Stable Diffusion 3.5 Large による Text-to-Image (GUI付き)(ソースコードと実行結果)

Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
インストール済みの場合は実行不要。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent --accept-source-agreements --accept-package-agreements
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】
Python の公式ページ: https://www.python.org/
AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AI エディタの利用を推奨する。ここでは,Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行して、Windsurfをシステム全体にインストールする。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
winget install --scope machine --id Codeium.Windsurf -e --silent --accept-source-agreements --accept-package-agreements【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
必要なライブラリをシステム領域にインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する
pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
pip install diffusers huggingface_hub transformers accelerate pillow
HugggingFace トークン取得
https://huggingface.co/settings/tokens にアクセス. HugggingFace トークンの設定.保存の支援ツールは別ページ (https://www/kkaneko.jp/ai/labo/hf.html)で紹介.
Stable Diffusion 3.5 Large による Text-to-Image プログラム(GUI付き)
概要
このプログラムは、Stable Diffusion 3.5 LargeおよびSDXL 1.0モデルを使用して、テキストプロンプトから画像を生成する。Hugging FaceのDiffusersライブラリ[4]を使用し、複数の画像生成モデルを操作できる。ユーザーはモデルを選択し、プロンプトを入力することで、画像を生成できる。
主要技術
Stable Diffusion 3.5
Stability AIが2024年に公開した画像生成モデル[1]。Rectified Flowベースの拡散モデルであり、Flow Matchingアルゴリズム[2]を採用している。本プログラムでは、通常版(28ステップ)とTurbo版(4ステップ)の両方に対応している。
SDXL 1.0
Stable Diffusion XL(SDXL)は、高解像度画像生成に対応したモデル[3]である。U-Netアーキテクチャの改良により、1024×1024ピクセルのネイティブ解像度での生成を可能にしている。
Flow Matching Scheduler
SD3.5で採用されているFlowMatchEulerDiscreteSchedulerは、Ordinary Differential Equationを離散的に解く手法である[2]。
技術的特徴
自動デバイス選択とメモリ最適化
プログラムはCUDA対応GPUの有無を自動検出し、適切なデバイスとデータ型を選択する。GPU環境ではbfloat16またはfloat16精度を使用し、CPU環境ではfloat32にフォールバックする。メモリ効率化のため、model_cpu_offload機能とVAEタイリングを有効化し、大規模モデルの実行を可能にしている。
モデル設定の辞書管理
MODEL_CONFIGSディクショナリにより、各モデルの設定を一元管理している。推論ステップ数、ガイダンススケール、スケジューラークラスなどのパラメータを事前定義することで、モデル固有の設定を自動適用する。この設計により、新規モデルの追加が容易になっている。
Hugging Face認証の統合
環境変数HF_TOKENを通じたトークン管理を実装し、ゲート付きモデルへのアクセスを自動化している。model_info APIを使用してアクセス権限を事前確認し、必要に応じてライセンス同意の案内を表示する。
実装の特色
ネガティブプロンプトの動的制御
モデルごとのネガティブプロンプト対応状況を設定で管理し、SD3.5 Turboのような非対応モデルでは自動的に無効化する。対応モデルではデフォルト値を提供し、ユーザーによるカスタマイズも可能にしている。
参考文献
[1] Stability AI. (2024). Stable Diffusion 3.5 Large. Hugging Face Model Repository. https://huggingface.co/stabilityai/stable-diffusion-3.5-large
[2] Esser, P., et al. (2024). Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. arXiv:2403.03206. https://arxiv.org/abs/2403.03206
[3] Podell, D., et al. (2023). SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis. arXiv:2307.01952. https://arxiv.org/abs/2307.01952
[4] Hugging Face. (2024). Diffusers Documentation. https://huggingface.co/docs/diffusers
ソースコード
