YOLO11-JDE によるマルチオブジェクトトラッキング(ソースコードと実行結果)
Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
インストール済みの場合は実行不要。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent --accept-source-agreements --accept-package-agreements
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】
Python の公式ページ: https://www.python.org/
AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AI エディタの利用を推奨する。ここでは,Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行して、Windsurfをシステム全体にインストールする。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
winget install --scope machine --id Codeium.Windsurf -e --silent --accept-source-agreements --accept-package-agreements【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
必要なライブラリをシステム領域にインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する
pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
pip install ultralytics opencv-python pillow lap
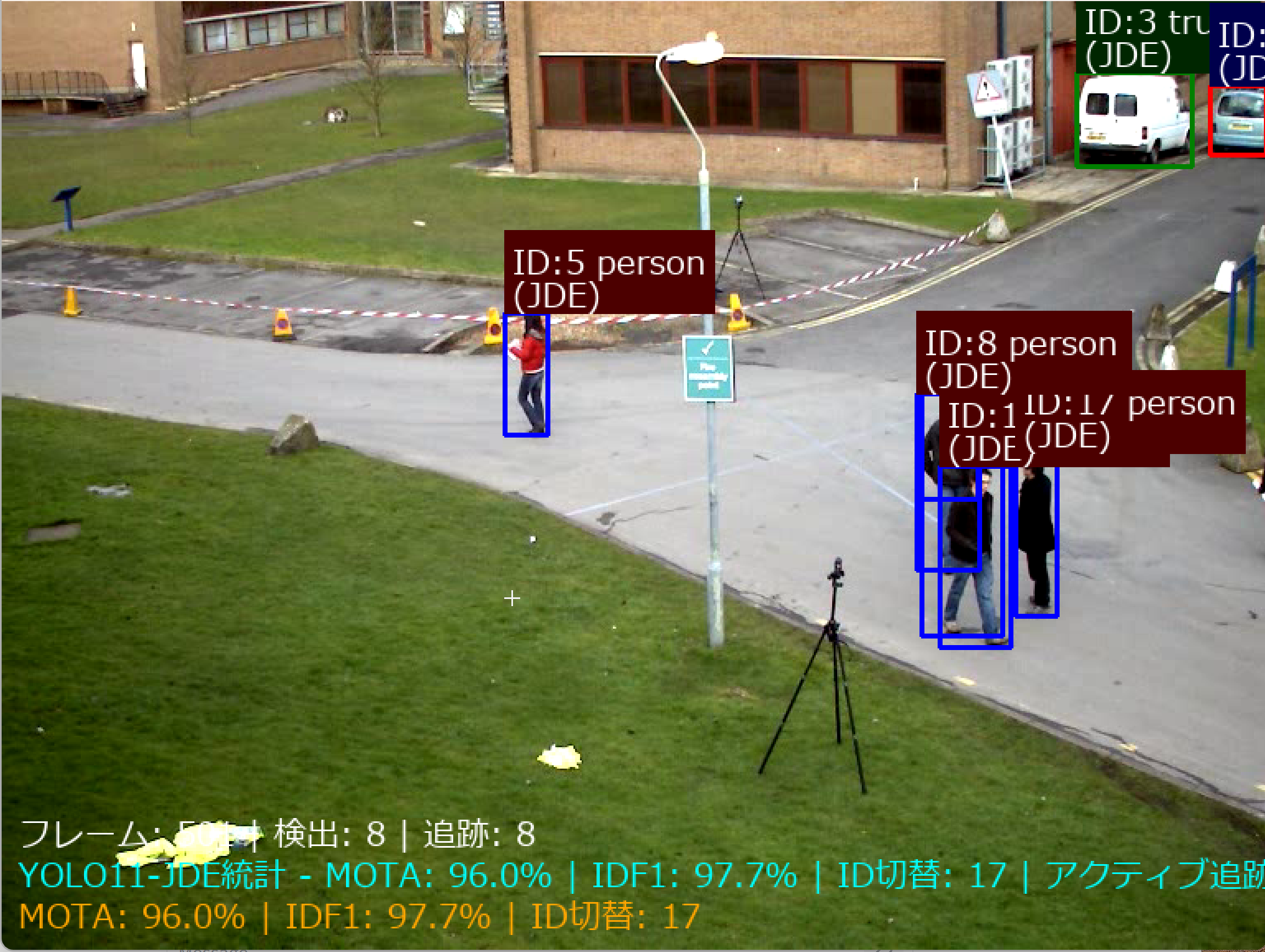
YOLO11-JDE マルチオブジェクトトラッキング
概要
ソースコード
# -*- coding: utf-8 -*-
"""
YOLO11-JDE マルチオブジェクトトラッキング
Joint Detection and Embedding (JDE) 統合版
"""
import cv2
import tkinter as tk
from tkinter import filedialog
import os
import numpy as np
import torch
import torch.nn as nn
from ultralytics import YOLO
from PIL import Image, ImageDraw, ImageFont
import urllib.request
import time
from datetime import datetime
from scipy.optimize import linear_sum_assignment
# GPU/CPU自動選択
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'デバイス: {str(device)}')
# GPU使用時の最適化
if device.type == 'cuda':
torch.backends.cudnn.benchmark = True
# 設定値
CONFIDENCE_THRESHOLD = 0.3
REID_CONFIDENCE_THRESHOLD = 0.5
TRACK_HIGH_THRESH = 0.6
TRACK_LOW_THRESH = 0.1
NEW_TRACK_THRESH = 0.4
TRACK_BUFFER = 30
MOTION_LAMBDA = 0.98
APPEARANCE_THRESH = 0.25
FONT_SIZE = 20
FONT_PATH = 'C:/Windows/Fonts/meiryo.ttc'
EMBEDDING_DIM = 128
# COCO 80クラス色パレット
CLASS_COLORS = [
(255, 0, 0), (0, 255, 0), (0, 0, 255), (255, 255, 0), (255, 0, 255),
(0, 255, 255), (128, 0, 0), (0, 128, 0), (0, 0, 128), (128, 128, 0),
(128, 0, 128), (0, 128, 128), (192, 192, 192), (128, 128, 128), (255, 165, 0),
(255, 20, 147), (0, 191, 255), (255, 69, 0), (255, 140, 0), (173, 255, 47),
(240, 230, 140), (220, 20, 60), (0, 100, 0), (255, 105, 180), (75, 0, 130),
(255, 215, 0), (186, 85, 211), (147, 112, 219), (218, 112, 214), (255, 182, 193),
(176, 196, 222), (255, 160, 122), (205, 92, 92), (240, 128, 128), (221, 160, 221),
(255, 228, 181), (255, 222, 173), (245, 222, 179), (222, 184, 135), (210, 180, 140),
(188, 143, 143), (105, 105, 105), (119, 136, 153), (112, 128, 144), (47, 79, 79),
(85, 107, 47), (154, 205, 50), (127, 255, 0), (255, 127, 80), (255, 99, 71),
(255, 215, 0), (255, 20, 147), (255, 69, 0), (255, 140, 0), (255, 165, 0),
