Tesseract OCR 日本語・英語文字認識(ソースコードと実行結果)

Tesseract OCR 最新版のダウンロードとインストールと動作確認
ダウンロードとインストール
- 1. ダウンロード
Tesseract OCR の公式ドキュメントのページを開きます。
https://github.com/tesseract-ocr/tessdoc
Windows の項目にある「Tesseract at UB Mannheim」(ドイツのマンハイム大学が提供するWindows用インストーラー)のリンクをクリックします。
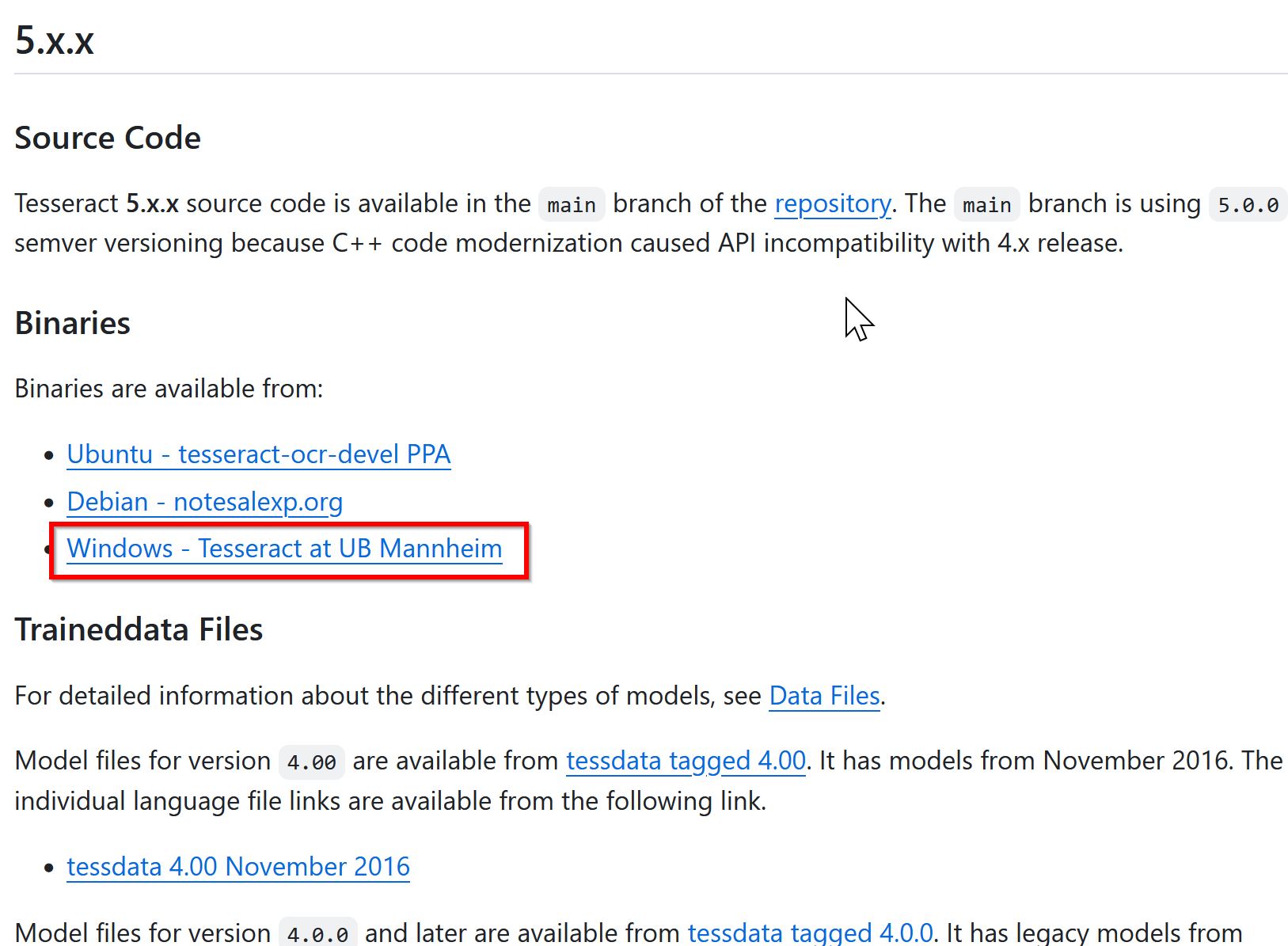
最新版のインストーラー(例: `tesseract-ocr-w64-setup-v5.5.0.20241111.exe`)を選択します。
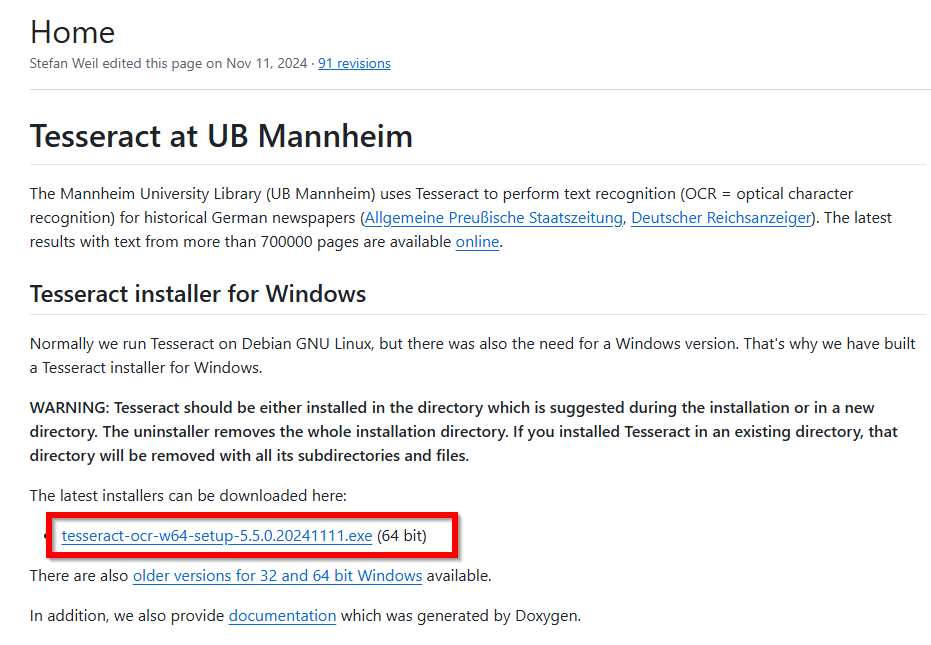
.exe ファイルのダウンロードが開始されます。

- 2. インストーラーの起動と初期設定
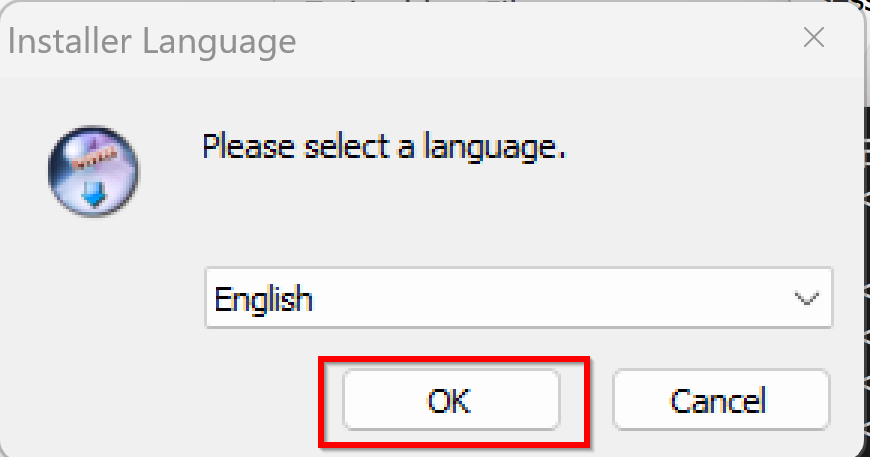
ダウンロードした .exe ファイルを実行します。
最初の言語選択画面では「OK」をクリックします。
ようこそ画面では「Next」をクリックします。
ライセンス条項を確認し、同意する場合は「I Agree」をクリックして次に進みます。
インストール対象ユーザーを選択します(Choose Users)。通常は既定値(Install for anyone using this computer)のままで問題ありません。「Next」をクリックします。
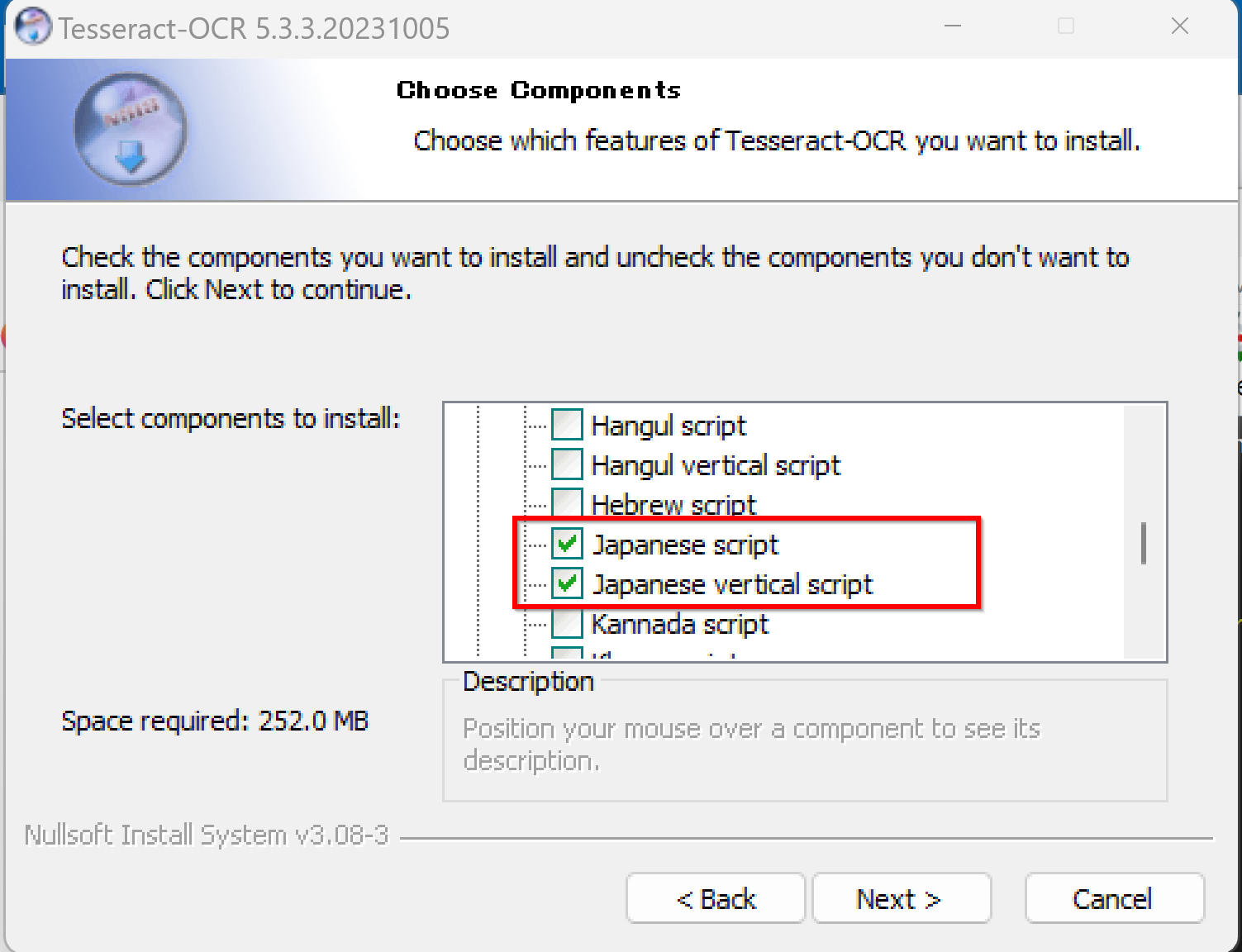
- 3. コンポーネント(言語データ)の選択
コンポーネント選択画面 (Choose Components) です。ここでOCR処理に必要な言語データを追加します。日本語を扱うため、以下の項目にチェックを入れてください。