# プログラム名: Stable Diffusion 3.5 Large による Text-to-Image プログラム (GUI版) - バグ修正版
# pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
# pip install diffusers huggingface_hub transformers accelerate pillow
import os
import sys
import subprocess
import torch
import gc
import tkinter as tk
from tkinter import ttk, scrolledtext, filedialog, messagebox
from diffusers import StableDiffusion3Pipeline, FlowMatchEulerDiscreteScheduler, StableDiffusionXLPipeline
from huggingface_hub import login, model_info
from huggingface_hub.utils import RepositoryNotFoundError, GatedRepoError
from PIL import Image, ImageTk
import threading
# モデル固有の設定を定数化
MODEL_CONFIGS = {
"sd3.5-large": {
"model_id": "stabilityai/stable-diffusion-3.5-large",
"pipeline_class": StableDiffusion3Pipeline,
"default_dtype": torch.bfloat16,
"cpu_dtype": torch.float32,
"num_inference_steps": 28, # 公式推奨値
"guidance_scale": 3.5, # 公式推奨値
"width": 1024, # 1メガピクセル対応
"height": 1024, # 1メガピクセル対応
"scheduler_class": FlowMatchEulerDiscreteScheduler, # SD3.5に適したスケジューラー
"enable_cpu_offload": True,
"enable_vae_tiling": True,
"model_name": "SD3.5 Large",
"model_url": "https://huggingface.co/stabilityai/stable-diffusion-3.5-large",
"setup_message": "SD3.5 Largeを使用する前に以下を確認してください:\n"
"1. https://huggingface.co/stabilityai/stable-diffusion-3.5-large にアクセス\n"
"2. 「Agree and access repository」ボタンをクリックしてライセンスに同意\n"
"3. アクセスが承認されるまで待つ\n"
"4. pip install -U diffusers を実行済みであること",
"sample_prompt": "A capybara holding a sign that reads Hello World", # 公式例
"model_description": "最新・高品質・英語・1メガピクセル",
"supports_negative_prompt": True, # ネガティブプロンプトをサポート
},
"sd3.5-large-turbo": {
"model_id": "stabilityai/stable-diffusion-3.5-large-turbo",
"pipeline_class": StableDiffusion3Pipeline,
"default_dtype": torch.bfloat16,
"cpu_dtype": torch.float32,
"num_inference_steps": 4,
"guidance_scale": 0.0, # Turboモデルはguidance不要(公式推奨値)
"width": 1024, # 1メガピクセル対応
"height": 1024, # 1メガピクセル対応
"scheduler_class": FlowMatchEulerDiscreteScheduler,
"enable_cpu_offload": True,
"enable_vae_tiling": True,
"model_name": "SD3.5 Large Turbo",
"model_url": "https://huggingface.co/stabilityai/stable-diffusion-3.5-large-turbo",
"setup_message": "SD3.5 Large Turboを使用する前に以下を確認してください:\n"
"1. https://huggingface.co/stabilityai/stable-diffusion-3.5-large-turbo にアクセス\n"
"2. 「Agree and access repository」ボタンをクリックしてライセンスに同意\n"
"3. アクセスが承認されるまで待つ\n"
"4. pip install -U diffusers を実行済みであること",
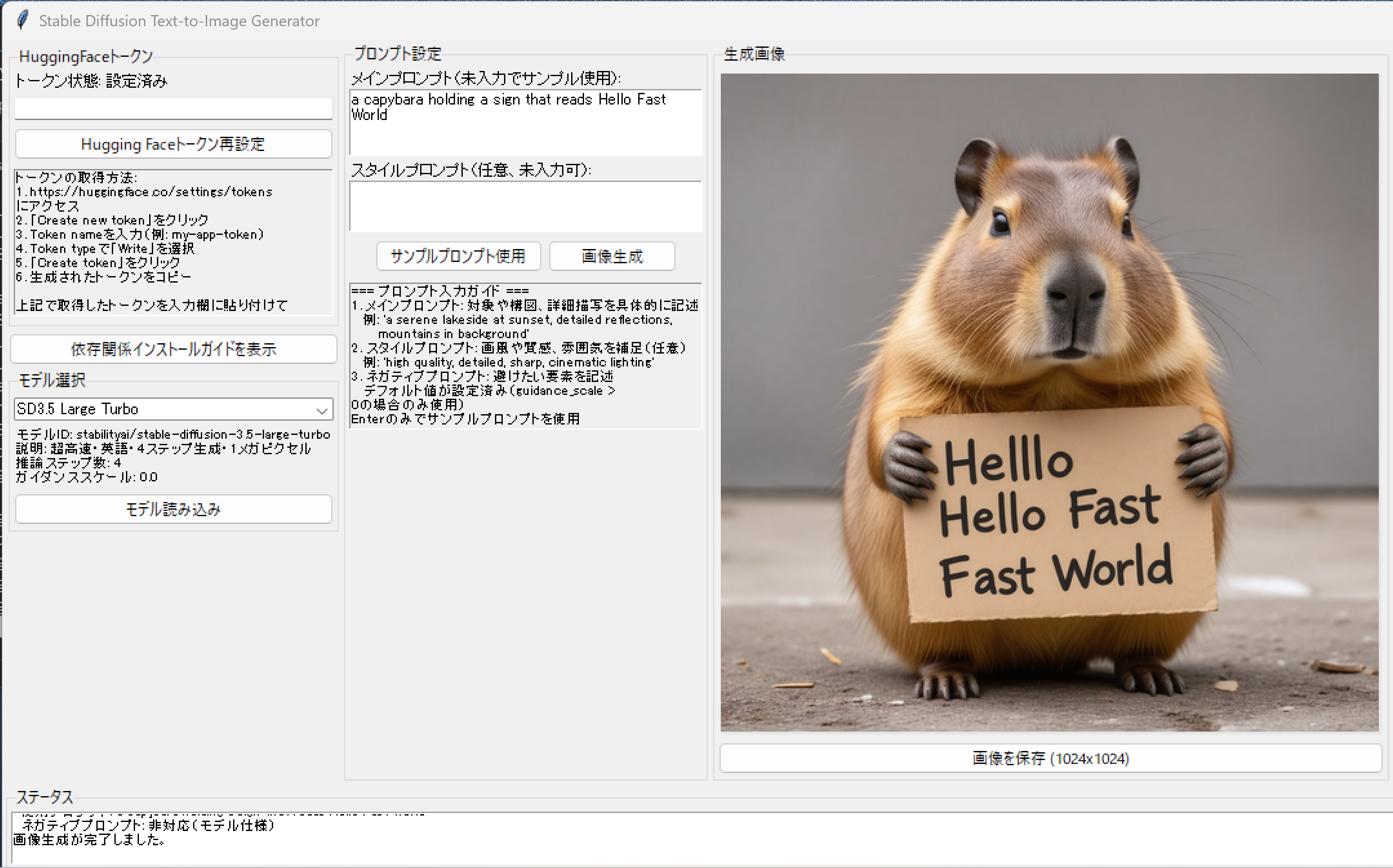
"sample_prompt": "A capybara holding a sign that reads Hello Fast World", # 公式例
"model_description": "超高速・英語・4ステップ生成・1メガピクセル",
"supports_negative_prompt": False, # Turboモデルはネガティブプロンプト不使用
},
# SDXL 1.0 モデル構成
"sdxl-1.0": {
"model_id": "stabilityai/stable-diffusion-xl-base-1.0",
"pipeline_class": StableDiffusionXLPipeline,
"default_dtype": torch.float16, # SDXLはGPUでfloat16推奨
"cpu_dtype": torch.float32,
"num_inference_steps": 50,
"guidance_scale": 7.5,
"width": 1024, # SDXLでも明示的に指定
"height": 1024,