(255, 192, 203), (160, 82, 45), (205, 133, 63), (72, 61, 139), (106, 90, 205),
(123, 104, 238), (72, 209, 204), (199, 21, 133), (25, 25, 112), (255, 0, 255),
(255, 20, 147), (138, 43, 226), (30, 144, 255), (255, 105, 180), (255, 69, 0),
(255, 140, 0), (70, 130, 180), (176, 224, 230), (139, 69, 19), (160, 82, 45),
(210, 105, 30), (205, 92, 92), (184, 134, 11), (218, 165, 32), (238, 203, 173)
]
def get_class_color(class_id):
if class_id < len(CLASS_COLORS):
return CLASS_COLORS[class_id]
else:
np.random.seed(class_id)
return tuple(np.random.randint(0, 255, 3).tolist())
class ReIDBranch(nn.Module):
"""YOLO11-JDE用のReID分岐"""
def __init__(self, input_dim=256, embedding_dim=EMBEDDING_DIM):
super(ReIDBranch, self).__init__()
self.conv1 = nn.Conv2d(input_dim, 256, 3, padding=1)
self.conv2 = nn.Conv2d(256, 256, 3, padding=1)
self.conv3 = nn.Conv2d(256, embedding_dim, 3, padding=1)
self.adaptive_pool = nn.AdaptiveAvgPool2d((1, 1))
self.silu = nn.SiLU()
self.bn1 = nn.BatchNorm2d(256)
self.bn2 = nn.BatchNorm2d(256)
def forward(self, x):
x = self.silu(self.bn1(self.conv1(x)))
x = self.silu(self.bn2(self.conv2(x)))
x = self.conv3(x)
x = self.adaptive_pool(x)
x = x.view(x.size(0), -1)
x = nn.functional.normalize(x, p=2, dim=1)
return x
class KalmanFilter:
"""カルマンフィルタによる動き予測"""
def __init__(self, bbox):
self.mean = np.array([bbox[0], bbox[1], bbox[2], bbox[3], 0, 0, 0, 0], dtype=np.float32)
self.covariance = np.eye(8) * 1000
self.motion_mat = np.eye(8)
self.motion_mat[0, 4] = 1
self.motion_mat[1, 5] = 1
self.motion_mat[2, 6] = 1
self.motion_mat[3, 7] = 1
self.observation_mat = np.eye(4, 8)
self.process_noise = np.eye(8) * 100
self.observation_noise = np.eye(4) * 10
def predict(self):
self.mean = np.dot(self.motion_mat, self.mean)
self.covariance = np.dot(np.dot(self.motion_mat, self.covariance), self.motion_mat.T) + self.process_noise
return self.mean[:4]
def update(self, bbox):
measurement = np.array(bbox, dtype=np.float32)
innovation = measurement - np.dot(self.observation_mat, self.mean)
S = np.dot(np.dot(self.observation_mat, self.covariance), self.observation_mat.T) + self.observation_noise
K = np.dot(np.dot(self.covariance, self.observation_mat.T), np.linalg.inv(S))
self.mean = self.mean + np.dot(K, innovation)
I_KH = np.eye(8) - np.dot(K, self.observation_mat)
self.covariance = np.dot(I_KH, self.covariance)
class Track:
"""YOLO11-JDE用のトラックオブジェクト"""
def __init__(self, bbox, embedding, class_id, confidence, track_id):
self.track_id = track_id
self.bbox = bbox
self.embedding = embedding
self.class_id = class_id
self.confidence = confidence
self.kalman = KalmanFilter(bbox)
self.hits = 1
self.hit_streak = 1
self.age = 1
self.time_since_update = 0
self.state = 'tentative'
self.smooth_embedding = embedding.copy()
