MediaPipe Pose Landmarker (Tasks API) による3次元人体姿勢推定
【概要】MediaPipe Pose Landmarker Tasks APIを用いた3D人体姿勢推定システム。動画やカメラ映像から33個の身体ランドマークを検出し、実世界の3D座標(メートル単位)をリアルタイム推定する。カメラ入力時はLIVE_STREAMモード、動画ファイル時はVIDEOモードを自動選択。複数人物の同時検出、部位ごとの色分け表示、骨格長計算、鏡像表示切り替え機能を搭載。スポーツフォーム分析や姿勢矯正の評価に活用可能。

プログラム利用ガイド
1. このプログラムの利用シーン
このツールは、人体の姿勢や動作を数値化して分析するための最新のソフトウェアである。MediaPipe Tasks APIを使用し、スポーツフォームの確認、リハビリテーションの進捗管理、ダンスや体操の動作解析、姿勢矯正の評価などに活用できる。カメラ映像から33個の身体部位を検出し、3次元世界座標(メートル単位)をリアルタイムで計測する。
2. 主な機能
- 姿勢推定: 33個の身体ランドマークを3D世界座標(メートル単位)で検出
- リアルタイム処理: LIVE_STREAMモード(カメラ)とVIDEOモード(動画)の自動切り替え
- 複数人物対応: 同時に複数人の姿勢を検出・追跡
- 部位別色分け: 顔(赤系)、上半身(緑系)、下半身(青系)で視覚的に区別
- 骨格長計算: 左右の上腕、前腕、大腿、下腿の長さをリアルタイム計測
- 鏡像表示: カメラ使用時にmキーで鏡像表示の切り替え(フィットネス用途に最適)
- モデル選択: Lite/Full/Heavyの3モデルから精度と速度のバランスを選択
- 結果保存: 検出結果をresult.txtファイルに自動記録
3. 基本的な使い方
- 起動とモデル選択:
プログラムを実行後、まず使用するモデルを選択する(1:Lite版、2:Full版、3:Heavy版)。モデルは自動的にダウンロードされる。
- 入力選択:
次に入力方法を選択する。0で動画ファイル(ファイル選択ダイアログが開く)、1でカメラ、2でサンプル動画を使用する。
- 姿勢推定の実行:
選択した入力源から映像が読み込まれ、自動的に姿勢推定が開始される。OpenCVウィンドウに推定結果が表示され、検出された身体部位が色分けされた線で結ばれる。
- 結果の確認:
画面上部にモデル名と実行モード(LIVE_STREAM/VIDEO)が表示される。コンソールには各人物の3D座標と骨格長が出力される。
- 終了方法:
qキーを押すとプログラムが終了し、処理結果がresult.txtに保存される。
4. 便利な機能
- 鏡像表示切り替え: カメラ使用時にmキーを押すと、鏡像表示のON/OFFを切り替えられる。フィットネスやダンス練習時に便利。
- 日本語ラベル表示: 主要な身体部位(鼻、肩、手首、腰、足首など)に日本語名が表示される。
- 複数人物の色分け: 複数人が映っている場合、各人物が異なる色(緑、赤、青、黄、マゼンタ)で表示される。
- 骨格長の表示: 左右の上腕長がメートル単位でリアルタイム表示され、姿勢の対称性を確認できる。
- 結果の自動保存: プログラム終了時に全フレームの処理結果がresult.txtに記録される。
Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
インストール済みの場合は実行不要。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent --accept-source-agreements --accept-package-agreements
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】
Python の公式ページ: https://www.python.org/
AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AI エディタの利用を推奨する。ここでは,Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行して、Windsurfをシステム全体にインストールする。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
winget install --scope machine --id Codeium.Windsurf -e --silent --accept-source-agreements --accept-package-agreements【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
Visual Studio 2022 Build Toolsとランタイムのインストール
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Visual Studio 2022 Build Toolsとランタイムのインストール
winget install --scope machine --wait --accept-source-agreements --accept-package-agreements Microsoft.VisualStudio.2022.BuildTools Microsoft.VCRedist.2015+.x64
REM インストーラーとインストールパスの設定
