行するため、元データとの解釈に注意
# 前準備:
# pip install pandas scikit-learn numpy matplotlib
import os
import sys
import urllib.request
from datetime import datetime
import tkinter as tk
from tkinter import filedialog
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
RESULT_LOG = []
def log_print(msg):
print(msg)
RESULT_LOG.append(str(msg))
def step_banner(step_name):
line = f'=== {step_name} ==='
print(line)
RESULT_LOG.append(line)
def download_sample_titanic(dest_path):
url = 'https://raw.githubusercontent.com/mwaskom/seaborn-data/master/titanic.csv'
try:
urllib.request.urlretrieve(url, dest_path)
return dest_path
except Exception as e:
log_print('サンプルデータのダウンロードに失敗しました')
log_print(str(e))
sys.exit(1)
def read_csv_with_fallback(path):
for enc in ['utf-8-sig', 'cp932', 'utf-8']:
try:
df = pd.read_csv(path, encoding=enc)
return df
except UnicodeDecodeError:
continue
except FileNotFoundError as e:
log_print('CSVファイルを開けませんでした')
log_print(str(e))
sys.exit(1)
except Exception as e:
log_print('CSVファイルの読み込みに失敗しました')
log_print(str(e))
sys.exit(1)
log_print('CSVファイルの文字コード判定に失敗しました')
sys.exit(1)
def preprocess_dataframe(df):
df = df.copy()
n0 = len(df)
df = df.dropna(how='all')
dropped_rows = n0 - len(df)
df = df.replace([np.inf, -np.inf], np.nan)
num_cols = df.select_dtypes(include=[np.number]).columns.tolist()
cat_cols = [c for c in df.columns if c not in num_cols]
if num_cols:
df_num = df[num_cols].copy()
for c in num_cols:
med = df_num[c].median()
df_num[c] = df_num[c].fillna(med)
else:
df_num = pd.DataFrame(index=df.index)
# 高カーディナリティ列の除外処理
excluded_high_card_cols = []
if cat_cols:
df_cat = df[cat_cols].copy()
for c in cat_cols:
df_cat[c] = df_cat[c].astype('string', errors='ignore').astype(str)
df_cat[c] = df_cat[c].replace({'nan': 'missing'})
df_cat[c] = df_cat[c].fillna('missing')
# 高カーディナリティ列の検出
high_card_threshold = 0.8
filtered_cat_cols = []
for c in cat_cols:
unique_count = df_cat[c].nunique()
cardinality_ratio = unique_count / len(df_cat)
if cardinality_ratio > high_card_threshold:
excluded_high_card_cols.append(c)
log_print(f'高カーディナリティ列を除外: {c} ({unique_count}/{len(df_cat)} = {cardinality_ratio:.1%})')
else:
filtered_cat_cols.append(c)
if filtered_cat_cols:
df_cat_filtered = df_cat[filtered_cat_cols]
df_cat_enc = pd.get_dummies(df_cat_filtered, drop_first=False)
else:
df_cat_enc = pd.DataFrame(index=df.index)
else:
df_cat_enc = pd.DataFrame(index=df.index)
X_df = pd.concat([df_num, df_cat_enc], axis=1)
nunique = X_df.nunique(dropna=False)
zero_var_cols = nunique[nunique <= 1].index.tolist()
if zero_var_cols:
X_df = X_df.drop(columns=zero_var_cols)
scaler = StandardScaler()
X = scaler.fit_transform(X_df)