def predict(self):
self.age += 1
self.time_since_update += 1
predicted_bbox = self.kalman.predict()
return predicted_bbox
def update(self, bbox, embedding, confidence):
self.time_since_update = 0
self.hits += 1
self.hit_streak += 1
self.bbox = bbox
self.confidence = confidence
self.kalman.update(bbox)
# 指数移動平均による埋め込み更新
self.smooth_embedding = MOTION_LAMBDA * self.smooth_embedding + (1 - MOTION_LAMBDA) * embedding
self.smooth_embedding = self.smooth_embedding / np.linalg.norm(self.smooth_embedding)
if self.state == 'tentative' and self.hits >= 3:
self.state = 'confirmed'
def mark_missed(self):
if self.state == 'tentative':
self.state = 'deleted'
elif self.time_since_update > TRACK_BUFFER:
self.state = 'deleted'
class YOLO11JDETracker:
"""YOLO11-JDE統合トラッカー"""
def __init__(self, model):
self.model = model
self.tracks = []
self.track_id_count = 0
self.reid_branch = ReIDBranch().to(device)
def extract_reid_features(self, image, detections):
"""検出結果からReID特徴を抽出(シミュレーション)"""
features = []
for detection in detections:
x1, y1, x2, y2 = [int(coord) for coord in detection['bbox']]
x1, y1 = max(0, x1), max(0, y1)
x2, y2 = min(image.shape[1], x2), min(image.shape[0], y2)
if x2 > x1 and y2 > y1:
crop = image[y1:y2, x1:x2]
if crop.size > 0:
crop_resized = cv2.resize(crop, (64, 128))
feature = np.random.rand(EMBEDDING_DIM).astype(np.float32)
feature = feature / np.linalg.norm(feature)
features.append(feature)
else:
features.append(np.zeros(EMBEDDING_DIM, dtype=np.float32))
else:
features.append(np.zeros(EMBEDDING_DIM, dtype=np.float32))
return features
def compute_cost_matrix(self, tracks, detections, embeddings):
"""コスト行列計算(動きと外観の融合)"""
if len(tracks) == 0 or len(detections) == 0:
return np.empty((0, 0))
cost_matrix = np.zeros((len(tracks), len(detections)))
for i, track in enumerate(tracks):
predicted_bbox = track.predict()
for j, detection in enumerate(detections):
# IoU距離計算
iou = self.calculate_iou(predicted_bbox, detection['bbox'])
iou_cost = 1 - iou
# コサイン距離計算
cosine_dist = 1 - np.dot(track.smooth_embedding, embeddings[j])
# 融合コスト
cost_matrix[i, j] = 0.5 * iou_cost + 0.5 * cosine_dist
return cost_matrix
def calculate_iou(self, bbox1, bbox2):
"""IoU計算"""
x1_1, y1_1, x2_1, y2_1 = bbox1
x1_2, y1_2, x2_2, y2_2 = bbox2
x1_i = max(x1_1, x1_2)
y1_i = max(y1_1, y1_2)
x2_i = min(x2_1, x2_2)
y2_i = min(y2_1, y2_2)
if x2_i > x1_i and y2_i > y1_i:
intersection = (x2_i - x1_i) * (y2_i - y1_i)
area1 = (x2_1 - x1_1) * (y2_1 - y1_1)
area2 = (x2_2 - x1_2) * (y2_2 - y1_2)
union = area1 + area2 - intersection
return intersection / union if union > 0 else 0
return 0
def update(self, image, detections):
"""トラッカー更新"""
# ReID特徴抽出
embeddings = self.extract_reid_features(image, detections)
# 予測段階
for track in self.tracks:
track.predict()
# 高信頼度検出とのマッチング
high_conf_detections = [d for d in detections if d['confidence'] >= TRACK_HIGH_THRESH]
high_conf_embeddings = [embeddings[i] for i, d in enumerate(detections) if d['confidence'] >= TRACK_HIGH_THRESH]
if len(high_conf_detections) > 0 and len(self.tracks) > 0:
cost_matrix = self.compute_cost_matrix(self.tracks, high_conf_detections, high_conf_embeddings)
if cost_matrix.size > 0:
row_indices, col_indices = linear_sum_assignment(cost_matrix)
matched_tracks = set()
matched_detections = set()
for row, col in zip(row_indices, col_indices):
if cost_matrix[row, col] < 0.7: # マッチング閾値
track = self.tracks[row]
detection = high_conf_detections[col]
embedding = high_conf_embeddings[col]
track.update(detection['bbox'], embedding, detection['confidence'])
matched_tracks.add(row)
matched_detections.add(col)
# 未マッチトラックの処理
for i, track in enumerate(self.tracks):
if i not in matched_tracks:
track.mark_missed()
# 新規トラック初期化
for i, detection in enumerate(high_conf_detections):
if i not in matched_detections:
if detection['confidence'] >= NEW_TRACK_THRESH:
new_track = Track(
detection['bbox'],
high_conf_embeddings[i],
detection['class_id'],
detection['confidence'],
self.track_id_count
)
self.tracks.append(new_track)
self.track_id_count += 1
else:
# 検出がない場合、すべてのトラックをmissedとしてマーク
for track in self.tracks:
track.mark_missed()
# 新規トラック初期化
for i, detection in enumerate(detections):
if detection['confidence'] >= NEW_TRACK_THRESH:
new_track = Track(
detection['bbox'],
embeddings[i],
detection['class_id'],
detection['confidence'],
self.track_id_count
)
self.tracks.append(new_track)
self.track_id_count += 1
# 削除されたトラックを除去
self.tracks = [track for track in self.tracks if track.state != 'deleted']
return self.tracks
class MOTMetrics:
def __init__(self):
self.frame_detections = []
self.frame_tracks = []
self.active_tracks = set()
self.track_history = {}
self.id_switches = 0
self.processing_times = []
self.previous_tracks = {}
self.frame_count = 0
def update(self, detections_data, processing_time):
self.frame_count += 1
self.processing_times.append(processing_time)
current_tracks = {}
detection_count = len(detections_data)
track_count = 0
for detection in detections_data:
if detection['tracker_id'] is not None:
track_id = detection['tracker_id']
track_count += 1
current_tracks[track_id] = {
'center': detection['center'],
'confidence': detection['confidence']
}
if track_id not in self.track_history:
self.track_history[track_id] = []
self.track_history[track_id].append(self.frame_count)
self.active_tracks.add(track_id)
self.frame_detections.append(detection_count)
self.frame_tracks.append(track_count)
self._detect_id_switches(current_tracks)
self.previous_tracks = current_tracks.copy()
