ByteTrack によるマルチオブジェクトトラッキング(ソースコードと実行結果)
Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
インストール済みの場合は実行不要。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent --accept-source-agreements --accept-package-agreements
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】
Python の公式ページ: https://www.python.org/
AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AI エディタの利用を推奨する。ここでは,Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行して、Windsurfをシステム全体にインストールする。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
winget install --scope machine --id Codeium.Windsurf -e --silent --accept-source-agreements --accept-package-agreements【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
必要なライブラリをシステム領域にインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する
pip install ultralytics supervision numpy opencv-python pillow
ByteTrack によるマルチオブジェクトトラッキングプログラム
概要
このプログラムは動画フレームから物体を検出し、時系列での物体の動きを理解・追跡する。リアルタイムで複数の物体を識別し、それらの移動軌跡を継続的に把握する。
主要技術
- ByteTrack: 高信頼度・低信頼度の検出結果を二段階で関連付けすることで、オクルージョン(遮蔽)や一時的な物体消失に対応したマルチオブジェクトトラッキング技術である[1]。従来手法では破棄されていた低信頼度検出ボックスを活用し、追跡の連続性を向上させる。
- YOLO11: リアルタイム物体検出を行う深層学習モデルである[2]。COCOデータセットで事前学習された軽量版(yolo11n.pt)を使用し、動画フレーム内の物体を高速で検出する。
参考文献
- [1] Zhang, Y., Sun, P., Jiang, Y., Yu, D., Weng, F., Yuan, Z., Luo, P., Liu, W., & Wang, X. (2022). ByteTrack: Multi-Object Tracking by Associating Every Detection Box. In Computer Vision – ECCV 2022 (pp. 1-21). Springer.
- [2] Jocher, G., & Qiu, J. (2024). Ultralytics YOLO11 (Version 11.0.0) [Computer software]. https://github.com/ultralytics/ultralytics
ソースコード
"""
マルチオブジェクトトラッキングシステム
特徴技術名: ByteTrack
出典: Zhang, Y. et al. (2022). ByteTrack: Multi-Object Tracking by Associating Every Detection Box.
ECCV 2022. https://arxiv.org/abs/2110.06864
特徴機能: 全ての検出ボックス(高信頼度・低信頼度)を関連付けることで、
オクルージョンや一時的な遮蔽に対応したマルチオブジェクトトラッキングを実現
学習済みモデル: YOLO11n (yolo11n.pt)
- 概要: 軽量版YOLO11モデル、COCOデータセット80クラス対応
- URL: 自動ダウンロード (https://github.com/ultralytics/ultralytics)
方式設計:
関連利用技術:
- ByteTrack: 高信頼度・低信頼度検出を二段階で関連付けするマルチオブジェクトトラッキング
- YOLO11: オブジェクト検出モデル(軽量版yolo11n.pt使用)
- Supervision: コンピュータビジョンユーティリティライブラリ
- OpenCV: 画像・動画処理、日本語フォント表示対応
入力と出力:
入力: 動画(ユーザは「0:動画ファイル,1:カメラ,2:サンプル動画」のメニューで選択.
0:動画ファイルの場合はtkinterでファイル選択.1の場合はOpenCVでカメラが開く.
