SDXL Text-to-Image Generator with Refiner and Dual Text Encoders によるテキストからの画像生成

Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
インストール済みの場合は実行不要。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent --accept-source-agreements --accept-package-agreements
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】
Python の公式ページ: https://www.python.org/
AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AI エディタの利用を推奨する。ここでは,Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行して、Windsurfをシステム全体にインストールする。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
winget install --scope machine --id Codeium.Windsurf -e --silent --accept-source-agreements --accept-package-agreements【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
必要なライブラリをシステム領域にインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する
pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
pip install diffusers==0.23.0 huggingface_hub==0.16.4 accelerate==0.21.0 transformers
SDXL Text-to-Image Generator with Refiner and Dual Text Encoders によるテキストからの画像生成プログラム
概要
このプログラムは、Stable Diffusion XL(SDXL)1.0ベースモデルとRefinerモデルを組み合わせたシステムである。1024x1024ピクセルの高品質画像を生成する。Ensemble of Expert Denoisers方式による二段階処理と、デュアルテキストエンコーダーによる詳細制御を特徴とする。
主要技術
Stable Diffusion XL(SDXL)1.0
Stability AIが2023年7月に発表した最新の潜在拡散モデルである[1]。
Ensemble of Expert Denoisers
SDXL特有の二段階処理方式である[2]。ベースモデルが高ノイズ拡散段階(80%)を担当し、Refinerモデルが低ノイズ拡散段階(20%)を担当する。
デュアルテキストエンコーダー
CLIP-ViT/L-14とOpenCLIP-ViT/G-14の2つのテキストエンコーダーを併用する[3]。CLIP-ViT/L-14は768次元、OpenCLIP-ViT/G-14は1280次元の埋め込みベクトルを生成し、連結により2048次元の包括的なテキスト表現を実現する。
技術的特徴
メモリ効率化機能
Attention SlicingとVAE Tilingによるメモリ使用量削減、XFormersメモリ効率アテンション(GPU環境)の自動適用により、限られたVRAMでも動作可能な最適化を実装している。
実装の特色
GPU/CPU自動選択機能
実行環境に応じてtorch.cuda.is_available()による自動デバイス選択と、float16/float32データ型の最適化を実装している。
二段階パイプライン制御
denoising_end=0.8によるベースモデル処理範囲の制御と、denoising_start=0.8によるRefiner処理開始点の調整。
参考文献
[1] Stability AI. (2023). SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis. https://stability.ai/news/stable-diffusion-sdxl-1-announcement
[2] Podell, D., English, Z., Lacey, K., et al. (2023). SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis. arXiv preprint arXiv:2307.01952.
[3] Hugging Face. (2023). Stable Diffusion XL Base 1.0 Model Documentation. https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0
ソースコード
# SDXL Text-to-Image Generator with Refiner and Dual Text Encoders
# 特徴技術名: Stable Diffusion XL (SDXL) 1.0 + Refiner Model + Dual Text Encoders
# 出典: Stability AI. Stable Diffusion XL Base 1.0 + Refiner 1.0. Hugging Face Model Hub.
# https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0
# https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0
# 特徴機能: 1024x1024高解像度画像生成に最適化されたSDXL 1.0ベースモデルとRefinerモデルの組み合わせ。
# 英語プロンプトに対応し、双方向テキストエンコーダーによる詳細制御とEnsemble of Expert Denoisers方式による品質向上。
