データ前処理の例:欠損値補完とMinMaxスケーリング
【概要】scikit-learnを使用。データ前処理として、欠損値補完とMinMaxスケーリングを実行し、データの変化を観察。機械学習での前処理の重要性を確認する。
目次
概要
基本概念: 欠損値とは観測されなかった値であり、分析結果に偏りを生じさせる可能性がある。MinMaxスケーリングとは変数を指定された範囲(通常0-1)に変換するスケーリング手法である。
前処理の必要性: 機械学習アルゴリズムは数値データを前提とし、欠損値や異なるスケールの変数が存在すると計算が不安定になるため、前処理が必要となる。
技術的特徴: scikit-learnのデータ前処理機能として、欠損値処理、スケーリングなどの機能が提供される。本実習では欠損値補完(平均値)とMinMaxスケーリング(0-1変換)を実装する。
適用条件: MinMaxScalerは外れ値に敏感であり、データに極端な値が含まれる場合は結果が歪む。そのような場合は他のスケーリング手法の使用を検討する。
学習目標: 欠損値の影響とスケーリング前後での数値分布の変化を数値的に確認し、異なるスケーリング手法の効果を比較検証する。
論文: Pedregosa, F., et al. (2011). Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research, 12, 2825-2830.
事前準備
Python, Windsurfをインストールしていない場合の手順(インストール済みの場合は実行不要)。
- 管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。
- 以下のコマンドをそれぞれ実行する(winget コマンドは1つずつ実行)。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent
REM Windsurf をシステム領域にインストール
winget install --scope machine --id Codeium.Windsurf -e --silent
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul
REM Windsurf のパス設定
set "WINDSURF_PATH=C:\Program Files\Windsurf"
if exist "%WINDSURF_PATH%" (
echo "%PATH%" | find /i "%WINDSURF_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%WINDSURF_PATH%" /M >nul
)
必要なライブラリのインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する:
pip install pandas numpy scikit-learn
プログラムコードと実行結果
ソースコード
# 欠損値補完とMinMaxスケーリングによるデータ前処理プログラム
# 特徴技術名: scikit-learn [機械学習のための前処理・モデリングライブラリ]
# 出典: F. Pedregosa et al., "Scikit-learn: Machine Learning in Python," Journal of Machine Learning Research, vol. 12, pp. 2825-2830, 2011.
# 特徴機能: MinMaxScaler [各特徴量を指定範囲(デフォルト0-1)に線形変換する正規化機能。最小値を0、最大値を1に変換することで、異なるスケールの特徴量を統一的に扱える]
# 学習済みモデル: 使用なし
# 方式設計:
# - 関連利用技術:
# - pandas (データ分析ライブラリ、欠損値処理のfillna()メソッドを提供)
# - numpy (数値計算ライブラリ、欠損値表現のnp.nanを提供)
# - 入力と出力: 入力: データ(ユーザは「0:CSVファイル,1:サンプルデータ」のメニューで選択.0:CSVファイルの場合はtkinterでファイル選択)、出力: コンソールへのテキスト表示およびresult.txtファイル
# - 処理手順: 1) データ取得(CSVまたはサンプル)、2) 各列の平均値で欠損値補完、3) MinMaxScalerで0-1範囲に正規化、4) 結果表示・保存
# - 前処理、後処理: 該当なし(MinMaxScaler自体が前処理機能)
# - 追加処理: 該当なし
# - 調整を必要とする設定値: feature_range(MinMaxScalerのスケーリング範囲、デフォルト(0,1))
# 将来方策: ユーザがfeature_rangeを対話的に設定できる機能の実装
# その他の重要事項: 欠損値補完は平均値を使用。カテゴリカルデータには適用不可
# 前準備: pip install pandas numpy scikit-learn
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
import tkinter as tk
from tkinter import filedialog
# 定数定義
RANDOM_SEED = 42 # 再現性のための乱数シード
FEATURE_RANGE = (0, 1) # MinMaxScalerのデフォルト範囲(最小値, 最大値)
# 再現性のための乱数シード設定
np.random.seed(RANDOM_SEED)
# プログラム概要表示
print('=== 欠損値補完とMinMaxスケーリングによるデータ前処理プログラム ===')
print('このプログラムは、データの欠損値を平均値で補完し、')