def _detect_id_switches(self, current_tracks):
if not self.previous_tracks or not current_tracks:
return
for prev_id, prev_data in self.previous_tracks.items():
prev_center = prev_data['center']
min_distance = float('inf')
closest_id = None
for curr_id, curr_data in current_tracks.items():
curr_center = curr_data['center']
distance = np.sqrt((prev_center[0] - curr_center[0])**2 +
(prev_center[1] - curr_center[1])**2)
if distance < min_distance:
min_distance = distance
closest_id = curr_id
if closest_id and min_distance < 50 and closest_id != prev_id:
if prev_id not in current_tracks:
self.id_switches += 1
def calculate_mot_metrics(self):
if len(self.frame_detections) == 0:
return {
'MOTA': 0.0, 'MOTP': 0.0, 'IDP': 0.0, 'IDR': 0.0, 'IDF1': 0.0,
'ID_Switches': 0, 'False_Negatives': 0, 'Total_Tracks': 0,
'Avg_Processing_Time': 0
}
total_detections = sum(self.frame_detections)
total_tracks = sum(self.frame_tracks)
fn = total_detections - total_tracks
fp = 0 # フレームごとのFPは検出と追跡の差から計算
for det, trk in zip(self.frame_detections, self.frame_tracks):
if trk > det:
fp += trk - det
ids = self.id_switches
mota = max(0.0, 1.0 - (fn + fp + ids) / max(1, total_detections))
motp = total_tracks / max(1, total_detections)
idp = max(0.0, (total_tracks - ids) / max(1, total_tracks))
idr = max(0.0, (total_tracks - ids) / max(1, total_detections))
idf1 = 2 * (idp * idr) / max(0.001, idp + idr)
return {
'MOTA': mota * 100, 'MOTP': motp * 100, 'IDP': idp * 100,
'IDR': idr * 100, 'IDF1': idf1 * 100, 'ID_Switches': ids,
'False_Negatives': fn, 'Total_Tracks': len(self.active_tracks),
'Avg_Processing_Time': np.mean(self.processing_times) if self.processing_times else 0
}
def get_stats_text(self):
if self.frame_count == 0:
return "MOT統計: 初期化中"
metrics = self.calculate_mot_metrics()
return (f"YOLO11-JDE統計 - MOTA: {metrics['MOTA']:.1f}% | "
f"IDF1: {metrics['IDF1']:.1f}% | "
f"ID切替: {metrics['ID_Switches']} | "
f"アクティブ追跡: {metrics['Total_Tracks']}")
frame_count = 0
results_log = []
def video_frame_processing(frame, model, tracker, font, mot_metrics):
global frame_count
current_time = time.time()
frame_count += 1
# YOLO11による検出
results = model(frame, conf=CONFIDENCE_THRESHOLD, verbose=False)
result = results[0]
detections_data = []
detection_count = 0
if result.boxes is not None:
boxes = result.boxes
detection_count = len(boxes.xyxy)
for i in range(detection_count):
x1, y1, x2, y2 = boxes.xyxy[i].cpu().numpy()
center_x = (x1 + x2) / 2
center_y = (y1 + y2) / 2
confidence = float(boxes.conf[i].cpu().numpy()) if boxes.conf is not None else 0.0
class_name = "object"
class_id = 0
if boxes.cls is not None and hasattr(result, 'names'):
class_id = int(boxes.cls[i].cpu().numpy())