"scheduler_class": "default", # SDXLは既定スケジューラーを利用
"enable_cpu_offload": True,
"enable_vae_tiling": True,
"model_name": "SDXL 1.0",
"model_url": "https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0",
"setup_message": "SDXL 1.0は通常、追加のライセンス同意や認証は不要です。\n"
"pip install -U diffusers を実行済みであることを確認してください。",
"sample_prompt": "A capybara in watercolor style, soft pastel colors",
"model_description": "従来SDXL・1024x1024・英語",
"variant_fp16_on_cuda": True, # GPU時にvariant='fp16'を付与
"supports_negative_prompt": True, # ネガティブプロンプトをサポート
}
}
class StableDiffusionGUI:
def __init__(self, root):
self.root = root
self.root.title("Stable Diffusion Text-to-Image Generator")
self.root.geometry("1400x650")
self.root.resizable(False, False) # サイズ固定
# インスタンス変数の初期化
self.pipe = None
self.selected_model = None
self.generated_image = None
self.hf_token = os.environ.get("HF_TOKEN")
self.is_processing = False
self.negative_prompt_widgets = [] # ネガティブプロンプト関連ウィジェット
self.processing_lock = threading.Lock() # 並行処理制御用
# UIの構築
self.setup_ui()
# 初期メッセージの表示
self.show_initial_messages()
# ウィンドウクローズ時のクリーンアップ
self.root.protocol("WM_DELETE_WINDOW", self.on_closing)
def on_closing(self):
"""ウィンドウクローズ時のクリーンアップ処理"""
try:
self.cleanup_resources()
finally:
self.root.destroy()
def cleanup_resources(self):
"""リソースのクリーンアップ"""
if self.pipe is not None:
try:
del self.pipe
self.pipe = None
# メモリ解放
if torch.cuda.is_available():
torch.cuda.empty_cache()
gc.collect()
self.log_message("モデルのメモリを解放しました。")
except Exception as e:
self.log_message(f"メモリ解放中にエラー: {e}")
def setup_ui(self):
# メインフレーム
main_frame = ttk.Frame(self.root, padding="3")
main_frame.pack(fill=tk.BOTH, expand=True)
# 上部:3列構成
top_frame = ttk.Frame(main_frame)
top_frame.pack(fill=tk.BOTH, expand=True)
# 左列:トークンとモデル設定
left_col = ttk.Frame(top_frame)
left_col.pack(side=tk.LEFT, fill=tk.BOTH, padx=2)
# トークン設定
token_frame = ttk.LabelFrame(left_col, text="HuggingFaceトークン", padding="2")
token_frame.pack(fill=tk.X, pady=2)
self.token_status_label = ttk.Label(token_frame, text="トークン状態: 未設定", font=("", 9))
self.token_status_label.pack(anchor=tk.W)
token_input_frame = ttk.Frame(token_frame)
token_input_frame.pack(fill=tk.X, pady=2)
self.token_entry = ttk.Entry(token_input_frame, width=30, show="*", font=("", 9))
self.token_entry.pack(fill=tk.X, pady=2)
ttk.Button(token_frame, text="Hugging Faceトークン再設定", command=self.set_token).pack(fill=tk.X, pady=2)
# トークン取得ガイド
token_guide_text = """トークンの取得方法:
1. https://huggingface.co/settings/tokens にアクセス
2. 「Create new token」をクリック
3. Token nameを入力(例: my-app-token)
4. Token typeで「Write」を選択
5. 「Create token」をクリック
6. 生成されたトークンをコピー
モデル使用前の準備:
• SD3.5 Large/Turbo使用前に各モデルページで
「Agree and access repository」をクリック
• アクセス承認まで待機
• pip install -U diffusers を実行済みであること
上記で取得したトークンを入力欄に貼り付けて
「Hugging Faceトークン再設定」をクリック"""
token_guide_label = tk.Text(token_frame, height=10, width=40, wrap=tk.WORD, font=("", 8), bg='#f0f0f0')
