MiDaSによる深度推定
【概要】MiDaSは単眼カメラから深度情報を推定するAI技術である。Webカメラを用いたリアルタイム深度推定プログラムにより、深度マップの可視化と単眼深度推定を確認する。Windows環境での実行手順、プログラムコード、実験アイデアを含む。
目次
はじめに
MiDaSは単眼深度推定技術である。深度推定とは、画像から物体までの距離情報を推定する技術であり、深度マップ(各ピクセルの深度値を画像として表現したもの)として出力される。単眼深度推定は1台のカメラで深度を推定する技術で、ステレオカメラやLiDARを使用する手法とは異なる。
Ranftl et al.による論文「Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-Shot Cross-Dataset Transfer」(IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 44, No. 3, 2022)で提案されたMiDaSの新規性は、複数データセットでの混合学習により未知環境でも深度推定を実現する点にある。自動運転、ロボットビジョン、AR/VRアプリケーションに活用できる。
Webカメラ映像からリアルタイムで深度マップを生成し、その機能を確認できる。
技術的背景
処理の流れ
MiDaSの処理は以下の3段階で構成される:
- 前処理:入力画像をBGR形式からRGB形式に変換し、各モデルが学習時に使用した形式に正規化する
- 推論:畳み込みニューラルネットワークが画像特徴から深度を推定する
- 後処理:bicubic補間(滑らかな深度マップを生成する画像拡大手法)による解像度調整と、可視化のための0-1範囲への正規化を行う
利用可能なモデル
MiDaSでは精度と速度の関係を考慮した3つのモデルが提供される:
- DPT_Large:MiDaS v3.0の大型モデル(高精度、低速度、約3億4500万パラメータ)
- DPT_Hybrid:MiDaS v3.0のハイブリッドモデル(中精度、中速度、約1億2300万パラメータ)
- MiDaS_small:MiDaS v2.1の小型モデル(低精度、高速度、約2140万パラメータ)
事前準備
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
インストール済みの場合は実行不要。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent --accept-source-agreements --accept-package-agreements
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】
Python の公式ページ: https://www.python.org/
AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AI エディタの利用を推奨する。ここでは,Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行して、Windsurfをシステム全体にインストールする。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
winget install --scope machine --id Codeium.Windsurf -e --silent --accept-source-agreements --accept-package-agreements【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
必要なパッケージのインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。
pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126pip install opencv-python numpy pillow
プログラムコード
# プログラム名: MiDaSリアルタイム単眼深度推定
# 特徴技術名: MiDaS (Monocular Depth Estimation) v3.0/v3.1
# 出典: Ranftl, R., Bochkovskiy, A., & Koltun, V. (2021). Vision Transformers for Dense Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 12179-12188).
# 特徴機能: ゼロショット汎化による単眼深度推定 - 複数データセットでの学習により、未知の環境でも深度マップを生成
# 学習済みモデル:
# - DPT_Large: MiDaS v3.0大型モデル(約345Mパラメータ、Vision Transformer使用)
# - DPT_Hybrid: MiDaS v3.0ハイブリッドモデル(約123Mパラメータ、CNN+Transformer)
# - MiDaS_small: MiDaS v2.1小型モデル(約21.4Mパラメータ、EfficientNet使用)
# - URL: torch.hub経由で自動ダウンロード(intel-isl/MiDaS)
# 方式設計:
# - 関連利用技術:
# - PyTorch: 深層学習フレームワーク(モデル実行、GPU処理)
# - OpenCV: 画像処理(カメラ入力、画像表示、カラーマップ適用)
# - NumPy: 数値計算(深度マップの正規化処理)
# - Pillow: 日本語テキスト描画(Meiryo使用)
# - 入力と出力: 入力: 動画(ユーザは「0:動画ファイル,1:カメラ,2:サンプル動画」のメニューで選択)、出力: リアルタイム深度マップ表示(OpenCV画面)、正規化相対深度範囲情報(推論実行フレームごと)、result.txtファイル
# - 処理手順:
# 1. カメラから画像フレーム取得
# 2. BGR→RGB変換
# 3. MiDaS前処理(リサイズ、正規化)
# 4. DPTモデルによる深度推定
# 5. 