Stable Diffusion 3.5 Large による Text-to-Image (ソースコードと実行結果)

Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
インストール済みの場合は実行不要。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent --accept-source-agreements --accept-package-agreements
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】
Python の公式ページ: https://www.python.org/
AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AI エディタの利用を推奨する。ここでは,Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行して、Windsurfをシステム全体にインストールする。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
winget install --scope machine --id Codeium.Windsurf -e --silent --accept-source-agreements --accept-package-agreements【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
必要なライブラリをシステム領域にインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する
pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
pip install diffusers huggingface_hub transformers accelerate pillow
HugggingFace トークン取得
https://huggingface.co/settings/tokens にアクセス. HugggingFace トークンの設定.保存の支援ツールは別ページ (https://www/kkaneko.jp/ai/labo/hf.html)で紹介.
Stable Diffusion 3.5 Large による Text-to-Image プログラム
概要
このプログラムは、Stable Diffusion 3.5 LargeおよびSDXL 1.0モデルを使用して、テキストプロンプトから画像を生成する。Hugging FaceのDiffusersライブラリ[4]を使用し、複数の画像生成モデルを操作できる。ユーザーはモデルを選択し、プロンプトを入力することで、画像を生成できる。
主要技術
Stable Diffusion 3.5
Stability AIが2024年に公開した画像生成モデル[1]。Rectified Flowベースの拡散モデルであり、Flow Matchingアルゴリズム[2]を採用している。本プログラムでは、通常版(28ステップ)とTurbo版(4ステップ)の両方に対応している。
SDXL 1.0
Stable Diffusion XL(SDXL)は、高解像度画像生成に対応したモデル[3]である。U-Netアーキテクチャの改良により、1024×1024ピクセルのネイティブ解像度での生成を可能にしている。
Flow Matching Scheduler
SD3.5で採用されているFlowMatchEulerDiscreteSchedulerは、Ordinary Differential Equationを離散的に解く手法である[2]。
技術的特徴
自動デバイス選択とメモリ最適化
プログラムはCUDA対応GPUの有無を自動検出し、適切なデバイスとデータ型を選択する。GPU環境ではbfloat16またはfloat16精度を使用し、CPU環境ではfloat32にフォールバックする。メモリ効率化のため、model_cpu_offload機能とVAEタイリングを有効化し、大規模モデルの実行を可能にしている。
モデル設定の辞書管理
MODEL_CONFIGSディクショナリにより、各モデルの設定を一元管理している。推論ステップ数、ガイダンススケール、スケジューラークラスなどのパラメータを事前定義することで、モデル固有の設定を自動適用する。この設計により、新規モデルの追加が容易になっている。
Hugging Face認証の統合
環境変数HF_TOKENを通じたトークン管理を実装し、ゲート付きモデルへのアクセスを自動化している。model_info APIを使用してアクセス権限を事前確認し、必要に応じてライセンス同意の案内を表示する。
実装の特色
対話形式のインターフェース
ユーザーとの対話を通じて、モデル選択、プロンプト入力、パラメータ設定を行う。各段階で説明を提供し、操作を支援する設計となっている。サンプルプロンプトの提供により、動作確認が可能である。
ネガティブプロンプトの動的制御
モデルごとのネガティブプロンプト対応状況を設定で管理し、SD3.5 Turboのような非対応モデルでは自動的に無効化する。対応モデルではデフォルト値を提供し、ユーザーによるカスタマイズも可能にしている。
参考文献
[1] Stability AI. (2024). Stable Diffusion 3.5 Large. Hugging Face Model Repository. https://huggingface.co/stabilityai/stable-diffusion-3.5-large
[2] Esser, P., et al. (2024). Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. arXiv:2403.03206. https://arxiv.org/abs/2403.03206
[3] Podell, D., et al. (2023). SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis. arXiv:2307.01952. https://arxiv.org/abs/2307.01952
[4] Hugging Face. (2024). Diffusers Documentation. https://huggingface.co/docs/diffusers
ソースコード
# プログラム名: Stable Diffusion 3.5 Large による Text-to-Image プログラム
# pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
# pip install diffusers huggingface_hub transformers accelerate pillow
import os