token_guide_label.insert('1.0', token_guide_text)
token_guide_label.config(state=tk.DISABLED)
token_guide_label.pack(fill=tk.X, pady=5)
# 依存関係ガイド表示ボタン
ttk.Button(left_col, text="依存関係インストールガイドを表示", command=self.show_dependency_guide).pack(fill=tk.X, pady=2)
# モデル選択
model_frame = ttk.LabelFrame(left_col, text="モデル選択", padding="2")
model_frame.pack(fill=tk.X, pady=2)
self.model_var = tk.StringVar()
self.model_combo = ttk.Combobox(model_frame, textvariable=self.model_var, state="readonly", width=35, font=("", 9))
self.model_combo['values'] = [MODEL_CONFIGS[key]['model_name'] for key in MODEL_CONFIGS.keys()]
self.model_combo.pack(fill=tk.X, pady=2)
self.model_combo.bind('<<ComboboxSelected>>', self.on_model_selected)
self.model_info_label = ttk.Label(model_frame, text="モデルを選択してください", font=("", 8), wraplength=280)
self.model_info_label.pack(anchor=tk.W, pady=2)
ttk.Button(model_frame, text="モデル読み込み", command=self.load_model).pack(fill=tk.X, pady=2)
# 中央列:プロンプト設定
center_col = ttk.Frame(top_frame)
center_col.pack(side=tk.LEFT, fill=tk.BOTH, padx=2)
self.prompt_frame = ttk.LabelFrame(center_col, text="プロンプト設定", padding="2")
self.prompt_frame.pack(fill=tk.BOTH, expand=True)
# メインプロンプト
ttk.Label(self.prompt_frame, text="メインプロンプト(未入力でサンプル使用):", font=("", 9)).pack(anchor=tk.W)
self.main_prompt_text = tk.Text(self.prompt_frame, height=4, width=45, wrap=tk.WORD, font=("", 9))
self.main_prompt_text.pack(fill=tk.X, pady=(0,3))
# スタイルプロンプト
ttk.Label(self.prompt_frame, text="スタイルプロンプト(任意、未入力可):", font=("", 9)).pack(anchor=tk.W)
self.style_prompt_text = tk.Text(self.prompt_frame, height=3, width=45, wrap=tk.WORD, font=("", 9))
self.style_prompt_text.pack(fill=tk.X, pady=(0,3))
# ネガティブプロンプト(初期状態では表示)
self.negative_label = ttk.Label(self.prompt_frame, text="ネガティブプロンプト:", font=("", 9))
self.negative_label.pack(anchor=tk.W)
self.negative_prompt_text = tk.Text(self.prompt_frame, height=3, width=45, wrap=tk.WORD, font=("", 9))
self.negative_prompt_text.pack(fill=tk.X, pady=(0,3))
# デフォルトのネガティブプロンプト
default_negative = ("low quality, worst quality, blurry, out of frame, watermark, signature, jpeg artifacts, "
"text, logo, extra fingers, extra limbs, extra digits, deformed, disfigured, poorly drawn hands, "
"bad anatomy, cropped, duplicate")
self.negative_prompt_text.insert('1.0', default_negative)
self.negative_prompt_widgets = [self.negative_label, self.negative_prompt_text]
# ボタン
button_frame = ttk.Frame(self.prompt_frame)
button_frame.pack(pady=3)
ttk.Button(button_frame, text="サンプルプロンプト使用", command=self.use_sample_prompt, width=20).pack(side=tk.LEFT, padx=2)
self.generate_button = ttk.Button(button_frame, text="画像生成", command=self.generate_image, state=tk.DISABLED, width=15)
self.generate_button.pack(side=tk.LEFT, padx=2)
# プロンプト入力ガイド(常時表示)
prompt_guide_text = """=== プロンプト入力ガイド ===
1. メインプロンプト: 対象や構図、詳細描写を具体的に記述
例: 'a serene lakeside at sunset, detailed reflections,