info = {
'dropped_rows': dropped_rows,
'n_samples': X.shape[0],
'n_features': X.shape[1],
'num_cols': len(num_cols),
'cat_cols': len(cat_cols),
'excluded_high_card_cols': len(excluded_high_card_cols),
'removed_constant_cols': len(zero_var_cols),
}
return X, X_df.columns.tolist(), df, info
def select_perplexity(n_samples, user_text):
def auto_value(n):
if n <= 5:
return 2.0
elif n <= 30:
return 5.0
elif n <= 300:
return 30.0
else:
return 50.0
if not user_text:
p = auto_value(n_samples)
else:
try:
p = float(user_text)
except Exception:
p = auto_value(n_samples)
log_print('perplexityの入力値を解釈できませんでした。自動設定を使用します')
if p >= n_samples:
p_new = max(2.0, min(auto_value(n_samples), float(n_samples - 1)))
log_print(f'perplexity={p} はサンプル数({n_samples})以上です。{p_new} に調整します')
p = p_new
return p
def run_kmeans_tsne(X, n_clusters, perplexity, n_iter=1000):
if X.shape[0] < 2:
log_print('サンプル数が2未満のため処理を終了します')
sys.exit(1)
if n_clusters < 2 or n_clusters > X.shape[0]:
log_print(f'不正なクラスタ数です: K={n_clusters}。2〜{X.shape[0]}で指定してください')
sys.exit(1)
kmeans = KMeans(n_clusters=n_clusters, random_state=42, n_init=10)
labels = kmeans.fit_predict(X)
tsne = TSNE(
n_components=2,
perplexity=perplexity,
init='pca',
learning_rate='auto',
max_iter=n_iter,
random_state=42,
metric='euclidean',
verbose=0,
)
coords = tsne.fit_transform(X)
return labels, coords, kmeans
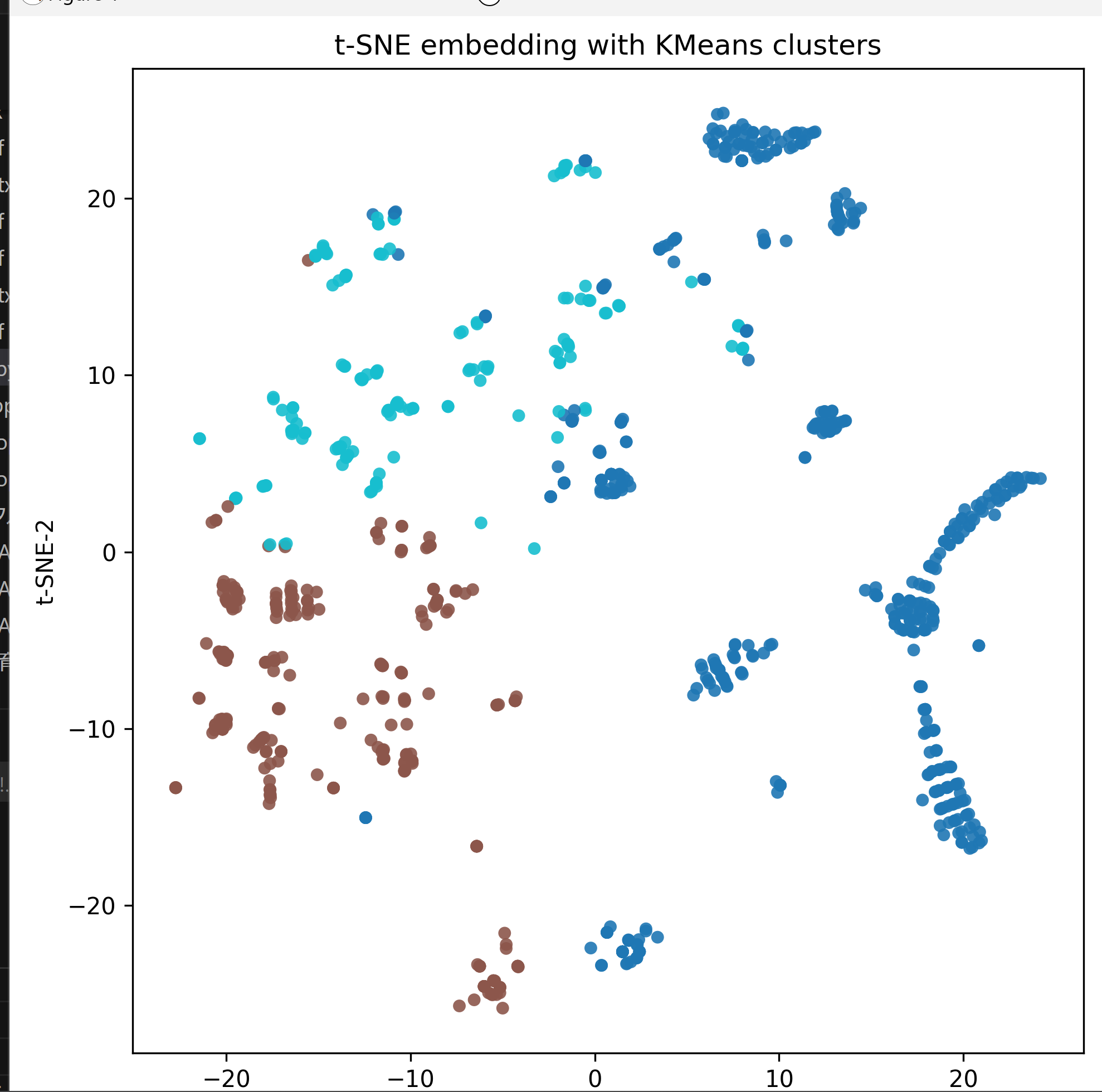
def plot_embedding(coords, labels):
fig, ax = plt.subplots(figsize=(8, 8))
sc = ax.scatter(
coords[:, 0], coords[:, 1],
c=labels, cmap='tab10' if labels.max() < 10 else 'tab20',
s=30, alpha=0.9, edgecolors='none',
)
ax.set_title('t-SNE embedding with KMeans clusters')
ax.set_xlabel('t-SNE-1')
ax.set_ylabel('t-SNE-2')
cbar = plt.colorbar(sc, ax=ax)
cbar.set_label('cluster_id')
plt.tight_layout()
plt.show()
def analyze_cluster_characteristics(df_with_clusters):
step_banner('クラスタ特性分析')
for cluster_id in sorted(df_with_clusters['cluster_id'].unique()):
cluster_data = df_with_clusters[df_with_clusters['cluster_id'] == cluster_id]
log_print(f'\n--- Cluster {cluster_id} ---')
log_print(f'要素数: {len(cluster_data)}')
# 数値列の中央値
num_cols = cluster_data.select_dtypes(include=[np.number]).columns.tolist()
if 'cluster_id' in num_cols:
num_cols.remove('cluster_id')
if num_cols:
log_print('数値列の中央値:')
for col in num_cols:
median_val = cluster_data[col].median()
log_print(f' {col}: {median_val}')
# カテゴリ列の要素カウント
cat_cols = [c for c in cluster_data.columns if c not in num_cols and c != 'cluster_id']
if cat_cols:
log_print('カテゴリ列の要素カウント:')
for col in cat_cols:
counts = cluster_data[col].value_counts()
log_print(f' {col}:')
for val, count in counts.items():