import sys
import subprocess
import torch
from diffusers import StableDiffusion3Pipeline, FlowMatchEulerDiscreteScheduler, StableDiffusionXLPipeline
from huggingface_hub import login, model_info
from huggingface_hub.utils import RepositoryNotFoundError, GatedRepoError
def print_dependency_guide():
print("\n依存関係インストールガイド")
print("GPU環境:")
print(" 1. PyTorch公式サイトからCUDA対応版を選択してインストール")
print(" https://pytorch.org/get-started/locally/")
print(" 2. 任意: pip install xformers")
print("CPU環境:")
print(" pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu")
print("共通:")
print(" pip install 'diffusers>=0.30.0' huggingface_hub transformers accelerate pillow")
# モデル固有の設定を定数化
MODEL_CONFIGS = {
"sd3.5-large": {
"model_id": "stabilityai/stable-diffusion-3.5-large",
"pipeline_class": StableDiffusion3Pipeline,
"default_dtype": torch.bfloat16,
"cpu_dtype": torch.float32,
"num_inference_steps": 28, # 公式推奨値
"guidance_scale": 3.5, # 公式推奨値
"width": 1024, # 1メガピクセル対応
"height": 1024, # 1メガピクセル対応
"scheduler_class": FlowMatchEulerDiscreteScheduler, # SD3.5に適したスケジューラー
"enable_cpu_offload": True,
"enable_vae_tiling": True,
"supports_negative_prompt": True, # ネガティブプロンプトをサポート
"model_name": "SD3.5 Large",
"model_url": "https://huggingface.co/stabilityai/stable-diffusion-3.5-large",
"setup_message": "SD3.5 Largeを使用する前に以下を確認してください:\n"
"1. https://huggingface.co/stabilityai/stable-diffusion-3.5-large にアクセス\n"
"2. 「Agree and access repository」ボタンをクリックしてライセンスに同意\n"
"3. アクセスが承認されるまで待つ\n"
"4. pip install -U diffusers を実行済みであること",
"sample_prompt": "A capybara holding a sign that reads Hello World", # 公式例
"model_description": "最新・高品質・英語・1メガピクセル"
},
"sd3.5-large-turbo": {
"model_id": "stabilityai/stable-diffusion-3.5-large-turbo",
"pipeline_class": StableDiffusion3Pipeline,
"default_dtype": torch.bfloat16,
"cpu_dtype": torch.float32,
"num_inference_steps": 4,
"guidance_scale": 0.0, # Turboモデルはguidance不要(公式推奨値)
"width": 1024, # 1メガピクセル対応
"height": 1024, # 1メガピクセル対応
"scheduler_class": FlowMatchEulerDiscreteScheduler,
"enable_cpu_offload": True,
"enable_vae_tiling": True,
"supports_negative_prompt": False, # Turboモデルはネガティブプロンプト不使用
"model_name": "SD3.5 Large Turbo",
"model_url": "https://huggingface.co/stabilityai/stable-diffusion-3.5-large-turbo",
"setup_message": "SD3.5 Large Turboを使用する前に以下を確認してください:\n"
"1. https://huggingface.co/stabilityai/stable-diffusion-3.5-large-turbo にアクセス\n"
"2. 「Agree and access repository」ボタンをクリックしてライセンスに同意\n"
"3. アクセスが承認されるまで待つ\n"
"4. pip install -U diffusers を実行済みであること",
"sample_prompt": "A capybara holding a sign that reads Hello Fast World", # 公式例
"model_description": "超高速・英語・4ステップ生成・1メガピクセル"
},
# SDXL 1.0 モデル構成
"sdxl-1.0": {
"model_id": "stabilityai/stable-diffusion-xl-base-1.0",
"pipeline_class": StableDiffusionXLPipeline,
"default_dtype": torch.float16, # SDXLはGPUでfloat16推奨
"cpu_dtype": torch.float32,
"num_inference_steps": 50,
"guidance_scale": 7.5,
"width": 1024, # 表示用(SDXLでは指定なしでも既定1024x1024)
"height": 1024,
"scheduler_class": "default", # SDXLはデフォルトスケジューラーを使用
"enable_cpu_offload": True,
"enable_vae_tiling": True,