print('MinMaxScalerで指定範囲に正規化します。')
print()
# データ取得
print('0: CSVファイル')
print('1: サンプルデータ')
choice = input('選択: ')
if choice == '0':
root = tk.Tk()
root.withdraw()
path = filedialog.askopenfilename(filetypes=[('CSV files', '*.csv')])
if not path:
exit()
try:
data = pd.read_csv(path)
# 数値列のみ抽出
numeric_columns = data.select_dtypes(include=[np.number]).columns
data = data[numeric_columns]
if data.empty:
print('エラー: 数値データが含まれていません')
exit()
except Exception as e:
print(f'ファイル読み込みエラー: {e}')
exit()
elif choice == '1':
# サンプルデータの作成(欠損値含む)
data = pd.DataFrame({
'age': [25, 30, np.nan, 45, 50],
'income': [50000, 60000, 55000, np.nan, 65000],
'score': [200, 250, 240, 260, 220]
})
else:
print('無効な選択です')
exit()
# データ検証
if len(data) < 2:
print('エラー: データが2行以上必要です')
exit()
# データ読み込み後にスケーリング範囲を設定
print()
print('データの概要:')
print(f' 行数: {len(data)}')
print(f' 列数: {len(data.columns)}')
print(f' 列名: {list(data.columns)}')
# 欠損値の状況を表示
missing_info = data.isnull().sum()
if missing_info.sum() > 0:
print()
print('欠損値の状況:')
for col in missing_info[missing_info > 0].index:
print(f' {col}: {missing_info[col]}件 ({missing_info[col]/len(data)*100:.1f}%)')
print()
print('MinMaxスケーリングの範囲を設定します(デフォルト: 0-1)')
use_default = input('デフォルト値を使用しますか? (y/n): ')
if use_default.lower() != 'y':
try:
min_val = float(input('最小値を入力してください: '))
max_val = float(input('最大値を入力してください: '))
if min_val >= max_val:
print('エラー: 最小値は最大値より小さくしてください')
exit()
FEATURE_RANGE = (min_val, max_val)
except ValueError:
print('エラー: 数値を入力してください')
exit()
# メイン処理
# 全値が欠損の列をチェック
all_null_columns = data.columns[data.isnull().all()].tolist()
if all_null_columns:
print()
print(f'警告: 以下の列は全ての値が欠損しています: {all_null_columns}')
print('これらの列は0で補完されます')
# 欠損値を平均値で補完(全値欠損の場合は0で補完)
column_means = data.mean()
# 全値欠損の列は平均値がNaNになるため、0で置換
column_means = column_means.fillna(0)
filled_data = data.fillna(column_means)
# 補完後の欠損値チェック
if filled_data.isnull().any().any():
print('エラー: 欠損値の補完に失敗しました')
print('残存する欠損値:')
remaining_nulls = filled_data.isnull().sum()
for col in remaining_nulls[remaining_nulls > 0].index:
print(f' {col}: {remaining_nulls[col]}件')
exit()
# MinMaxスケーリングによるデータスケーリング
scaler = MinMaxScaler(feature_range=FEATURE_RANGE)
try:
scaled_data = pd.DataFrame(scaler.fit_transform(filled_data), columns=filled_data.columns)
except ValueError as e:
print(f'エラー: スケーリング処理に失敗しました: {e}')
exit()
# 結果出力
output = []
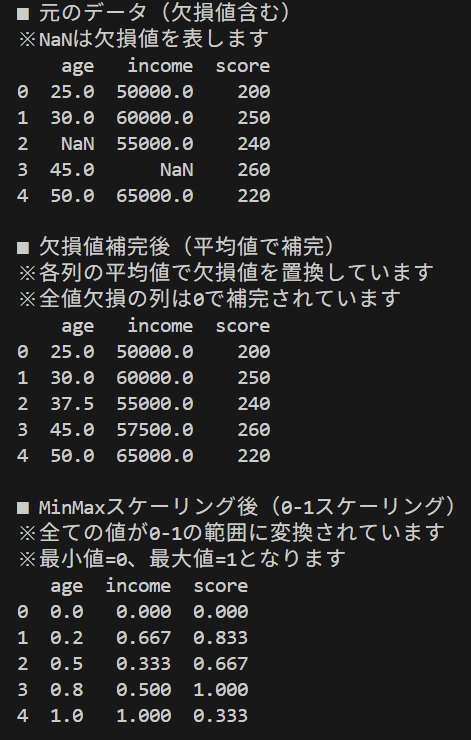
output.append('■ 元のデータ(欠損値含む)')
output.append('※ NaNは欠損値を表します')
output.append(str(data))
output.append('')
output.append('■ 欠損値補完後(平均値で補完)')
output.append('※ 各列の平均値で欠損値を置換しています')