- Additional script data (download) で「Japanese script」と「Japanese vertical script」を選択してください。
- Additional language data (download) で「Japanese」と「Japanese (vertical)」を選択してください。
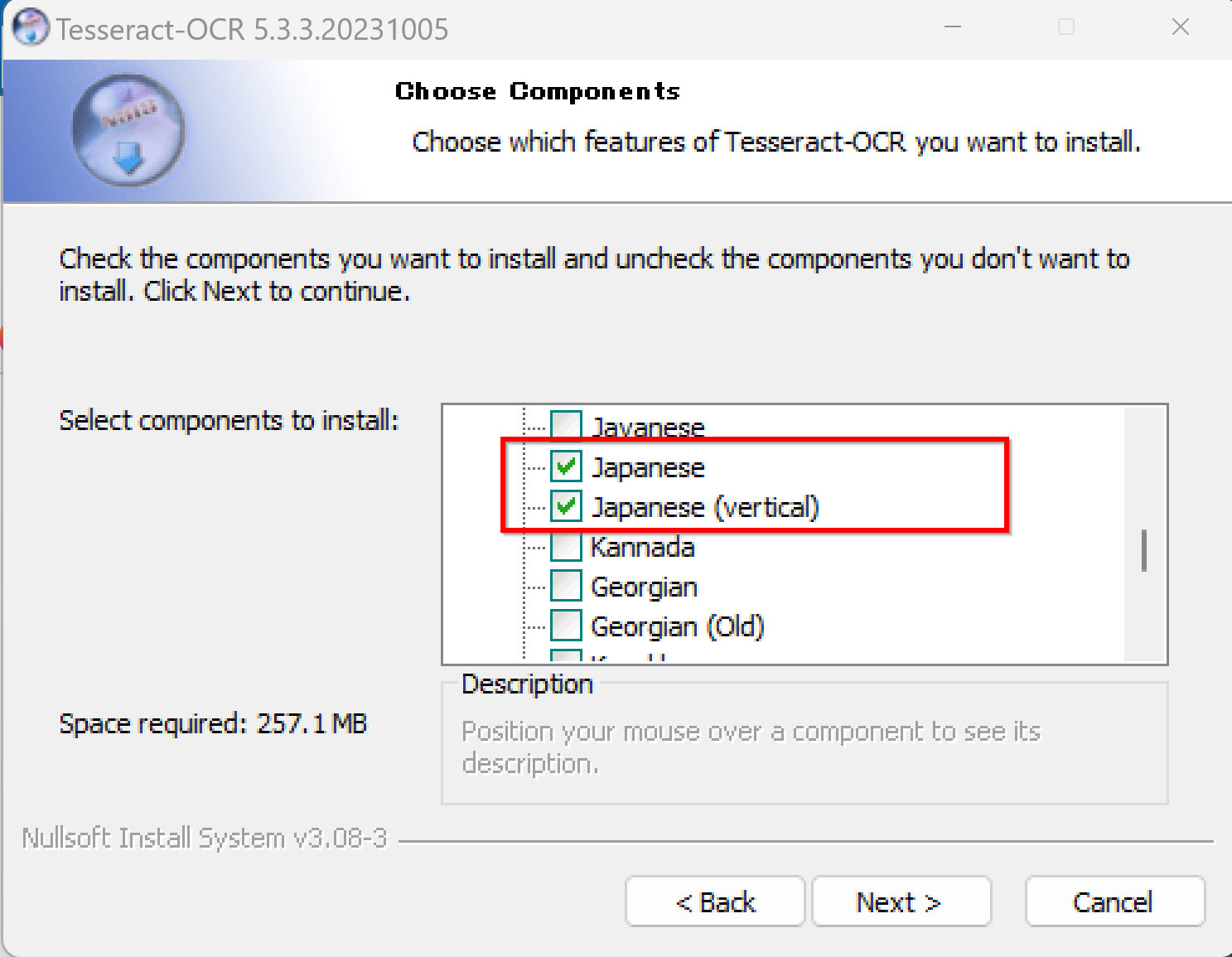
他のコンポーネントは必要に応じて選択しますが、通常は既定値のままで構いません。「Next」をクリックします。
- 4. インストール先と完了
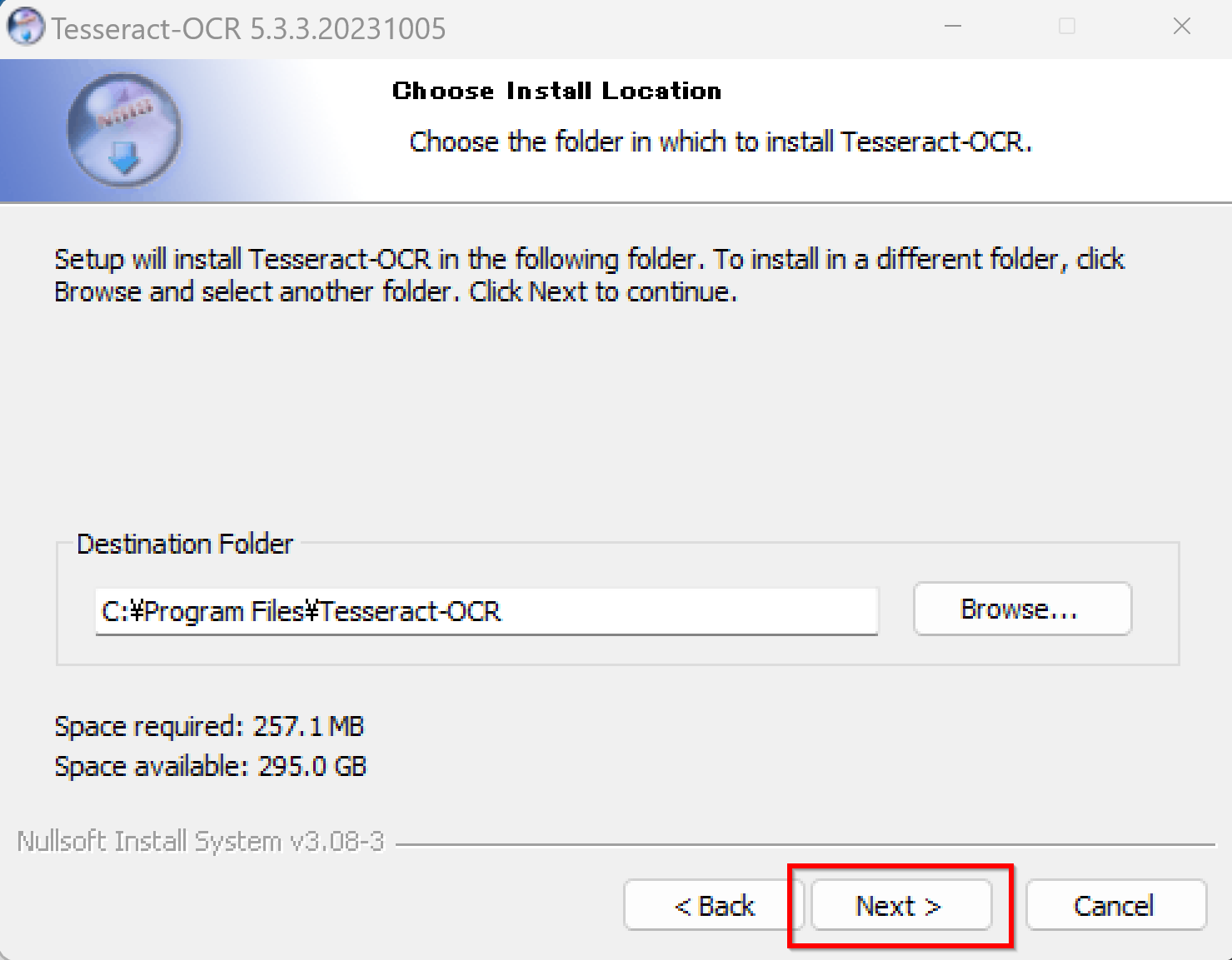
インストールディレクトリ(フォルダ)を選択します(Choose Install Location)。通常は既定値 (`C:\Program Files\Tesseract-OCR`) のままで問題ありません。「Next」をクリックします。
スタートメニューフォルダを選択します(Choose Start Menu Folder)。通常は既定値のままで問題ありません。「Install」をクリックするとインストールが開始されます。
インストール完了画面が表示されたら、「Next」をクリックします。
最終確認画面です。「Finish」をクリックしてインストーラーを終了します。
動作確認
コマンドを用いて,画像ファイルからの日本語OCR実行を行う.
- 準備(画像ファイル、コマンドプロンプト)
日本語の文章が書かれた画像ファイルを用意します。
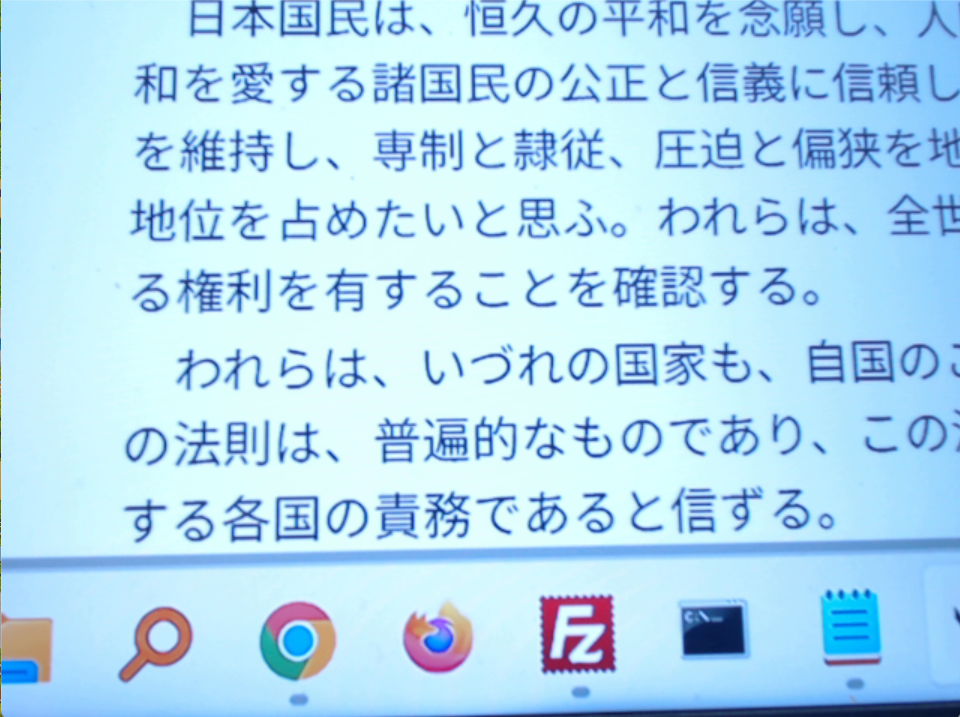
例として、次の画像はWikipedia「日本国憲法前文」から取得したものです。
(参考)Wikipedia「日本国憲法前文」のURL: https://ja.wikipedia.org/wiki/%E6%97%A5%E6%9C%AC%E5%9B%BD%E6%86%B2%E6%B3%95%E5%89%8D%E6%96%87#%E5%89%8D%E6%96%87