2の場合はhttps://raw.githubusercontent.com/opencv/opencv/master/samples/data/vtest.aviを使用)
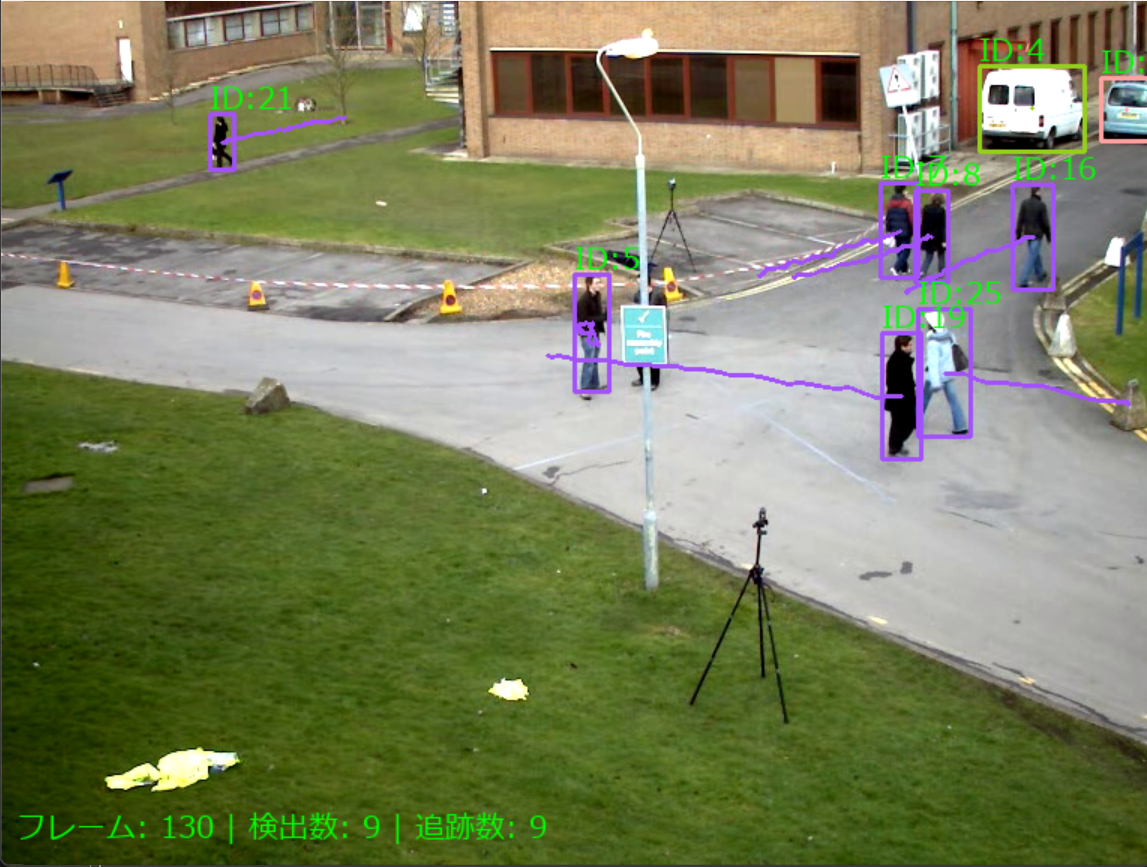
出力: OpenCV画面でリアルタイム表示。ID付きバウンディングボックスと追跡情報を表示。
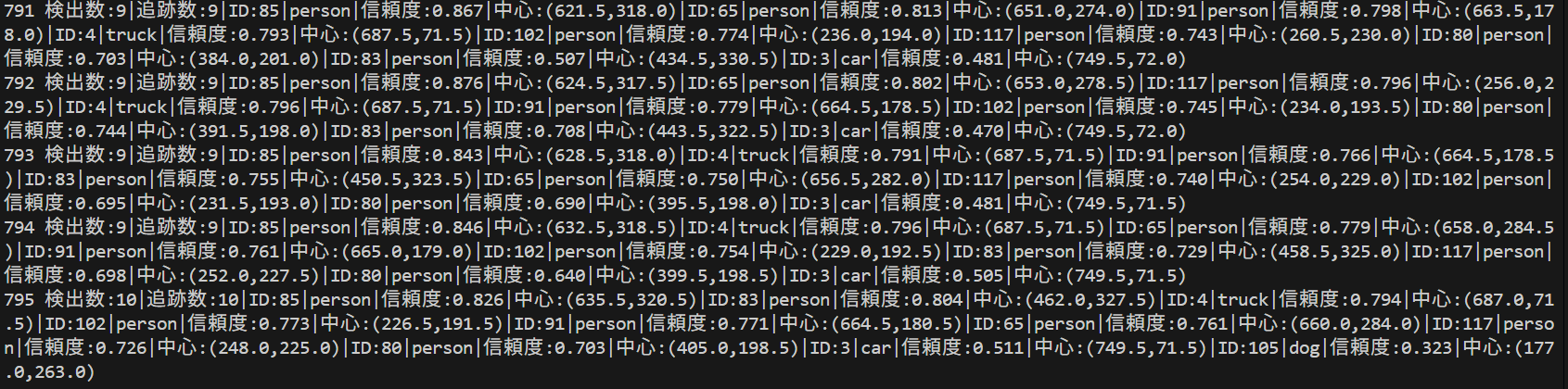
各フレームごとにprint()で処理結果表示。プログラム終了時にresult.txtファイルに保存。
処理手順:
1. YOLO11によるオブジェクト検出(信頼度スコア付き)
2. ByteTrackによる二段階関連付け(第一段階:高信頼度検出、第二段階:低信頼度検出)
3. カルマンフィルタによる位置予測とIoUベース類似度計算
4. ハンガリアンアルゴリズムによるマッチング
5. 日本語フォント使用による結果可視化
前処理: フレーム正規化、モデル入力サイズ調整
後処理: 検出結果のフィルタリング、追跡ID管理
追加処理: 日本語テキスト描画による視認性向上
調整を必要とする設定値:
- 検出信頼度閾値: 高信頼度・低信頼度検出の分離基準
- tracker信頼度閾値: オブジェクト追跡の精度に影響
- IoU閾値: 位置ベース類似度計算の基準
将来方策: 検出信頼度閾値の自動調整機能、Re-ID特徴量による外観類似度の追加、複数カメラ対応、リアルタイム性能最適化
その他の重要事項: Windows環境設計、メイリョフォント使用
前準備:
pip install ultralytics supervision numpy opencv-python pillow torch
"""
# 調整可能な設定値
CONFIDENCE_THRESHOLD = 0.3 # YOLO検出信頼度閾値(0.0-1.0)
IOU_THRESHOLD = 0.5 # ByteTracker IoU閾値(0.0-1.0)
FONT_SIZE = 20 # 日本語フォントサイズ
FONT_PATH = 'C:/Windows/Fonts/meiryo.ttc' # Windowsメイリョフォントパス
import cv2
import tkinter as tk
from tkinter import filedialog
import os
import numpy as np
from ultralytics import YOLO
import supervision as sv
from PIL import Image, ImageDraw, ImageFont
import urllib.request
import time
from datetime import datetime
import torch
# GPU/CPU自動選択
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'デバイス: {str(device)}')
# GPU使用時の最適化
if device.type == 'cuda':
torch.backends.cudnn.benchmark = True
frame_count = 0
results_log = []
def video_frame_processing(frame):
global frame_count
current_time = time.time()
frame_count += 1
# オブジェクト検出
results = model(frame, verbose=False, conf=CONFIDENCE_THRESHOLD)[0]
detections = sv.Detections.from_ultralytics(results)
# Multi Object Tracking実行
detections = tracker.update_with_detections(detections)
# 結果描画(ID付きバウンディングボックス)
ann_frame = sv.BoxAnnotator().annotate(
scene=frame.copy(),
detections=detections
)
# 軌跡描画
ann_frame = trace_annotator.annotate(
scene=ann_frame,
detections=detections
)
# 追跡データ記録と日本語テキスト表示
tracking_data = []
detection_count = len(detections.xyxy)
tracked_count = 0
if detection_count > 0:
img_pil = Image.fromarray(cv2.cvtColor(ann_frame, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_pil)
for i, bbox in enumerate(detections.xyxy):