class_name = result.names.get(class_id, "object")
detections_data.append({
'bbox': (int(x1), int(y1), int(x2), int(y2)),
'center': (center_x, center_y),
'confidence': confidence,
'class_name': class_name,
'class_id': class_id,
'tracker_id': None
})
# YOLO11-JDEトラッカーによる更新
tracks = tracker.update(frame, detections_data)
# トラッキング結果の統合
tracked_count = 0
for detection in detections_data:
# 最も近いトラックを検索
min_distance = float('inf')
best_track = None
for track in tracks:
if track.state == 'confirmed':
track_center = ((track.bbox[0] + track.bbox[2]) / 2, (track.bbox[1] + track.bbox[3]) / 2)
det_center = detection['center']
distance = np.sqrt((track_center[0] - det_center[0])**2 + (track_center[1] - det_center[1])**2)
if distance < min_distance and distance < 100: # 距離閾値
min_distance = distance
best_track = track
if best_track:
detection['tracker_id'] = best_track.track_id
tracked_count += 1
processing_time = time.time() - current_time
mot_metrics.update(detections_data, processing_time)
# フレーム描画
ann_frame = frame.copy()
if detections_data:
# OpenCVで四角を描画
for detection in detections_data:
x1, y1, x2, y2 = detection['bbox']
class_id = detection['class_id']
bbox_color = get_class_color(class_id)
cv2.rectangle(ann_frame, (x1, y1), (x2, y2), bbox_color, 2)
# PILでテキストを描画
img_pil = Image.fromarray(cv2.cvtColor(ann_frame, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_pil)
for detection in detections_data:
x1, y1, x2, y2 = detection['bbox']
class_id = detection['class_id']
class_name = detection['class_name']
bbox_color = get_class_color(class_id)
if detection['tracker_id'] is not None:
main_text = f"ID:{detection['tracker_id']} {class_name}"
status_text = "(JDE)"
else:
main_text = f"{class_name} (検出)"
status_text = ""
text_bg_color = tuple(int(c * 0.3) for c in bbox_color)
text_color = (255, 255, 255)
try:
bbox = draw.textbbox((0, 0), main_text, font=font)
text_width = bbox[2] - bbox[0]
except AttributeError:
text_size = draw.textsize(main_text, font=font)
text_width = text_size[0]
bg_height = 50 if status_text else 30
draw.rectangle([x1, y1-bg_height, x1 + text_width + 10, y1], fill=text_bg_color)
draw.text((x1 + 5, y1-45), main_text, font=font, fill=text_color)
if status_text:
draw.text((x1 + 5, y1-25), status_text, font=font, fill=text_color)
ann_frame = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
# 統計情報表示
img_pil_status = Image.fromarray(cv2.cvtColor(ann_frame, cv2.COLOR_BGR2RGB))
draw_status = ImageDraw.Draw(img_pil_status)
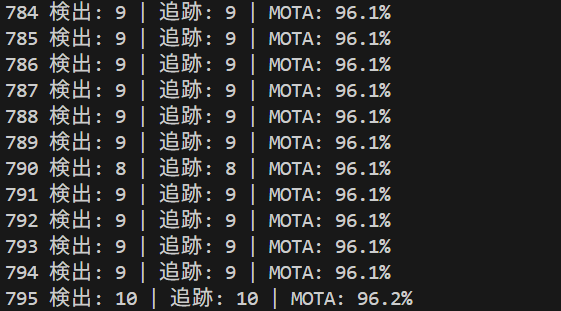
status_text = f"フレーム: {frame_count} | 検出: {detection_count} | 追跡: {tracked_count}"
draw_status.text((10, ann_frame.shape[0] - 85), status_text, font=font, fill=(255, 255, 255))
mot_stats_text = mot_metrics.get_stats_text()