深度マップの補間とリサイズ
# 6. 正規化(0〜1)とカラーマップ適用・表示
# - 前処理、後処理:
# - 前処理: 入力画像の正規化(平均値減算、標準偏差除算)、384x384または512x512へのリサイズ
# - 後処理: bicubic補間による元画像サイズへの復元、深度値の正規化(0-1範囲)
# - 追加処理: フレームスキップ処理(FRAME_SKIP=10)による計算負荷軽減。バッファクリア(grab/retrieve分離)は未実装(CAP_PROP_BUFFERSIZEの設定のみ)
# - 調整を必要とする設定値:
# - MODEL_TYPE: 使用するMiDaSモデル(メニューから選択)
# - FRAME_SKIP: 深度推定実行間隔(デフォルト10フレーム)
# 注意: MiDaSの出力は相対的な深度(絶対距離ではない)であるため、本プログラムでは正規化相対深度(0〜1)として扱う
import cv2
import tkinter as tk
from tkinter import filedialog
import torch
import numpy as np
import time
from datetime import datetime
import urllib.request
from PIL import Image, ImageDraw, ImageFont
# 設定パラメータ
FRAME_SKIP = 10 # 深度推定を実行するフレーム間隔
COLORMAP = cv2.COLORMAP_PLASMA # 深度マップのカラーマップ
FONT_PATH = 'C:/Windows/Fonts/meiryo.ttc' # 日本語フォントパス
FONT_SIZE = 20 # 日本語テキストのフォントサイズ
TEXT_COLOR = (0, 255, 0) # テキストの色(BGR)
# 利用可能なMiDaSモデルの定義
AVAILABLE_MODELS = {
'1': {
'name': 'DPT_Large',
'description': 'MiDaS v3.0 大型モデル(約345Mパラメータ、Vision Transformer、最高精度、低速)'
},
'2': {
'name': 'DPT_Hybrid',
'description': 'MiDaS v3.0 ハイブリッドモデル(約123Mパラメータ、CNN+Transformer、中精度、中速)'
},
'3': {
'name': 'MiDaS_small',
'description': 'MiDaS v2.1 小型モデル(約21.4Mパラメータ、EfficientNet、低精度、高速)'
}
}
# プログラム開始時の説明表示
print('=== MiDaSリアルタイム単眼深度推定 ===')
print('概要: 単一のカメラ画像から深度マップを推定する')
print('数値表示: 相対深度値と正規化値を表示する')
print('操作方法: ')
print(' - qキー: プログラムを終了')
print('注意事項:')
print(' - 初回実行時はモデルのダウンロードに時間がかかる')
print(' - GPU使用時は処理速度が向上する')
print('')
# モデル選択メニュー表示
print('使用するMiDaSモデルを選択してください:')
for key, model_info in AVAILABLE_MODELS.items():
print(f'{key}: {model_info["description"]}')
model_choice = input('選択: ')
if model_choice not in AVAILABLE_MODELS:
print('無効な選択である')
exit()
MODEL_TYPE = AVAILABLE_MODELS[model_choice]['name']
# 学習済みMiDaSモデルのダウンロードと初期化
print(f'MiDaSモデル「{MODEL_TYPE}」を読み込んでいる...')
midas = torch.hub.load('intel-isl/MiDaS', MODEL_TYPE)
# GPU/CPU自動選択
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'デバイス: {str(device)}')
# GPU使用時の最適化
if device.type == 'cuda':
torch.backends.cudnn.benchmark = True
midas.to(device)
midas.eval()
print(f'使用モデル: {MODEL_TYPE}')
# 前処理の取得
midas_transforms = torch.hub.load('intel-isl/MiDaS', 'transforms')
if MODEL_TYPE == 'DPT_Large' or MODEL_TYPE == 'DPT_Hybrid':
transform = midas_transforms.dpt_transform
else:
transform = midas_transforms.small_transform
# グローバル変数
frame_count = 0
results_log = []
depth_map = None # モデル生出力(補間後)
norm_map = None # 正規化相対深度(0〜1)
raw_min = None # 生の深度値の最小値
raw_max = None # 生の深度値の最大値
last_infer_frame = None # 深度推論に使用した元フレーム(表示と同期用)