"supports_negative_prompt": True, # ネガティブプロンプトをサポート
"model_name": "SDXL 1.0",
"model_url": "https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0",
"setup_message": "SDXL 1.0は通常、追加のライセンス同意や認証は不要です。\n"
"pip install -U diffusers を実行済みであることを確認してください。",
"sample_prompt": "A capybara in watercolor style, soft pastel colors",
"model_description": "従来SDXL・1024x1024・英語"
}
}
def setup_token():
print("\nトークンの取得方法:")
print("1. https://huggingface.co/settings/tokens にアクセス.ログインしていない場合はログイン")
print("2. 「Create new token」をクリック")
print("3. Token nameを入力(例: my-app-token)")
print("4. Token typeで「Write」を選択")
print("5. 「Create token」をクリック")
print("6. 生成されたトークンをコピー(「Copy」をクリック)")
# トークン入力を求める
token = input("\nトークンを入力してください: ")
# Windowsの場合、setxコマンドで永続的に設定
try:
subprocess.run(['setx', 'HF_TOKEN', token], check=True)
print("\n環境変数を設定しました。新しいコマンドプロンプトを開いて再実行してください。VSCode や Windsurf などの開発環境を用いている場合には、開発環境を終了し、再度起動してください")
except subprocess.CalledProcessError:
print("\n環境変数の設定に失敗しました。")
sys.exit(0)
# トークンの存在確認
hf_token = os.environ.get("HF_TOKEN")
if not hf_token:
print("HF_TOKEN環境変数が設定されていません。")
setup_token()
# huggingface_hubでログイン(トークンを保存)
try:
login(token=hf_token, add_to_git_credential=False)
except Exception:
print("トークンが無効です。")
setup_token()
# 依存関係インストールガイドの表示(任意)
show_guide = input("\n依存関係インストールガイドを表示しますか? [y/N]: ").strip().lower()
if show_guide == 'y':
print_dependency_guide()
# モデル選択メニューを表示し、ユーザーの選択を返す
print("\n使用するモデルを選択してください:")
model_keys = list(MODEL_CONFIGS.keys())
for i, key in enumerate(model_keys, 1):
config = MODEL_CONFIGS[key]
print(f"{i}. {config['model_name']} ({config['model_description']})")
print(f" モデルID: {config['model_id']}")
print(f" URL: {config['model_url']}")
while True:
try:
choice = input("\n番号を入力してください (1-{}): ".format(len(model_keys)))
choice_idx = int(choice) - 1
if 0 <= choice_idx < len(model_keys):
selected_model = model_keys[choice_idx]
print(f"\n{MODEL_CONFIGS[selected_model]['model_name']}を選択しました。")
break
else:
print("有効な番号を入力してください。")
except ValueError:
print("数字を入力してください。")
model_config = MODEL_CONFIGS[selected_model]
# モデルへのアクセス権限を確認
try:
info = model_info(model_config["model_id"], token=hf_token)
access_ok, error_msg = True, None
except GatedRepoError:
access_ok, error_msg = False, "ライセンス同意が必要です"
except RepositoryNotFoundError:
access_ok, error_msg = False, "モデルが見つかりません"
except Exception as e:
access_ok, error_msg = False, f"アクセスエラー: {str(e)}"
if not access_ok:
print(f"\nモデルへのアクセスに問題があります: {error_msg}")
print(model_config["setup_message"])
input("\n準備ができたらEnterキーを押してください...")
else:
print(f"\n{model_config['model_name']}へのアクセスが確認できました。")
# デバイスの自動選択
device = "cuda" if torch.cuda.is_available() else "cpu"
dtype = model_config["default_dtype"] if device == "cuda" else model_config["cpu_dtype"]
if device == "cpu":
print("GPUが利用できないため、CPUで実行します。処理に時間がかかる場合があります。")
# デバイス名とdtypeの明示出力
if device == "cuda":
try:
print(f"デバイス: GPU ({torch.cuda.get_device_name(0)})")
except Exception:
print("デバイス: GPU")
else:
print("デバイス: CPU")
print(f"データ型: {dtype}")
try:
# パイプラインの読み込み
print("モデルの読み込み中...")