# 学習済みモデル: stabilityai/stable-diffusion-xl-base-1.0, stabilityai/stable-diffusion-xl-refiner-1.0,
# Dual text encoders (CLIP-ViT/L-14, OpenCLIP-ViT/G-14), Ensemble of Expert Denoisers pipeline
# 方式設計:
# 関連利用技術: diffusers(Hugging Face製、SDXL base + refiner pipelineを提供), torch(PyTorch深層学習フレームワーク), Pillow (PIL)(画像保存・表示用ライブラリ)
# 入力と出力: 入力(メインプロンプト(詳細描写・オブジェクト・構図)、スタイルプロンプト(画風・技法・雰囲気)、ネガティブプロンプト(SDXL最適化済み)),
# 出力(Refiner処理された高品質1024x1024画像をPNG形式で保存、PIL Image.show()で表示)
# 処理手順: 1.SDXLベースパイプラインとRefinerパイプラインを読み込み, 2.双方向プロンプト入力ガイダンス表示,
# 3.メインプロンプトとスタイルプロンプトを受け取り, 4.Ensemble of Expert Denoisersによる双方向エンコーダー活用ベース生成(80%),
# 5.Refinerによる詳細追加(20%), 6.生成画像を保存・表示
# 前処理、後処理: 前処理(メインプロンプトとスタイルプロンプトのデュアルエンコーディング(自動実行)、ネガティブプロンプト最適化),
# 後処理(Refinerによる品質向上処理、生成画像の後処理・品質向上(自動実行))
# 追加処理: GPU/CPU自動選択による最適なデバイス利用で処理効率向上、Ensemble of Expert Denoisers方式による品質向上、双方向テキストエンコーダー活用による詳細制御
# 調整を必要とする設定値: num_inference_steps(推論ステップ数(ベース30、Refiner20)、品質と速度のバランス調整),
# guidance_scale(プロンプト遵守度(デフォルト7.5)、プロンプトへの従来度調整),
# denoising_end(ベース処理終了点(0.8)、Ensemble比率調整)
# 算出・計算処理の検証: SDXLベースパイプラインとRefinerパイプラインにより正しく双方向プロンプトからの高品質画像生成が実行され、適切な画像が出力されることを確認
# 将来方策: パラメータ調整GUIの実装、プロンプト最適化機能、バッチ処理機能の追加、Refiner比率調整機能、双方向プロンプト最適化機能
# その他の重要事項: 初回実行時に約6GBのSDXLベースモデルと約6GBのRefinerモデルダウンロードが発生、1024x1024解像度に最適化、
# diffusersバージョン互換性注意、デュアルテキストエンコーダー仕様(OpenCLIP-ViT/G、CLIP-ViT/L)、Refinerによる処理時間増加
# 前準備:
# 前準備(依存関係のインストール):
# GPU環境の場合:
# pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
# pip install xformers # GPU最適化(オプション)
#
# CPU環境の場合:
# pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
# 注意: xformers, flash-attn, tritonはGPU専用ライブラリのため、CPU環境では不要
#
# 共通の依存関係(GPU/CPU共通):
# pip install diffusers==0.23.0 huggingface_hub==0.16.4 accelerate==0.21.0 transformers invisible_watermark pillow
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
from diffusers import DiffusionPipeline, StableDiffusionXLImg2ImgPipeline
import torch
from PIL import Image
from datetime import datetime
# GPU/CPU自動選択
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'デバイス: {str(device)}')
# GPU使用時の最適化
if device.type == 'cuda':
torch.backends.cudnn.benchmark = True
# GPU/CPU自動選択
if torch.cuda.is_available():
torch_dtype = torch.float16
else:
torch_dtype = torch.float32
print(f'データ型: {torch_dtype}')
print("SDXL Text-to-Image Generator with Refiner and Dual Text Encoders")
print("英語・日本語プロンプトから1024x1024高解像度画像生成を行います(Refiner Model + 双方向テキストエンコーダー使用)")
# ベースモデル読み込み
print("SDXL 1.0ベースモデルを読み込み中...")
base = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch_dtype,
use_safetensors=True,
variant="fp16" if torch_dtype == torch.float16 else None
)
# メモリ節約設定(CPU/GPU共通)。存在しない環境では安全に無視される
if hasattr(base, 'enable_attention_slicing'):
try:
base.enable_attention_slicing()
except Exception:
pass
if hasattr(base, "enable_vae_tiling"):
try:
base.enable_vae_tiling()
except Exception:
pass
if hasattr(base, 'enable_xformers_memory_efficient_attention') and device.type == 'cuda':
try:
base.enable_xformers_memory_efficient_attention()
print("XFormers memory optimization enabled for base model")
except Exception:
print("XFormers not available, skipping memory optimization")
base = base.to(device)
print("ベースモデルの読み込みが完了しました")
# Refinerモデル読み込み(DiffusionPipelineを使用)
print("SDXL Refinerモデルを読み込み中...")