last_infer_frame_index = 0 # 推論に使用したフレーム番号
next_infer_frame = 1 # 次に推論を実行するフレーム番号(1始まり)
# 日本語フォントの初期化
try:
font = ImageFont.truetype(FONT_PATH, FONT_SIZE)
except Exception:
font = None
print('日本語フォントの読み込みに失敗した。英語表示になる。')
def add_japanese_text(img, text, position, color=(0, 255, 0)):
"""OpenCV画像に日本語テキストを追加する"""
if font is None:
# フォントが使用できない場合は英語で表示
cv2.putText(img, text.encode('ascii', 'ignore').decode('ascii'),
position, cv2.FONT_HERSHEY_SIMPLEX, 0.7, color, 2)
return img
# OpenCV画像をPIL画像に変換
img_pil = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_pil)
# テキスト描画(PillowはRGB、OpenCVはBGRであるため順序を入れ替える)
draw.text(position, text, font=font, fill=(color[2], color[1], color[0]))
# PIL画像をOpenCV画像に変換
return cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
def video_frame_processing(frame):
global frame_count, depth_map, norm_map, raw_min, raw_max
global last_infer_frame, next_infer_frame, last_infer_frame_index
current_time = time.time()
frame_count += 1
# 推論実行タイミングの判定(1フレーム目、その後は等間隔)
run_inference = (frame_count >= next_infer_frame)
if run_inference:
# 画像を前処理
img_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
input_batch = transform(img_rgb).to(device)
# 深度推定の実行
with torch.no_grad():
prediction = midas(input_batch)
prediction = torch.nn.functional.interpolate(
prediction.unsqueeze(1),
size=img_rgb.shape[:2],
mode='bicubic',
align_corners=False,
).squeeze()
# 深度マップの取得(生出力、CPUへ転送)
depth_map = prediction.cpu().numpy()
# 生の深度値の範囲を保存
raw_min = float(depth_map.min())
raw_max = float(depth_map.max())
# 正規化(0〜1)
d_range = raw_max - raw_min
if d_range > 0:
norm_map = ((depth_map - raw_min) / d_range).astype(np.float32)
else:
norm_map = np.zeros_like(depth_map, dtype=np.float32)
# 表示用に推論に使用した元フレームを保存(同期のため)
last_infer_frame = frame.copy()
last_infer_frame_index = frame_count
# 次回推論フレームを更新(等間隔にする)
next_infer_frame += FRAME_SKIP
# 深度マップが利用できる場合の表示処理(表示は常に推論に用いたフレームと同期)
if norm_map is not None and last_infer_frame is not None:
# カラーマップ用画像
d_color = cv2.applyColorMap((norm_map * 255).astype(np.uint8), COLORMAP)
# 表示用の元画像(推論時のフレーム)を正規化マップと同サイズにリサイズ
f_resize = cv2.resize(last_infer_frame, (norm_map.shape[1], norm_map.shape[0]))
# 横に並べて表示
combined = np.hstack([f_resize, d_color])
# 中心画素の正規化相対深度
h, w = norm_map.shape
center_depth_norm = float(norm_map[h // 2, w // 2])
# combined画像の実際のサイズを取得
combined_h, _ = combined.shape[:2]
# テキスト表示(日本語対応)
combined = add_japanese_text(combined, f'中心の正規化相対深度: {center_depth_norm:.3f}', (10, 30), TEXT_COLOR)
combined = add_japanese_text(combined, f'推論フレーム: {last_infer_frame_index}', (10, 60), TEXT_COLOR)
combined = add_japanese_text(combined, f'モデル: {MODEL_TYPE}', (10, 90), TEXT_COLOR)