x1, y1, x2, y2 = map(int, bbox)
center_x = (x1 + x2) / 2
center_y = (y1 + y2) / 2
width = x2 - x1
height = y2 - y1
# クラス名取得
class_name = "object"
if detections.class_id is not None and i < len(detections.class_id):
class_id = detections.class_id[i]
if hasattr(results, 'names') and class_id in results.names:
class_name = results.names[class_id]
# 信頼度取得
confidence = 0.0
if detections.confidence is not None and i < len(detections.confidence):
confidence = detections.confidence[i]
# tracker_idが存在する場合はIDを表示
if detections.tracker_id is not None and i < len(detections.tracker_id):
tracker_id = detections.tracker_id[i]
text = f"ID:{tracker_id}"
tracked_count += 1
tracking_data.append({
'id': tracker_id,
'class': class_name,
'confidence': confidence,
'center_x': center_x,
'center_y': center_y,
'width': width,
'height': height
})
else:
text = f"検出:{i}"
tracking_data.append({
'id': f"検出_{i}",
'class': class_name,
'confidence': confidence,
'center_x': center_x,
'center_y': center_y,
'width': width,
'height': height
})
draw.text((x1, y1-25), text, font=font, fill=(0, 255, 0))
ann_frame = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
# フレーム処理状況をリアルタイム表示(日本語対応)
img_pil_status = Image.fromarray(cv2.cvtColor(ann_frame, cv2.COLOR_BGR2RGB))
draw_status = ImageDraw.Draw(img_pil_status)
status_text = f"フレーム: {frame_count} | 検出数: {detection_count} | 追跡数: {tracked_count}"
draw_status.text((10, ann_frame.shape[0] - 40), status_text, font=font, fill=(0, 255, 0))
ann_frame = cv2.cvtColor(np.array(img_pil_status), cv2.COLOR_RGB2BGR)
# 結果文字列の生成
if tracking_data:
result_parts = []
for data in tracking_data:
result_parts.append(f"ID:{data['id']}|{data['class']}|信頼度:{data['confidence']:.3f}|中心:({data['center_x']:.1f},{data['center_y']:.1f})")
result = f"検出数:{detection_count}|追跡数:{tracked_count}|" + "|".join(result_parts)
else:
result = f"検出数:0|追跡数:0"
return ann_frame, result, current_time
print("=" * 80)
print("マルチオブジェクトトラッキングシステム")
print("=" * 80)
print("\n【概要】")
print("YOLO11とByteTrackを使用したリアルタイム複数オブジェクト追跡システムです。")
print("動画内のオブジェクトを検出・追跡し、ID付きバウンディングボックスと軌跡を表示します。")
print("\n【操作方法】")
print("1. 入力ソースを選択(0/1/2)")
print("2. 追跡結果をリアルタイムで確認")
print("3. 'q'キーで終了")