- Windows のコマンドプロンプトを開きます。
- まず、コマンドプロンプトで `cd` コマンドを使い、画像ファイルが保存されているディレクトリ(フォルダ)に移動します。
- コマンド実行(横書き)
画像から文字を認識させます。以下のコマンド形式で実行します。
"C:\Program Files\Tesseract-OCR\tesseract.exe" <画像ファイル名> outbase -l jpn
コマンド解説:
"C:\Program Files\Tesseract-OCR\tesseract.exe": Tesseract OCRの実行ファイルへのパスです。既定の場所にインストールした場合のパスであり、異なる場所にインストールした場合は適宜変更してください。<画像ファイル名>: 処理したい画像ファイル名(例: `image.png`)を指定します。outbase: 出力ファイル名のベースを指定します。この場合、認識結果は `outbase.txt` という名前のテキストファイルに出力されます。-l jpn: 使用する言語データを指定します。日本語の横書き文書の場合は「jpn」を指定します。日本語の縦書き文書の場合は「-l jpn_vert」を使用します。

- 結果確認
コマンド実行後、
outbase.txtというファイルが生成されます。これをメモ帳などのテキストエディタで開いて、認識結果を確認します。notepad outbase.txt
一般に、文字が大きく鮮明に写っている(解像度が高い)ほど、Tesseractは文字の形状を正確に捉えやすくなるため、認識精度が向上します。


Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
インストール済みの場合は実行不要。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent --accept-source-agreements --accept-package-agreements