set VS_INSTALLER="C:\Program Files (x86)\Microsoft Visual Studio\Installer\vs_installer.exe"
set VS_PATH="C:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools"
REM C++開発ワークロードのインストール(次のコマンドは全体で1行である)
%VS_INSTALLER% modify --installPath %VS_PATH% --add Microsoft.VisualStudio.Workload.VCTools --add Microsoft.VisualStudio.Component.VC.Tools.x86.x64 --add Microsoft.VisualStudio.Component.Windows11SDK.22621 --includeRecommended --quiet --norestart
必要なライブラリのインストール,設定
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)。し、以下を実行する。
pip install mediapipe opencv-python numpy pillow matplotlib
MediaPipe Pose Landmarker (Tasks API) 3次元人体姿勢推定プログラム
概要
このプログラムは、MediaPipe Pose Landmarker Tasks APIを用いて動画から人体の姿勢を推定するシステムである。単一のRGBカメラ映像から33個の身体ランドマークを検出し、2次元画像座標と3次元世界座標を同時に推定する[1]。Tasks APIは従来のLegacy APIに代わる最新の実装であり、より効率的な処理と柔軟な実行モードの選択が可能である。
主要技術
MediaPipe Pose Landmarker (Tasks API)
Googleが開発した最新の人体姿勢推定フレームワークである[1]。BlazePoseアーキテクチャを基盤とし、Tasks APIによる3つの実行モード(IMAGE、VIDEO、LIVE_STREAM)をサポートする。本プログラムはカメラ入力時にLIVE_STREAMモード、動画ファイル時にVIDEOモードを自動選択する[2]。
BlazePoseモデル(.taskファイル)
3段階の複雑度(Lite、Full、Heavy)を持つ外部モデルファイル(.task形式)を使用。処理速度と精度のトレードオフを調整でき、プログラムは自動的にGoogle Storageからダウンロードする。
LIVE_STREAMモード
カメラ入力時に使用される非同期処理モード。コールバック関数により効率的なリアルタイム処理を実現し、フレーム落ちを最小限に抑える。
複数人物対応と色分け表示
同時に複数人の姿勢を検出し、各人物を異なる色で表示。部位ごとの色分け(顔:赤系、上半身:緑系、下半身:青系)により視覚的な理解を促進する。
技術的特徴
座標系の出力
- pose_landmarks: 0.0-1.0の範囲で正規化された2次元画像座標
- pose_world_landmarks: メートル単位の3次元世界座標(腰部中央が原点)
- visibility: 各ランドマークの可視性スコア(0.0-1.0)
33個のランドマーク構成
顔(鼻、目、耳、口)、上半身(肩、肘、手首、指)、下半身(腰、膝、足首、かかと、足指)の合計33点を検出する[1]。
実装の特色
実行モードの自動選択
入力ソースに応じて最適な実行モードを自動選択。カメラ入力時はLIVE_STREAMモード(非同期処理)、動画ファイル時はVIDEOモード(同期処理)を使用する。
鏡像表示機能
カメラ使用時にmキーで鏡像表示を切り替え可能。フィットネスやダンス練習時に直感的な動作確認が可能。3D座標も適切に反転処理される。
骨格長計算
左右の上腕、前腕、大腿、下腿の長さをリアルタイムで計算。BONE_PAIRSの定義により正確な左右の対応を実現。
入出力システム
- 入力: tkinterによるファイル選択、OpenCVによるカメラ入力、urllib経由でのサンプル動画ダウンロード
- 出力: OpenCVウィンドウでのリアルタイム表示、Pillowによる日本語テキスト表示、result.txtへの結果保存
参考文献
[1] Google. (2025). MediaPipe Pose Landmarker. https://developers.google.com/mediapipe/solutions/vision/pose_landmarker
[2] Bazarevsky, V., et al. (2020). BlazePose: On-device Real-time Body Pose tracking. arXiv preprint arXiv:2006.10204. https://arxiv.org/abs/2006.10204
ソースコード
# プログラム名: リアルタイム3D人体姿勢推定システム(単一人物最適化版)
#
# 特徴技術名: MediaPipe Pose Landmarker (Tasks API版)
#
# 出典: Bazarevsky, V., Grishchenko, I., Raveendran, K., Zhu, T., Zhang, F., & Grundmann, M. (2020). BlazePose: On-device Real-time Body Pose tracking. arXiv preprint arXiv:2006.10204.