mountains in background'
2. スタイルプロンプト: 画風や質感、雰囲気を補足(任意)
例: 'high quality, detailed, sharp, cinematic lighting'
3. ネガティブプロンプト: 避けたい要素を記述
デフォルト値が設定済み(guidance_scale > 0の場合のみ使用)
Enterのみでサンプルプロンプトを使用"""
prompt_guide_label = tk.Text(self.prompt_frame, height=10, width=45, wrap=tk.WORD, font=("", 8), bg='#f0f0f0')
prompt_guide_label.insert('1.0', prompt_guide_text)
prompt_guide_label.config(state=tk.DISABLED)
prompt_guide_label.pack(fill=tk.X, pady=5)
# 右列:画像表示
right_col = ttk.Frame(top_frame)
right_col.pack(side=tk.LEFT, fill=tk.BOTH, padx=2)
image_frame = ttk.LabelFrame(right_col, text="生成画像", padding="2")
image_frame.pack(fill=tk.BOTH)
# 画像表示キャンバス(512x512)
self.image_canvas = tk.Canvas(image_frame, width=512, height=512, bg='gray90')
self.image_canvas.pack(pady=2)
self.canvas_text = self.image_canvas.create_text(256, 256, text="画像がここに表示されます\n(512x512表示)\n実際は1024x1024", fill="gray50")
self.save_button = ttk.Button(image_frame, text="画像を保存 (1024x1024)", command=self.save_image, state=tk.DISABLED)
self.save_button.pack(fill=tk.X, pady=2)
# 下部:ステータス
bottom_frame = ttk.Frame(main_frame)
bottom_frame.pack(fill=tk.X, pady=2)
# ステータステキスト
status_frame = ttk.LabelFrame(bottom_frame, text="ステータス", padding="2")
status_frame.pack(fill=tk.BOTH, pady=2)
self.status_text = scrolledtext.ScrolledText(status_frame, height=8, wrap=tk.WORD, font=("", 8))
self.status_text.pack(fill=tk.BOTH)
def show_initial_messages(self):
"""初期メッセージの表示"""
# モデル選択リストを表示
self.log_message("\n使用するモデルを選択してください:")
for i, key in enumerate(MODEL_CONFIGS.keys(), 1):
config = MODEL_CONFIGS[key]
self.log_message(f"{i}. {config['model_name']} ({config['model_description']})")
self.log_message(f" モデルID: {config['model_id']}")
self.log_message(f" URL: {config['model_url']}")
# トークンチェック
self.check_token()
def show_dependency_guide(self):
"""依存関係インストールガイドを表示"""
self.log_message("\n依存関係インストールガイド")
self.log_message("GPU環境:")
self.log_message(" 1. PyTorch公式サイトからCUDA対応版を選択してインストール")
self.log_message(" https://pytorch.org/get-started/locally/")
self.log_message(" 2. 任意: pip install xformers")
self.log_message("CPU環境:")
self.log_message(" pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu")
self.log_message("共通:")
self.log_message(" pip install 'diffusers>=0.30.0' huggingface_hub transformers accelerate pillow")
def log_message(self, message):
"""ステータステキストにメッセージを追加"""
self.status_text.insert(tk.END, message + "\n")
self.status_text.see(tk.END)
self.root.update()
def check_token(self):
"""トークンの存在確認"""
if self.hf_token:
self.token_status_label.config(text="トークン状態: 設定済み")
self.log_message("HF_TOKEN環境変数が検出されました。")
try:
login(token=self.hf_token, add_to_git_credential=False)
self.log_message("HuggingFaceへのログインに成功しました")
except Exception:
self.log_message("トークンが無効です。")
self.token_status_label.config(text="トークン状態: 無効")
else:
self.log_message("HF_TOKEN環境変数が設定されていません。")
def set_token(self):