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】
Python の公式ページ: https://www.python.org/
AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AI エディタの利用を推奨する。ここでは,Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行して、Windsurfをシステム全体にインストールする。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
winget install --scope machine --id Codeium.Windsurf -e --silent --accept-source-agreements --accept-package-agreements【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
必要なライブラリをシステム領域にインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する
pip install opencv-python
Tesseract OCR 日本語・英語文字認識プログラム
概要
Webカメラから単一フレームを取得し、Tesseract OCRで日本語と英語の文字認識を行うPythonプログラム。認識テキストと平均信頼度を標準出力する。
前提条件
- Tesseract本体: 外部バイナリ(Windowsではtesseract.exe)の手動インストールが必要
- OpenCV: Webカメラ制御用ライブラリ(
pip install opencv-pythonで手動インストール) - 言語モデル: tessdata_fastのjpnとengを実行時に自動ダウンロード
主要技術
Tesseract OCR
Googleが開発したオープンソース光学文字認識エンジン。LSTMニューラルネットワークを基盤とし、100以上の言語に対応。本プログラムでは日本語(jpn)と英語(eng)のモデルを使用する。
tessdata_fast
軽量化された整数化LSTMモデルセット。速度と精度のバランスを重視したTesseract用学習済みモデル。
技術仕様
OCR設定
- OCRエンジンモード: OEM 1(LSTMエンジンのみ使用)
- ページセグメンテーション: PSM 6(単一均一テキストブロック処理)
- 言語指定: jpn+eng(日本語・英語混在対応)
信頼度算出
TSV(Tab-Separated Values)出力の各語conf値を算術平均して総合信頼度を算出。
実行方法
基本実行
python script.pyカメラ指定実行
python script.py 1出力形式
標準出力に「認識テキスト[TAB]平均信頼度」を1行で出力。
例: Hello 世界 123 87.4
実装特徴
- 単一ファイル構成: 全機能を1つのPythonファイルに実装
- 自動モデル管理: 言語モデルをスクリプト直下のtessdataディレクトリに自動配置
- 環境変数制御: TESSDATA_PREFIXと--tessdata-dirで明示的パス指定
- マルチカメラ対応: コマンドライン引数でカメラデバイス番号指定可能
設定パラメータ
PSMモード選択指針
- 単一行テキスト: --psm 7
- 複数行テキスト: --psm 6(デフォルト)
後処理オプション
用途に応じて最小信頼度フィルタなどの後処理追加が可能。
参考文献
[1] Tesseract Development Team. (2024). tessdata_fast: Fast integer versions of trained LSTM models. GitHub. https://github.com/tesseract-ocr/tessdata_fast