#
# 特徴機能: 3Dワールドランドマーク推定(単一人物専用最適化)
# 単眼カメラの映像から33個の身体キーポイントの「実世界における3D座標」をメートル単位で推定します。
# MediaPipeの単一人物検出。
#
# 学習済みモデル:
# - 名称: pose_landmarker_lite.task, pose_landmarker_full.task, pose_landmarker_heavy.task
# - 概要: Googleによって提供される学習済みモデル。精度と速度に応じて3種類から選択可能。
# - Lite: 軽量・高速なモデル。
# - Full: 精度と速度のバランスが取れた標準モデル。
# - Heavy: 最も高精度なモデルで、より多くの計算リソースを要する。
# - URL: https://storage.googleapis.com/mediapipe-models/pose_landmarker/pose_landmarker_lite/float16/1/pose_landmarker_lite.task (Lite版の例)
#
# 特徴技術および学習済モデルの利用制限:
# Apache License 2.0 に基づいて利用可能です(商用利用も可能)。
# ただし、ライセンスの詳細は利用者自身で公式情報を確認してください。
#
# 方式設計:
# - 関連利用技術:
# - OpenCV: カメラ・動画の入出力、画像処理、結果の描画・表示
# - NumPy: 3D座標データなどの数値計算
# - Matplotlib: 3D姿勢のグラフプロット
# - Pillow: 描画結果への日本語テキスト追加
# - Tkinter: ファイル選択ダイアログの表示
# - 入力と出力:
# - 入力: 動画(ユーザは「0:動画ファイル,1:カメラ,2:サンプル動画」のメニューで選択.0:動画ファイルの場合はtkinterでファイル選択.1の場合はOpenCVでカメラが開く.2の場合はhttps://raw.githubusercontent.com/opencv/opencv/master/samples/data/vtest.aviを使用)
# - 出力: 処理結果(推定された3D座標など)が描画された動画を画面にリアルタイム表示します。また、コマンドプロンプト(コンソール)にもフレームごとの推定結果をテキストで表示します。プログラム終了時には、コンソールに表示された全結果を "result.txt" というファイルに保存します。
# - 処理手順:
# 1. 利用者が入力ソース(動画ファイル/カメラ/サンプル)と使用するモデル(Lite/Full/Heavy)を選択します。
# 2. 選択されたモデルファイルをGoogleのサーバーから自動的にダウンロードします(初回のみ)。
# 3. 動画から1フレームずつ画像を取得します。
# 4. 画像をMediaPipe Pose Landmarkerに入力し、33点のランドマークの2D座標と3Dワールド座標を推定します。
# 5. 推定された3D座標に対して後処理(物理的制約の検証、時系列平滑化)を適用し、結果の安定化を図ります。
# 6. ランドマークと骨格を入力画像に描画し、3D座標などのテキスト情報を追加して画面に表示します。
# 7. 3-6の処理を動画の終わりまで、またはユーザーが'q'キーを押すまで繰り返します。
# - 前処理、後処理:
# - 前処理: MediaPipeライブラリが内部で画像の正規化などを行うため、本プログラムでは明示的な前処理は行いません。
# - 後処理: 推定結果のジッター(小刻みなブレ)を抑制し、物理的にありえない姿勢(例:極端に骨が伸びる)を補正するため、時系列平滑化と物理的制約に基づいた品質評価を行います。
# - 追加処理:
# - 物理的制約検証 (PhysicsConstraintsクラス): 左右の腕や脚の長さが対称に近いか、骨格の長さが妥当かを評価し、スコア化します。これにより、推定結果の信頼性を測ります。
# - 時系列平滑化 (TemporalSmootherクラス): 過去複数フレームの結果を用いた重み付き移動平均により、ランドマークの動きを滑らかにし、安定した出力を得ます。
# - 調整を必要とする設定値:
# - 使用モデルの選択: プログラム開始時に利用者が選択するモデル(1: Lite, 2: Full, 3: Heavy)が最も重要な設定値です。使用するPCのスペックと求める精度のバランスを考慮して選択する必要があります。
#
# 将来方策:
# 現在ユーザーが手動で選択している「使用モデル」について、プログラム実行中のフレームレート(FPS)を測定し、目標とするFPSに応じて最適なモデル(Lite/Full/Heavy)を自動的に推奨・選択する機能を実装することが考えられます。
#
# その他の重要事項:
# - ランドマークの名称を日本語で表示するために、`C:/Windows/Fonts/meiryo.ttc`(メイリオフォント)を直接指定しています。他の環境で実行する場合や、このフォントが存在しない場合は、有効なフォントパスに書き換えるか、日本語表示処理を削除する必要があります。
#
# 前準備:
# このプログラムを実行する前に、以下のコマンドを実行して必要なライブラリをインストールしてください。
# pip install opencv-python numpy mediapipe Pillow matplotlib
import cv2
import numpy as np