"""トークンを設定"""
with self.processing_lock:
if self.is_processing:
return
token = self.token_entry.get().strip()
if not token:
self.log_message("エラー: トークンを入力してください")
return
try:
# トークンをテスト
login(token=token, add_to_git_credential=False)
# 現在のセッションで使用
self.hf_token = token
os.environ['HF_TOKEN'] = token # 現在のプロセスに設定
self.token_status_label.config(text="トークン状態: 設定済み")
self.log_message("トークンが正常に設定されました(現在のセッション)")
# 永続化の案内(Windowsの場合)
if sys.platform == "win32":
result = messagebox.askyesno(
"環境変数の永続化",
"環境変数を永続的に設定しますか?\n"
"「はい」を選択すると、システム環境変数に保存され、\n"
"アプリケーションの再起動が必要になります。"
)
if result:
try:
subprocess.run(['setx', 'HF_TOKEN', token], check=True, capture_output=True, text=True)
self.log_message("\n環境変数を永続的に設定しました。")
self.log_message("新しいコマンドプロンプトまたは開発環境を再起動してください。")
except subprocess.CalledProcessError as e:
self.log_message(f"\n環境変数の永続化に失敗しました: {e}")
except Exception as e:
self.log_message(f"トークンが無効です: {e}")
self.token_status_label.config(text="トークン状態: 無効")
def on_model_selected(self, event):
"""モデル選択時の処理"""
model_name = self.model_var.get()
for key, config in MODEL_CONFIGS.items():
if config['model_name'] == model_name:
self.selected_model = key
self.log_message(f"\n{config['model_name']}を選択しました。")
# モデル情報を表示
info_text = f"モデルID: {config['model_id']}\n"
info_text += f"説明: {config['model_description']}\n"
info_text += f"推論ステップ数: {config['num_inference_steps']}\n"
info_text += f"ガイダンススケール: {config['guidance_scale']}"
self.model_info_label.config(text=info_text)
# supports_negative_promptによる判定
use_neg_prompt = config.get("supports_negative_prompt", True)
if not use_neg_prompt:
for widget in self.negative_prompt_widgets:
widget.pack_forget()
self.log_message("\nこのモデルはネガティブプロンプトに対応していません")
else:
# ネガティブプロンプト欄を再表示
self.negative_label.pack(anchor=tk.W)
self.negative_prompt_text.pack(fill=tk.X, pady=(0,3))
# デフォルトのネガティブプロンプトについて説明
default_negative_prompt = (
"low quality, worst quality, blurry, out of frame, watermark, signature, jpeg artifacts, "
"text, logo, extra fingers, extra limbs, extra digits, deformed, disfigured, poorly drawn hands, "
"bad anatomy, cropped, duplicate"
)
self.log_message("\nネガティブプロンプトについて")
self.log_message("未入力の場合、以下のデフォルト値が使用される")
self.log_message(f"デフォルトのネガティブプロンプト: {default_negative_prompt}")
break
def load_model(self):
"""モデルを読み込む"""
with self.processing_lock:
if self.is_processing:
return
self.is_processing = True
if not self.selected_model:
self.log_message("エラー: モデルを選択してください")
self.is_processing = False
return
if not self.hf_token:
self.log_message("エラー: トークンを設定してください")
self.is_processing = False
return
self.generate_button.config(state=tk.DISABLED)
self.root.update()
try:
# 既存モデルのクリーンアップ
if self.pipe is not None:
self.log_message("既存のモデルを解放中...")
self.cleanup_resources()
model_config = MODEL_CONFIGS[self.selected_model]
# モデルへのアクセス権限を確認
self.log_message(f"\n{model_config['model_name']}へのアクセスを確認中...")