log_print(f' {val}: {count}')
step_banner('STEP_1 技術調査 結果')
log_print('特徴技術名: t-SNE(scikit-learn)')
log_print('出典: van der Maaten & Hinton (2008), JMLR')
log_print('特徴機能: 近傍構造の保存に基づく低次元可視化')
log_print('学習済みモデル: なし')
log_print('問題なし(続行)')
step_banner('プログラム開始')
log_print('本プログラムは表形式データをt-SNEで2次元に変換し、t-SNE座標でKMeansクラスタリングを実行、可視化する')
log_print('操作方法:')
log_print('0: CSVファイルを選択')
log_print('1: サンプルTitanicデータを使用')
choice = input('選択: ').strip()
if choice == '0':
root = tk.Tk()
root.withdraw()
path = filedialog.askopenfilename(
title='CSVファイルを選択',
filetypes=[('CSV Files', '*.csv'), ('All Files', '*.*')],
)
if not path:
log_print('ファイルが選択されませんでした')
sys.exit(0)
df_raw = read_csv_with_fallback(path)
src_desc = f'CSVファイル: {os.path.basename(path)}'
else:
dest = 'titanic.csv'
path = download_sample_titanic(dest)
df_raw = read_csv_with_fallback(path)
src_desc = 'サンプルTitanic(seaborn-data)'
log_print(f'データソース: {src_desc}')
log_print(f'元データ形状: {df_raw.shape[0]} 行 x {df_raw.shape[1]} 列')
X, feature_names, df_clean, info = preprocess_dataframe(df_raw)
log_print(f'除外行数(全欠損行): {info["dropped_rows"]}')
log_print(f'数値列: {info["num_cols"]},カテゴリ列: {info["cat_cols"]}')
log_print(f'高カーディナリティ列の除外: {info["excluded_high_card_cols"]}')
log_print(f'定数列の除去: {info["removed_constant_cols"]}')
log_print(f'特徴行列形状: {X.shape[0]} x {X.shape[1]}')
k_text = input('クラスタ数K(例: 3。未入力は3): ').strip()
try:
K = int(k_text) if k_text else 3
except Exception:
K = 3
log_print('Kの入力値を解釈できませんでした。K=3を使用します')
p_text = input('t-SNE perplexity(未入力は自動): ').strip()
perplexity = select_perplexity(X.shape[0], p_text)
log_print(f'使用K: {K}')
log_print(f'使用perplexity: {perplexity}')
labels, coords, kmeans_model = run_kmeans_tsne(X, K, perplexity, n_iter=1000)
log_print(f'クラスタ割当て取得: {len(labels)} 件')
counts = pd.Series(labels).value_counts().sort_index()
for cid, cnt in counts.items():
log_print(f'cluster_id={cid}: {cnt} 件')
log_print('t-SNE座標計算完了(形状: {} x 2)'.format(coords.shape[0]))
step_banner('可視化表示')
plot_embedding(coords, labels)
df_out = df_clean.copy()
df_out['cluster_id'] = labels
log_print('元データにcluster_idを付与しました')
analyze_cluster_characteristics(df_out)
log_print('=== データ(cluster_id付)CSV ===')
csv_text = df_out.to_csv(index=False)
print(csv_text)
RESULT_LOG.append(csv_text)
finally_msg = '\n=== プログラム終了 ==='
print(finally_msg)
RESULT_LOG.append(finally_msg)
try:
with open('result.txt', 'w', encoding='utf-8') as f:
f.write('=== 結果 ===\n')
f.write(f'タイムスタンプ: {datetime.now().strftime("%Y-%m-%d %H:%M:%S")}\n')
f.write('\n'.join(RESULT_LOG))
print('処理結果をresult.txtに保存しました')
except Exception as e:
print('結果ファイルの保存に失敗しました')
print(str(e))