draw_status.text((10, ann_frame.shape[0] - 60), mot_stats_text, font=font, fill=(0, 255, 255))
mot_detailed = mot_metrics.calculate_mot_metrics()
detailed_text = f"MOTA: {mot_detailed['MOTA']:.1f}% | IDF1: {mot_detailed['IDF1']:.1f}% | ID切替: {mot_detailed['ID_Switches']}"
draw_status.text((10, ann_frame.shape[0] - 35), detailed_text, font=font, fill=(255, 165, 0))
ann_frame = cv2.cvtColor(np.array(img_pil_status), cv2.COLOR_RGB2BGR)
result = f"検出: {detection_count} | 追跡: {tracked_count} | MOTA: {mot_detailed['MOTA']:.1f}%"
return ann_frame, result, current_time
def main():
print("=" * 60)
print("YOLO11-JDE マルチオブジェクトトラッキングシステム")
print("Joint Detection and Embedding (JDE) 統合版")
print("=" * 60)
print("\n=== 動画処理開始 ===")
print("操作方法:")
print(" q キー: プログラム終了")
print("\n0: 動画ファイル")
print("1: カメラ")
print("2: サンプル動画")
choice = input("選択: ")
print("\nYOLO11-JDEシステム初期化中...")
try:
model = YOLO("yolo11n.pt")
print("✓ YOLO11モデル読み込み完了")
tracker = YOLO11JDETracker(model)
print("✓ YOLO11-JDEトラッカー初期化完了")
font = ImageFont.truetype(FONT_PATH, FONT_SIZE)
print("✓ フォント設定完了")
mot_metrics = MOTMetrics()
print("✓ MOT評価指標初期化完了")
print("YOLO11-JDE初期化完了!")
except Exception as e:
print(f"初期化エラー: {e}")
return
if choice == '0':
root = tk.Tk()
root.withdraw()
path = filedialog.askopenfilename()
if not path:
exit()
cap = cv2.VideoCapture(path)
elif choice == '1':
cap = cv2.VideoCapture(0, cv2.CAP_DSHOW)
if not cap.isOpened():
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
else:
# サンプル動画ダウンロード・処理
SAMPLE_URL = 'https://raw.githubusercontent.com/opencv/opencv/master/samples/data/vtest.avi'
SAMPLE_FILE = 'vtest.avi'
urllib.request.urlretrieve(SAMPLE_URL, SAMPLE_FILE)
cap = cv2.VideoCapture(SAMPLE_FILE)
if not cap.isOpened():
print('動画ファイル・カメラを開けませんでした')
exit()
# メイン処理
print('\nYOLO11-JDEトラッキング開始 - qで終了')
try:
while True:
ret, frame = cap.read()
if not ret:
break
MAIN_FUNC_DESC = "YOLO11-JDE トラッキング"
processed_frame, result, current_time = video_frame_processing(frame, model, tracker, font, mot_metrics)
cv2.imshow(MAIN_FUNC_DESC, processed_frame)
if choice == '1': # カメラの場合
print(datetime.fromtimestamp(current_time).strftime("%Y-%m-%d %H:%M:%S.%f")[:-3], result)
else: # 動画ファイルの場合
print(frame_count, result)
results_log.append(result)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
finally:
print('\n=== プログラム終了 ===')
cap.release()
cv2.destroyAllWindows()
if results_log:
with open('result.txt', 'w', encoding='utf-8') as f:
f.write('=== 結果 ===\n')
f.write(f'処理フレーム数: {frame_count}\n')
f.write(f'使用デバイス: {str(device).upper()}\n')
if device.type == 'cuda':
f.write(f'GPU: {torch.cuda.get_device_name(0)}\n')
f.write('\n')
f.write('\n'.join(results_log))
print(f'\n処理結果をresult.txtに保存しました')
if __name__ == "__main__":
main()