try:
info = model_info(model_config["model_id"], token=self.hf_token)
self.log_message(f"\n{model_config['model_name']}へのアクセスが確認できました。")
except GatedRepoError:
self.log_message(f"\nモデルへのアクセスに問題があります: ライセンス同意が必要です")
self.log_message(model_config["setup_message"])
self.log_message("\n準備後に再度「モデル読み込み」をクリックしてください")
return
except RepositoryNotFoundError:
self.log_message(f"\nモデルへのアクセスに問題があります: モデルが見つかりません")
self.log_message(model_config["setup_message"])
return
except Exception as e:
self.log_message(f"\nモデルへのアクセスに問題があります: {e}")
self.log_message(model_config["setup_message"])
return
# デバイスの自動選択
device = "cuda" if torch.cuda.is_available() else "cpu"
dtype = model_config["default_dtype"] if device == "cuda" else model_config["cpu_dtype"]
if device == "cpu":
self.log_message("GPUが利用できないため、CPUで実行します。処理に時間がかかる場合があります。")
# デバイス名とdtypeの明示出力
if device == "cuda":
try:
self.log_message(f"デバイス: GPU ({torch.cuda.get_device_name(0)})")
except Exception:
self.log_message("デバイス: GPU")
else:
self.log_message("デバイス: CPU")
self.log_message(f"データ型: {dtype}")
# パイプラインの読み込み
self.log_message("モデルの読み込み中...")
self.root.update()
from_pretrained_kwargs = {
"torch_dtype": dtype,
"token": self.hf_token,
"use_safetensors": True
}
# SDXL + GPU時にvariant設定を適切に処理
if self.selected_model.startswith("sdxl") and device == "cuda":
if dtype == torch.float16:
from_pretrained_kwargs["variant"] = "fp16"
# bfloat16の場合は特別な処理は不要(デフォルトで対応)
self.pipe = model_config["pipeline_class"].from_pretrained(
model_config["model_id"],
**from_pretrained_kwargs
)
self.pipe = self.pipe.to(device)
# メモリ最適化
if device == "cuda" and model_config.get("enable_cpu_offload", False):
self.pipe.enable_model_cpu_offload()
if model_config.get("enable_vae_tiling", False) and hasattr(self.pipe, 'vae'):
self.pipe.vae.enable_tiling()
# attention slicing と xFormers(可能な場合のみ)
if hasattr(self.pipe, "enable_attention_slicing"):
try:
self.pipe.enable_attention_slicing()
except Exception:
pass
if device == "cuda" and hasattr(self.pipe, "enable_xformers_memory_efficient_attention"):
try:
self.pipe.enable_xformers_memory_efficient_attention()
self.log_message("XFormers memory optimization enabled")
except Exception:
self.log_message("XFormers not available, skipping memory optimization")
# VAEの精度設定
if hasattr(self.pipe, 'vae'):
self.pipe.vae.to(dtype)
# スケジューラーの設定
if "scheduler_class" in model_config:
if model_config["scheduler_class"] == "default":
# SDXLはデフォルトのスケジューラーを使用
self.log_message("デフォルトのスケジューラーを使用します")
elif model_config["scheduler_class"] is not None:
# カスタムスケジューラーを設定
self.pipe.scheduler = model_config["scheduler_class"].from_config(self.pipe.scheduler.config)
self.log_message(f"カスタムスケジューラー({model_config['scheduler_class'].__name__})を設定しました")
self.log_message("モデルの読み込みが完了しました。")
# 正常にロードできた場合のみボタンを有効化
self.generate_button.config(state=tk.NORMAL)
except Exception as e:
self.log_message(f"モデル読み込みエラー: {e}")
if any(s in str(e).lower() for s in ["kmp_duplicate_lib_ok", "libiomp5", "openmp"]):
self.log_message("\nOpenMP関連のエラーが疑われる。暫定対処として以下を試すことがある。")
self.log_message(" Windows: setx KMP_DUPLICATE_LIB_OK TRUE")
self.log_message(" Linux/macOS: export KMP_DUPLICATE_LIB_OK=TRUE")
self.log_message("注意: 恒久対策ではなく、可能であれば重複するOpenMPランタイムの解消を推奨する")
self.log_message("\nトークンを再設定する場合は「Hugging Faceトークン再設定」をクリックしてください")
# エラー時はボタンを無効のままにする
self.generate_button.config(state=tk.DISABLED)
finally:
self.is_processing = False
def use_sample_prompt(self):
"""サンプルプロンプトを使用"""
if not self.selected_model:
self.log_message("エラー: モデルを選択してください")
return
model_config = MODEL_CONFIGS[self.selected_model]
sample_prompt = model_config.get("sample_prompt", "A beautiful landscape")
# メインプロンプトにサンプルを設定
self.main_prompt_text.delete('1.0', tk.END)
self.main_prompt_text.insert('1.0', sample_prompt)
# スタイルプロンプトをクリア
self.style_prompt_text.delete('1.0', tk.END)
self.log_message(f"サンプルプロンプトを設定しました: {sample_prompt}")
def generate_image(self):