combined = add_japanese_text(combined, f'深度範囲: {raw_min:.2f} - {raw_max:.2f}', (10, 120), TEXT_COLOR)
combined = add_japanese_text(combined, 'qキーで終了', (10, combined_h - 30), TEXT_COLOR)
result = f'深度範囲: {raw_min:.2f} - {raw_max:.2f}, 中心深度: {center_depth_norm:.3f}'
return combined, result, current_time
else:
# 初回推論前など、深度マップが未生成の場合
frame = add_japanese_text(frame, '深度マップを処理中...', (10, 30), TEXT_COLOR)
result = '処理中'
return frame, result, current_time
print("0: 動画ファイル")
print("1: カメラ")
print("2: サンプル動画")
choice = input("選択: ")
if choice == '0':
root = tk.Tk()
root.withdraw()
path = filedialog.askopenfilename()
if not path:
exit()
cap = cv2.VideoCapture(path)
elif choice == '1':
cap = cv2.VideoCapture(0, cv2.CAP_DSHOW)
if not cap.isOpened():
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
else:
# サンプル動画ダウンロード・処理
SAMPLE_URL = 'https://raw.githubusercontent.com/opencv/opencv/master/samples/data/vtest.avi'
SAMPLE_FILE = 'vtest.avi'
urllib.request.urlretrieve(SAMPLE_URL, SAMPLE_FILE)
cap = cv2.VideoCapture(SAMPLE_FILE)
if not cap.isOpened():
print('動画ファイル・カメラを開けませんでした')
exit()
# メイン処理
print('\n=== 動画処理開始 ===')
print('操作方法:')
print(' q キー: プログラム終了')
try:
while True:
ret, frame = cap.read()
if not ret:
break
MAIN_FUNC_DESC = "MiDaS深度推定"
processed_frame, result, current_time = video_frame_processing(frame)
cv2.imshow(MAIN_FUNC_DESC, processed_frame)
if choice == '1': # カメラの場合
print(datetime.fromtimestamp(current_time).strftime("%Y-%m-%d %H:%M:%S.%f")[:-3], result)
else: # 動画ファイルの場合
print(frame_count, result)
results_log.append(result)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
finally:
print('\n=== プログラム終了 ===')
cap.release()
cv2.destroyAllWindows()
if results_log:
with open('result.txt', 'w', encoding='utf-8') as f:
f.write('=== 結果 ===\n')
f.write(f'処理フレーム数: {frame_count}\n')
f.write(f'使用デバイス: {str(device).upper()}\n')
if device.type == 'cuda':
f.write(f'GPU: {torch.cuda.get_device_name(0)}\n')
f.write('\n')
f.write('\n'.join(results_log))
print(f'\n処理結果をresult.txtに保存しました')
使用方法
- 上記のプログラムを実行する
- 初回実行時はモデルのダウンロードに時間がかかる
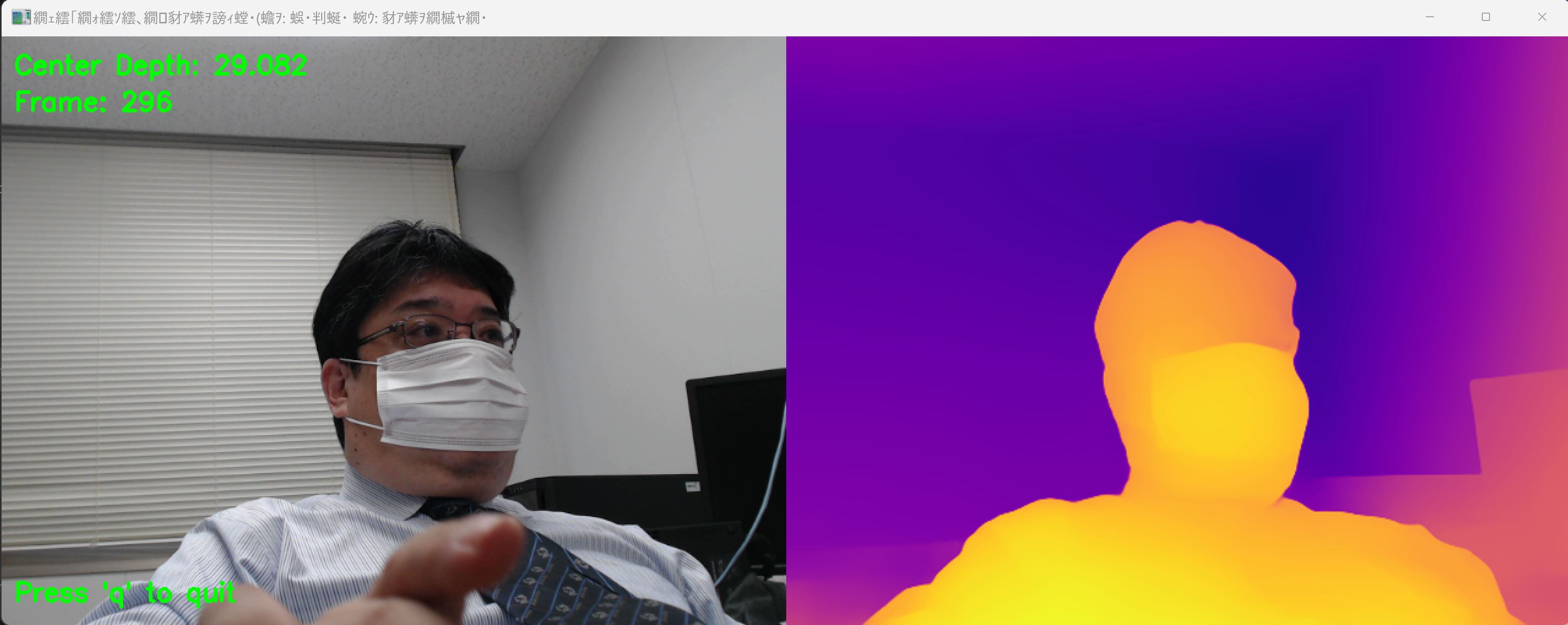
- Webカメラの映像がウィンドウに表示され、左側に元画像、右側に深度マップが表示される
- 深度マップでは、PLASMAカラーマップにより近い距離が暖色系、遠い距離が寒色系で表現される
- qキーで終了する
実験・探求
モデル比較実験
MODEL_TYPEを変更して3つのモデルの性能を比較する:
- DPT_Large:精度が高いが処理速度が遅い
- DPT_Hybrid:精度と速度のバランス型
- MiDaS_small:処理速度が速いが精度は低い
パラメータ調整実験
- FRAME_SKIPの値を変更して処理速度と滑らかさの関係を観察する
- カラーマップをCOLORMAP_JET、COLORMAP_HOTなどに変更して深度の可視化方法を比較する
- 照明条件(明るい場所、暗い場所)での深度推定精度を検証する
深度推定の限界検証
- 手を前後に動かして深度値の変化を観察する
- 物体を異なる距離に配置して深度推定の精度を確認する
- 鏡やガラスなど反射する物体での深度推定の挙動を観察する
- テクスチャのない壁面や繰り返しパターンでの推定精度を確認し、単眼カメラでの深度推定の限界を理解する