[2] Tesseract OCR Documentation. (2024). Page segmentation modes explained. tesseract-ocr.github.io. https://tesseract-ocr.github.io/tessdoc/ImproveQuality.html
ソースコード
# プログラム名: Tesseract OCR(カメラの単一フレームから日本語・英語をOCRするプログラム)
# 概要: カメラから1枚の画像を取得し、Tesseractで日本語+英語のOCRを行い、抽出テキストを出力する。
# 前準備(pipをプログラム内で実行しないこと):
# - pip install opencv-python を実行すること
# - Tesseract OCR本体をインストールすること(Windows例: https://github.com/UB-Mannheim/tesseract/wiki)
# 使い方:
# - python script.py [camera_index]
# - camera_indexを省略した場合は0を使用する
# 注意:
# - 初回実行時に英語/日本語の学習データをローカルにダウンロードする
# - ネットワーク接続が必要である
import os, sys, shutil, subprocess, urllib.request, tempfile
try:
import cv2
except ImportError:
print("OpenCV(cv2)が必要。手動で 'pip install opencv-python' を実行すること。")
sys.exit(1)
def dl(url, dst):
if not os.path.exists(dst):
os.makedirs(os.path.dirname(dst), exist_ok=True)
urllib.request.urlretrieve(url, dst)
def ensure_models(tdir):