from_pretrained_kwargs = {
"torch_dtype": dtype,
"token": hf_token,
"use_safetensors": True
}
# SDXL + GPU時にvariant設定を適切に処理
if selected_model.startswith("sdxl") and device == "cuda":
if dtype == torch.float16:
from_pretrained_kwargs["variant"] = "fp16"
# bfloat16の場合は特別な処理は不要(デフォルトで対応)
pipe = model_config["pipeline_class"].from_pretrained(
model_config["model_id"],
**from_pretrained_kwargs
)
pipe = pipe.to(device)
# メモリ最適化
if device == "cuda" and model_config.get("enable_cpu_offload", False):
pipe.enable_model_cpu_offload()
if model_config.get("enable_vae_tiling", False) and hasattr(pipe, 'vae'):
pipe.vae.enable_tiling()
# attention slicing と xFormers(可能な場合のみ)
if hasattr(pipe, "enable_attention_slicing"):
try:
pipe.enable_attention_slicing()
except Exception:
pass
if device == "cuda" and hasattr(pipe, "enable_xformers_memory_efficient_attention"):
try:
pipe.enable_xformers_memory_efficient_attention()
print("XFormers memory optimization enabled")
except Exception:
print("XFormers not available, skipping memory optimization")
# VAEの精度設定
if hasattr(pipe, 'vae'):
pipe.vae.to(dtype)
# スケジューラーの設定
if "scheduler_class" in model_config:
if model_config["scheduler_class"] == "default":
# SDXLはデフォルトのスケジューラーを使用
print("デフォルトのスケジューラーを使用します")
elif model_config["scheduler_class"] is not None:
# カスタムスケジューラーを設定
pipe.scheduler = model_config["scheduler_class"].from_config(pipe.scheduler.config)
print(f"カスタムスケジューラー({model_config['scheduler_class'].__name__})を設定しました")
print("モデルの読み込みが完了しました。")
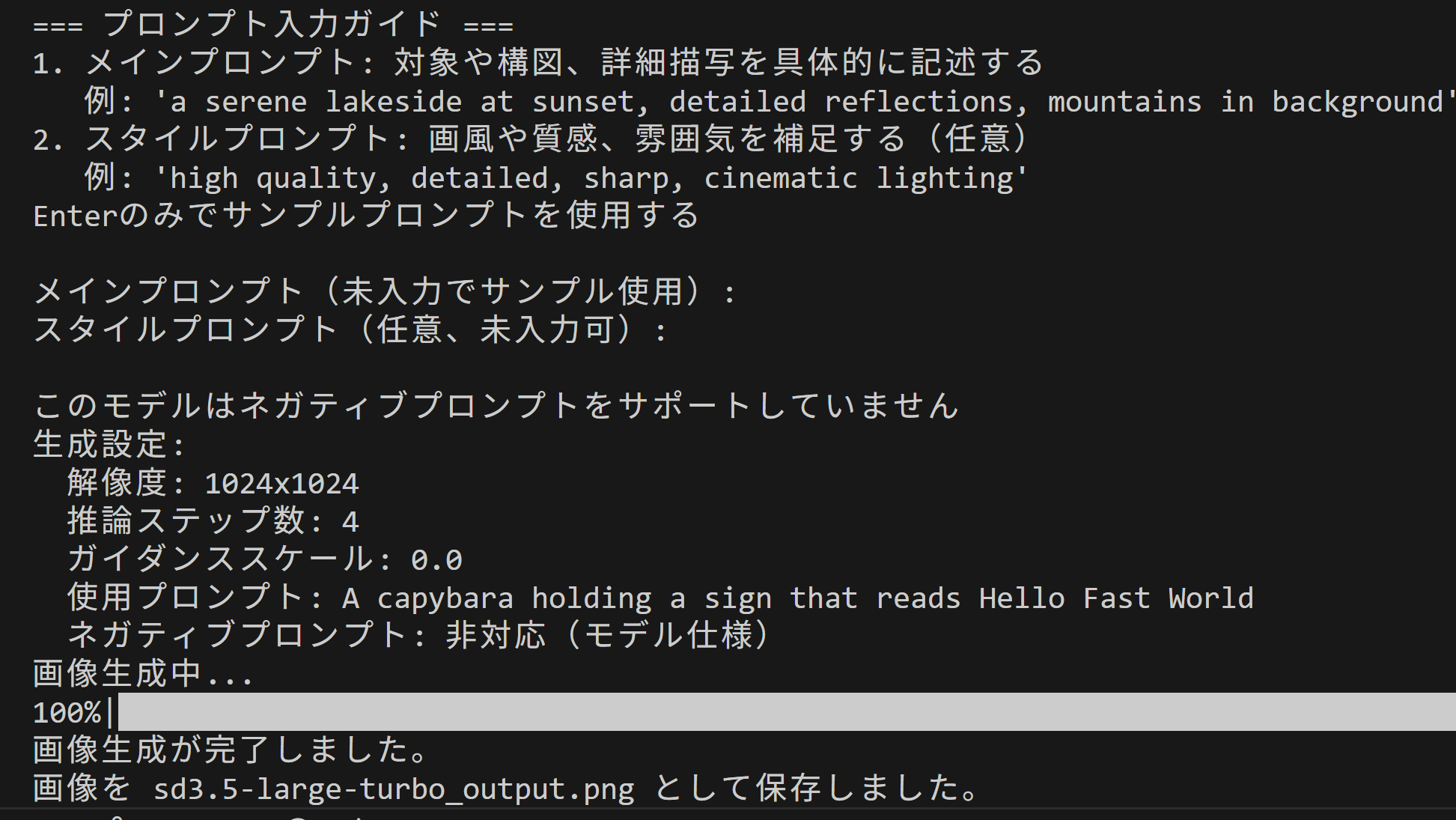
# プロンプト入力ガイド(メイン+スタイル結合)
print("\n=== プロンプト入力ガイド ===")
print("1. メインプロンプト: 対象や構図、詳細描写を具体的に記述する")
print(" 例: 'a serene lakeside at sunset, detailed reflections, mountains in background'")
print("2. スタイルプロンプト: 画風や質感、雰囲気を補足する(任意)")
print(" 例: 'high quality, detailed, sharp, cinematic lighting'")
print("Enterのみでサンプルプロンプトを使用する")
main_prompt_in = input("\nメインプロンプト(未入力でサンプル使用): ").strip()
style_prompt_in = input("スタイルプロンプト(任意、未入力可): ").strip()
if main_prompt_in:
combined_prompt = f"{main_prompt_in}, {style_prompt_in}" if style_prompt_in else main_prompt_in
else:
combined_prompt = model_config["sample_prompt"]
# ネガティブプロンプトの判定ロジックを修正
use_neg_prompt = model_config.get("supports_negative_prompt", True)
if use_neg_prompt:
default_negative_prompt = (