output.append('※ 全値欠損の列は0で補完されています')
output.append(str(filled_data.round(2)))
output.append('')
output.append(f'■ MinMaxスケーリング後({FEATURE_RANGE[0]}-{FEATURE_RANGE[1]}スケーリング)')
output.append(f'※ 全ての値が{FEATURE_RANGE[0]}-{FEATURE_RANGE[1]}の範囲に変換されています')
output.append(f'※ 最小値={FEATURE_RANGE[0]}、最大値={FEATURE_RANGE[1]}となります')
output.append(str(scaled_data.round(3)))
# 統計情報の追加(動的精度調整)
def format_stats(df, label):
"""統計情報を適切な精度で整形"""
result = []
result.append(f'【{label}】')
# 各統計量を計算
min_vals = df.min()
max_vals = df.max()
mean_vals = df.mean()
# 列ごとに適切な精度を決定
min_dict = {}
max_dict = {}
mean_dict = {}
for col in df.columns:
# 値の大きさに応じて精度を調整
max_abs = max(abs(min_vals[col]), abs(max_vals[col])) if not pd.isna(min_vals[col]) else 0
if max_abs == 0:
precision = 1
elif max_abs < 1:
precision = 4
elif max_abs < 100:
precision = 2
elif max_abs < 10000:
precision = 1
else:
precision = 0
min_dict[col] = round(min_vals[col], precision) if not pd.isna(min_vals[col]) else 'NaN'
max_dict[col] = round(max_vals[col], precision) if not pd.isna(max_vals[col]) else 'NaN'
mean_dict[col] = round(mean_vals[col], precision) if not pd.isna(mean_vals[col]) else 'NaN'
result.append(f' 最小値: {min_dict}')
result.append(f' 最大値: {max_dict}')
result.append(f' 平均値: {mean_dict}')
return result
output.append('')
output.append('■ 統計情報')
# 元データ(欠損値含む)の統計
stats_original = format_stats(data, '元データ(欠損値含む)')
output.extend(stats_original)
output.append('')
# 補完後データの統計
stats_filled = format_stats(filled_data, '補完後データ')
output.extend(stats_filled)
output.append('')
# スケーリング後データの統計
stats_scaled = format_stats(scaled_data, 'スケーリング後データ')
output.extend(stats_scaled)
# 補完情報の追加
if missing_info.sum() > 0:
output.append('')
output.append('■ 欠損値補完の詳細')
for col in missing_info[missing_info > 0].index:
if col in all_null_columns:
output.append(f' {col}: 全値欠損のため0で補完')
else:
mean_val = data[col].mean()
output.append(f' {col}: 平均値 {mean_val:.2f} で補完')
# コンソール出力
for line in output:
print(line)
# ファイル保存
with open('result.txt', 'w', encoding='utf-8') as f:
for line in output:
f.write(line + '\n')
print()
print('result.txtに保存しました')
実行結果の解釈: スケーリング後の値0は元データの最小値、1は元データの最大値に対応する。変換後も元データの順序関係は保持される。各列で独立してスケーリングが適用されるため、列間の相対的な大きさの関係は変化する場合がある。
使用方法
- 上記のプログラムを実行
- 3段階の処理結果が表示され、データの変化を確認できる
実験のアイデア
スケーリング手法の比較:
- StandardScaler(標準化:平均0、分散1に変換)との比較
- RobustScaler(ロバストスケーリング:中央値と四分位範囲を使用)との比較
欠損値処理の比較:
- 中央値(
median())による補完 - 最頻値(
mode())による補完 - より多くの欠損値を含むデータでの処理結果の確認
発展的な検証:
- 外れ値の影響調査:極端に大きな値を含むデータでの各スケーラーの動作比較
- 統計量の変化:スケーリング前後での基本統計量(平均、分散等)の変化の数値的確認
- 実データでの検証:公開データセット(Boston住宅価格、Irisデータセット等)での前処理効果の確認