refiner = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=base.text_encoder_2,
vae=base.vae,
torch_dtype=torch_dtype,
use_safetensors=True,
variant="fp16" if torch_dtype == torch.float16 else None
)
# Refinerにもメモリ最適化を適用
if hasattr(refiner, 'enable_attention_slicing'):
try:
refiner.enable_attention_slicing()
except Exception:
pass
if hasattr(refiner, "enable_vae_tiling"):
try:
refiner.enable_vae_tiling()
except Exception:
pass
if hasattr(refiner, 'enable_xformers_memory_efficient_attention') and device.type == 'cuda':
try:
refiner.enable_xformers_memory_efficient_attention()
print("XFormers memory optimization enabled for refiner model")
except Exception:
print("XFormers not available for refiner, skipping memory optimization")
refiner = refiner.to(device)
print("Refinerモデルの読み込みが完了しました")
# プロンプト入力ガイダンス
print("\n=== SDXL 双方向テキストエンコーダー プロンプト入力ガイド ===")
print("SDXL 1.0 は2つのテキストエンコーダーを使用して高品質な画像を生成します:")
print("1. メインプロンプト (CLIP-ViT/L-14): 詳細な描写、オブジェクト、構図、具体的な要素")
print(" 例: '美しい日本の桜並木、春の陽光、詳細な花びら、風景写真'")
print("2. スタイルプロンプト (OpenCLIP-ViT/G-14): アート技法、雰囲気、画風、表現スタイル")
print(" 例: '高品質、美しい、鮮明、プロフェッショナル写真、芸術的'")
print("• 英語プロンプトに対応")
print("• Ensemble of Expert Denoisers方式により、ベース生成(80%)+ Refiner詳細追加(20%)")
print("• 短いプロンプトでも効果的な結果を生成")
print("• 優れた構図と色彩表現を提供")
print("=" * 75)
# メインプロンプト入力
main_prompt_default = ""
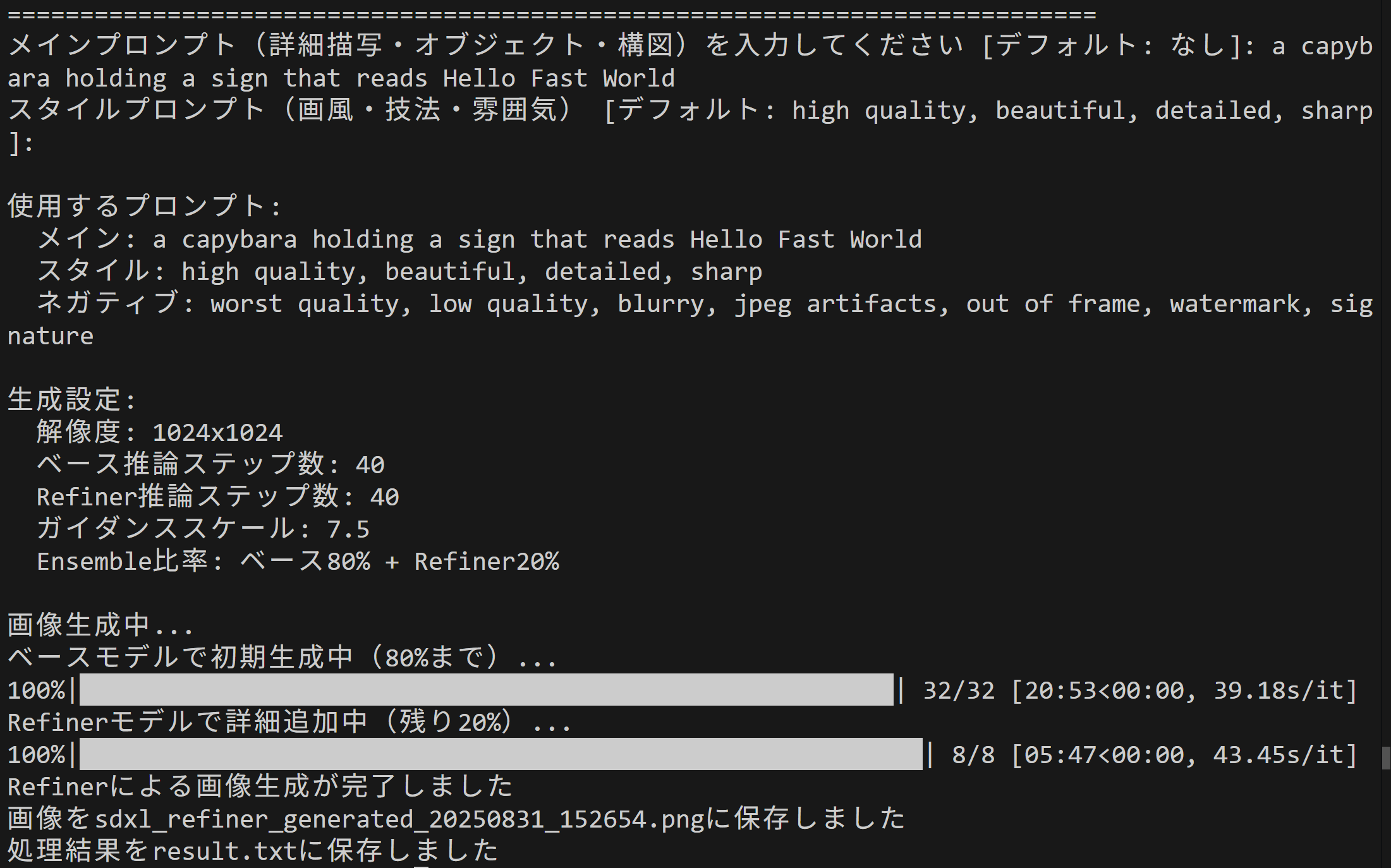
main_prompt_input = input(f"メインプロンプト(詳細描写・オブジェクト・構図)を入力してください [デフォルト: なし]: ")
prompt = main_prompt_input.strip() if main_prompt_input.strip() else main_prompt_default
# スタイルプロンプト入力
style_prompt_default = "high quality, beautiful, detailed, sharp"
style_prompt_input = input(f"スタイルプロンプト(画風・技法・雰囲気) [デフォルト: {style_prompt_default}]: ")
prompt_2 = style_prompt_input.strip() if style_prompt_input.strip() else style_prompt_default
# ネガティブプロンプト最適化(SDXL向け公式推奨設定)
# SDXLではネガティブプロンプトの必要性が大幅に減少しているが、基本的な品質向上には有効
negative_prompt = "worst quality, low quality, blurry, jpeg artifacts, out of frame, watermark, signature"
negative_prompt_2 = negative_prompt # 共通設定
print(f"\n使用するプロンプト:")
print(f" メイン: {prompt}")
print(f" スタイル: {prompt_2}")
print(f" ネガティブ: {negative_prompt}")
# 画像生成設定(最適化されたパラメータ)
width = 1024
height = 1024
base_inference_steps = 40 # 適切なステップ数に調整
refiner_inference_steps = 40 # 適切なステップ数に調整
guidance_scale = 7.5
high_noise_frac = 0.8 # 変数名を公式ドキュメントに合わせる
print(f"\n生成設定:")