"""画像を生成"""
with self.processing_lock:
if self.is_processing:
return
self.is_processing = True
if self.pipe is None:
self.log_message("エラー: モデルが読み込まれていません")
self.is_processing = False
return
# 生成処理を別スレッドで実行
generation_thread = threading.Thread(target=self._generate_image_thread)
generation_thread.daemon = True
generation_thread.start()
def _generate_image_thread(self):
"""画像生成の実際の処理(別スレッド)"""
try:
self.generate_button.config(state=tk.DISABLED)
self.root.update()
model_config = MODEL_CONFIGS[self.selected_model]
# プロンプトの取得
main_prompt = self.main_prompt_text.get('1.0', tk.END).strip()
style_prompt = self.style_prompt_text.get('1.0', tk.END).strip()
# メインプロンプトが空の場合はサンプルを使用
if not main_prompt:
main_prompt = model_config.get("sample_prompt", "A beautiful landscape")
self.log_message(f"メインプロンプトが未入力のため、サンプルプロンプトを使用: {main_prompt}")
# プロンプトの結合
combined_prompt = main_prompt
if style_prompt:
combined_prompt = f"{main_prompt}, {style_prompt}"
# ネガティブプロンプトの処理
use_neg_prompt = model_config.get("supports_negative_prompt", True)
negative_prompt_value = ""
if use_neg_prompt:
negative_prompt_value = self.negative_prompt_text.get('1.0', tk.END).strip()
if not negative_prompt_value:
# デフォルトのネガティブプロンプト
negative_prompt_value = ("low quality, worst quality, blurry, out of frame, watermark, signature, jpeg artifacts, "
"text, logo, extra fingers, extra limbs, extra digits, deformed, disfigured, poorly drawn hands, "
"bad anatomy, cropped, duplicate")
# 画像生成パラメータの準備
generation_params = {
"prompt": combined_prompt,
"num_inference_steps": model_config["num_inference_steps"],
"guidance_scale": model_config["guidance_scale"],
}
# ネガティブプロンプトの追加
if use_neg_prompt:
generation_params["negative_prompt"] = negative_prompt_value
# 解像度設定(SD3.5とSDXL両方に適用)
if "width" in model_config and "height" in model_config:
generation_params.update({
"width": model_config["width"],
"height": model_config["height"],
})
# 実行前の設定表示
self.log_message("\n画像生成を開始します...")
self.log_message("生成設定:")
if "width" in model_config and "height" in model_config:
self.log_message(f" 解像度: {model_config['width']}x{model_config['height']}")
self.log_message(f" 推論ステップ数: {model_config['num_inference_steps']}")
self.log_message(f" ガイダンススケール: {model_config['guidance_scale']}")
self.log_message(f" 使用プロンプト: {combined_prompt}")
if use_neg_prompt:
self.log_message(f" ネガティブプロンプト: {negative_prompt_value}")
else:
if model_config.get("supports_negative_prompt", True):
self.log_message(" ネガティブプロンプト: 未使用(ユーザー選択)")
else:
self.log_message(" ネガティブプロンプト: 非対応(モデル仕様)")
# 画像生成
result = self.pipe(**generation_params)
self.generated_image = result.images[0]
# UIスレッドで画像表示を更新
self.root.after(0, self._update_image_display)
self.log_message("画像生成が完了しました。")
except Exception as e:
self.log_message(f"画像生成エラー: {e}")
self.root.after(0, lambda: self.generate_button.config(state=tk.NORMAL))
finally:
self.is_processing = False
def _update_image_display(self):
"""画像表示の更新(UIスレッド)"""
if self.generated_image:
# 表示用に512x512にリサイズ
display_image = self.generated_image.resize((512, 512), Image.Resampling.LANCZOS)
self.photo = ImageTk.PhotoImage(display_image)
# キャンバスに表示
self.image_canvas.delete("all")
self.image_canvas.create_image(256, 256, image=self.photo)
# 保存ボタンを有効化
self.save_button.config(state=tk.NORMAL)
# 生成ボタンを再度有効化
self.generate_button.config(state=tk.NORMAL)
def save_image(self):
"""画像を保存"""
if self.generated_image is None:
self.log_message("エラー: 保存する画像がありません")
return
# ファイル保存ダイアログ
file_path = filedialog.asksaveasfilename(
defaultextension=".png",
filetypes=[
("PNG files", "*.png"),
("JPEG files", "*.jpg"),
("All files", "*.*")
]
)
if file_path:
try:
# 元の解像度(1024x1024)で保存
self.generated_image.save(file_path)
self.log_message(f"画像を保存しました: {file_path}")
except Exception as e:
self.log_message(f"画像保存エラー: {e}")
def main():
"""メイン関数"""
root = tk.Tk()
app = StableDiffusionGUI(root)
root.mainloop()
if __name__ == "__main__":
main()