"low quality, worst quality, blurry, out of frame, watermark, signature, jpeg artifacts, "
"text, logo, extra fingers, extra limbs, extra digits, deformed, disfigured, poorly drawn hands, "
"bad anatomy, cropped, duplicate"
)
print("\nネガティブプロンプトについて")
print("未入力の場合、以下のデフォルト値が使用される")
print(f"デフォルトのネガティブプロンプト: {default_negative_prompt}")
neg_in = input("\nネガティブプロンプト(任意、上書き可): ").strip()
if neg_in:
negative_prompt_value = neg_in
print(f"ネガティブプロンプトを使用: {negative_prompt_value}")
else:
negative_prompt_value = default_negative_prompt
print("デフォルトのネガティブプロンプトを使用する")
print(f"使用するデフォルトのネガティブプロンプト: {negative_prompt_value}")
else:
negative_prompt_value = None
print("\nこのモデルはネガティブプロンプトをサポートしていません")
# 画像生成パラメータの準備
generation_params = {
"prompt": combined_prompt,
"num_inference_steps": model_config["num_inference_steps"],
"guidance_scale": model_config["guidance_scale"],
}
# ネガティブプロンプトの追加
if use_neg_prompt:
generation_params["negative_prompt"] = negative_prompt_value
# 解像度設定(SD3.5とSDXL両方に適用)
if "width" in model_config and "height" in model_config:
generation_params.update({
"width": model_config["width"],
"height": model_config["height"],
})
# 実行前の設定表示(確認用)
print("生成設定:")
if "width" in model_config and "height" in model_config:
print(f" 解像度: {model_config['width']}x{model_config['height']}")
print(f" 推論ステップ数: {model_config['num_inference_steps']}")
print(f" ガイダンススケール: {model_config['guidance_scale']}")
print(f" 使用プロンプト: {combined_prompt}")
if use_neg_prompt:
print(f" ネガティブプロンプト: {negative_prompt_value}")
else:
if model_config.get("supports_negative_prompt", True):
print(" ネガティブプロンプト: 未使用(ユーザー選択)")
else:
print(" ネガティブプロンプト: 非対応(モデル仕様)")
# 画像生成
print("画像生成中...")
with torch.no_grad():
image = pipe(**generation_params).images[0]
print("画像生成が完了しました。")
# 画像を保存(モデル名を含むファイル名)
output_filename = f"{selected_model}_output.png"
image.save(output_filename)
print(f"画像を {output_filename} として保存しました。")
try:
image.show()
except Exception:
pass
except Exception as e:
print(f"画像生成に失敗しました: {e}")
if any(s in str(e).lower() for s in ["kmp_duplicate_lib_ok", "libiomp5", "openmp"]):
print("\nOpenMP関連のエラーが疑われる。暫定対処として以下を試すことがある。")
print(" Windows: setx KMP_DUPLICATE_LIB_OK TRUE")
print(" Linux/macOS: export KMP_DUPLICATE_LIB_OK=TRUE")
print("注意: 恒久対策ではなく、可能であれば重複するOpenMPランタイムの解消を推奨する")
response = input("\nトークンを再設定しますか? [Y/n]: ")
if response.lower() != 'n':
setup_token()