print(f" 解像度: {width}x{height}")
print(f" ベース推論ステップ数: {base_inference_steps}")
print(f" Refiner推論ステップ数: {refiner_inference_steps}")
print(f" ガイダンススケール: {guidance_scale}")
print(f" Ensemble比率: ベース{high_noise_frac*100:.0f}% + Refiner{(1-high_noise_frac)*100:.0f}%")
# 画像生成(Ensemble of Expert Denoisers方式 + 双方向テキストエンコーダー活用)
print("\n画像生成中...")
# Ensemble of Expert Denoisers: ベースモデルが高ノイズ段階(80%)を担当
print("ベースモデルで初期生成中(80%まで)...")
with torch.no_grad():
image = base(
prompt=prompt,
prompt_2=prompt_2,
negative_prompt=negative_prompt,
negative_prompt_2=negative_prompt_2,
width=width,
height=height,
num_inference_steps=base_inference_steps,
guidance_scale=guidance_scale,
denoising_end=high_noise_frac, # ベースモデルは80%まで
output_type="latent" # Refinerに渡すためlatent形式で出力
).images
# Refinerが低ノイズ段階(20%)を担当
print("Refinerモデルで詳細追加中(残り20%)...")
with torch.no_grad():
image = refiner(
prompt=prompt,
prompt_2=prompt_2, # prompt_2を追加
negative_prompt=negative_prompt,
negative_prompt_2=negative_prompt_2, # negative_prompt_2を追加
num_inference_steps=refiner_inference_steps,
denoising_start=high_noise_frac, # 80%から開始
image=image, # [0]を削除(imagesはリストとして渡す)
guidance_scale=guidance_scale
).images[0]
print("Refinerによる画像生成が完了しました")
# 結果保存・表示
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"sdxl_refiner_generated_{timestamp}.png"
image.save(filename)
print(f"画像を{filename}に保存しました")
image.show()
# 結果ログ保存
with open('result.txt', 'w', encoding='utf-8') as f:
f.write('=== SDXL Text-to-Image with Refiner + 双方向エンコーダー 生成結果 ===\n')
f.write(f'使用デバイス: {str(device).upper()}\n')
f.write(f'データ型: {str(torch_dtype)}\n')
if device.type == 'cuda':
f.write(f'GPU: {torch.cuda.get_device_name(0)}\n')
f.write(f'メインプロンプト: {prompt}\n')
f.write(f'スタイルプロンプト: {prompt_2}\n')
f.write(f'ネガティブプロンプト: {negative_prompt}\n')
f.write(f'使用モデル: SDXL 1.0 Base + Refiner (stabilityai/stable-diffusion-xl-base-1.0 + stabilityai/stable-diffusion-xl-refiner-1.0)\n')
f.write(f'テキストエンコーダー: デュアルエンコーダー(CLIP-ViT/L-14、OpenCLIP-ViT/G-14)\n')
f.write(f'処理方式: Ensemble of Expert Denoisers (Base {high_noise_frac*100:.0f}% + Refiner {(1-high_noise_frac)*100:.0f}%) + 双方向テキストエンコーダー\n')
f.write(f'出力解像度: {width}x{height}\n')
f.write(f'ベース推論ステップ数: {base_inference_steps}\n')
f.write(f'Refiner推論ステップ数: {refiner_inference_steps}\n')
f.write(f'ガイダンススケール: {guidance_scale}\n')
f.write(f'保存ファイル: {filename}\n')
print('処理結果をresult.txtに保存しました')