os.makedirs(tdir, exist_ok=True)
dl("https://github.com/tesseract-ocr/tessdata_fast/raw/main/eng.traineddata", os.path.join(tdir, "eng.traineddata"))
dl("https://github.com/tesseract-ocr/tessdata_fast/raw/main/jpn.traineddata", os.path.join(tdir, "jpn.traineddata"))
def find_tesseract():
p = shutil.which("tesseract") or r"C:\Program Files\Tesseract-OCR\tesseract.exe"
if os.path.exists(p):
return p
print("tesseract.exe が見つからない。Windows用インストーラを手動導入すること。参考: https://github.com/UB-Mannheim/tesseract/wiki")
sys.exit(1)
def grab_frame(dev=0):
cap = cv2.VideoCapture(dev, cv2.CAP_DSHOW)
if not cap.isOpened():
cap = cv2.VideoCapture(dev)
if not cap.isOpened():
print("カメラを開けない")
sys.exit(1)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
ret, frame = cap.read()
cap.release()
if not ret:
print("フレーム取得に失敗")
sys.exit(1)
return frame
def ocr_text(img, tess, tdir):
tmp = os.path.join(tempfile.gettempdir(), "webcam_ocr_frame.png")
cv2.imwrite(tmp, img)
# プレーンテキストで取得
cmd_text = [
tess, tmp, "stdout",
"-l", "jpn+eng",
"--psm", "3",
"--tessdata-dir", tdir
]
result_text = subprocess.run(cmd_text, capture_output=True)
text = result_text.stdout.decode('utf-8', errors='ignore').strip()
return text
def main():
print("概要: カメラから1枚の画像を取得し、日本語+英語のOCR結果を表示する。")
print("操作: python script.py [camera_index] でカメラ番号を指定できる。省略時は0。")
print("注意: Tesseract OCR本体のインストールが必要。学習データは自動取得。ネットワーク接続が必要。")
print("画像表示: OCR処理後に画像を表示。何かキーを押すと終了。")
dev = int(sys.argv[1]) if len(sys.argv) > 1 and sys.argv[1].isdigit() else 0
tess = find_tesseract()
tdir = os.path.join(os.path.dirname(__file__) or ".", "tessdata")
ensure_models(tdir)
img = grab_frame(dev)
text = ocr_text(img, tess, tdir)
print(text)
cv2.imshow("OCR Target Image", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == "__main__":
main()