print("\n【注意事項】")
print("- 初回実行時はYOLO11モデルファイルが自動ダウンロードされます")
print("- 処理結果は各フレームごとにコンソールに表示され、終了時にresult.txtに保存されます")
print("- GPU利用可能な場合は自動的に使用されます")
print("-" * 80)
print("\n【入力ソース選択】")
print("0: 動画ファイル")
print("1: カメラ")
print("2: サンプル動画")
choice = input("選択: ")
# モデルとトラッカーの初期化
print("\n" + "=" * 40)
print("システム初期化中...")
print("=" * 40)
model = YOLO("yolo11n.pt")
model.verbose = False
# 実行状況の可視化
print(f"使用モデル: yolo11n.pt (YOLO11 nano)")
print(f"検出信頼度閾値: {CONFIDENCE_THRESHOLD}")
print(f"IoU閾値: {IOU_THRESHOLD}")
tracker = sv.ByteTrack()
trace_annotator = sv.TraceAnnotator()
# フォント設定
font = ImageFont.truetype(FONT_PATH, FONT_SIZE)
print("日本語フォント: 設定完了")
print("初期化完了!")
print("-" * 40)
if choice == '0':
root = tk.Tk()
root.withdraw()
path = filedialog.askopenfilename()
if not path:
exit()
cap = cv2.VideoCapture(path)
elif choice == '1':
cap = cv2.VideoCapture(0, cv2.CAP_DSHOW)
if not cap.isOpened():
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
else:
# サンプル動画ダウンロード・処理
SAMPLE_URL = 'https://raw.githubusercontent.com/opencv/opencv/master/samples/data/vtest.avi'
SAMPLE_FILE = 'vtest.avi'
urllib.request.urlretrieve(SAMPLE_URL, SAMPLE_FILE)
cap = cv2.VideoCapture(SAMPLE_FILE)
if not cap.isOpened():
print('動画ファイル・カメラを開けませんでした')
exit()
# メイン処理
print('\n=== 動画処理開始 ===')
print('操作方法:')
print(' q キー: プログラム終了')
try:
while True:
ret, frame = cap.read()
if not ret:
break
MAIN_FUNC_DESC = "ByteTrack + YOLO11 トラッキング"
processed_frame, result, current_time = video_frame_processing(frame)
cv2.imshow(MAIN_FUNC_DESC, processed_frame)
if choice == '1': # カメラの場合
print(datetime.fromtimestamp(current_time).strftime("%Y-%m-%d %H:%M:%S.%f")[:-3], result)
else: # 動画ファイルの場合
print(frame_count, result)
results_log.append(result)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
finally:
print('\n=== プログラム終了 ===')
cap.release()
cv2.destroyAllWindows()
if results_log:
with open('result.txt', 'w', encoding='utf-8') as f:
f.write('=== 結果 ===\n')
f.write(f'処理フレーム数: {frame_count}\n')
f.write(f'使用デバイス: {str(device).upper()}\n')
if device.type == 'cuda':
f.write(f'GPU: {torch.cuda.get_device_name(0)}\n')
f.write('\n')
f.write('\n'.join(results_log))
print(f'\n処理結果をresult.txtに保存しました')