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
from mediapipe import solutions
from mediapipe.framework.formats import landmark_pb2
import urllib.request
import os
import time
import tkinter as tk
from tkinter import filedialog
from datetime import datetime
from PIL import Image, ImageDraw, ImageFont
import threading
from collections import deque
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# モデル情報の定義
MODELS = {
'1': {
'name': 'pose_landmarker_lite.task',
'url': 'https://storage.googleapis.com/mediapipe-models/pose_landmarker/pose_landmarker_lite/float16/1/pose_landmarker_lite.task',
'description': 'Lite版 - 軽量モデル',
'training_data': 'Yoga-Fitness データセット(約3万枚の画像)',
},
'2': {
'name': 'pose_landmarker_full.task',
'url': 'https://storage.googleapis.com/mediapipe-models/pose_landmarker/pose_landmarker_full/float16/1/pose_landmarker_full.task',
'description': 'Full版 - バランス型モデル',
'training_data': 'Yoga-Fitness + Active データセット(約6万枚の画像)',
},
'3': {
'name': 'pose_landmarker_heavy.task',
'url': 'https://storage.googleapis.com/mediapipe-models/pose_landmarker/pose_landmarker_heavy/float16/1/pose_landmarker_heavy.task',
'description': 'Heavy版 - 高精度モデル',
'training_data': 'Yoga-Fitness + Active + COCO データセット(約10万枚の画像)',
}
}
# 33個の特徴点の定義
POSE_LANDMARKS = {
0: "鼻",
1: "左目(内側)",
2: "左目",
3: "左目(外側)",
4: "右目(内側)",
5: "右目",
6: "右目(外側)",
7: "左耳",
8: "右耳",
9: "口(左端)",
10: "口(右端)",
11: "左肩",
12: "右肩",
13: "左肘",
14: "右肘",
15: "左手首",
16: "右手首",
17: "左小指",
18: "右小指",
19: "左人差し指",
20: "右人差し指",
21: "左親指",
22: "右親指",
23: "左腰",
24: "右腰",
25: "左膝",
26: "右膝",
27: "左足首",
28: "右足首",
29: "左かかと",
30: "右かかと",
31: "左足指先",
32: "右足指先"
}
# 特徴点の色設定(BGR形式)
LANDMARK_COLORS = {
# 顔関連(赤系)
0: (0, 0, 255), 1: (0, 50, 255), 2: (0, 100, 255), 3: (0, 150, 255),
4: (0, 50, 255), 5: (0, 100, 255), 6: (0, 150, 255),
7: (0, 200, 255), 8: (0, 200, 255), 9: (50, 0, 255), 10: (50, 0, 255),
# 上半身(緑系)
11: (0, 255, 0), 12: (0, 255, 0), 13: (50, 255, 0), 14: (50, 255, 0),
15: (100, 255, 0), 16: (100, 255, 0), 17: (150, 255, 0), 18: (150, 255, 0),
19: (200, 255, 0), 20: (200, 255, 0), 21: (255, 255, 0), 22: (255, 255, 0),
# 下半身(青系)
23: (255, 0, 0), 24: (255, 0, 0), 25: (255, 50, 0), 26: (255, 50, 0),
27: (255, 100, 0), 28: (255, 100, 0), 29: (255, 150, 0), 30: (255, 150, 0),
31: (255, 200, 0), 32: (255, 200, 0)
}
# 骨格ペア定義(修正版:正しい左右の対応)
BONE_PAIRS = {
'left_upper_arm': (11, 13), # 左肩→左肘
'right_upper_arm': (12, 14), # 右肩→右肘
'left_forearm': (13, 15), # 左肘→左手首
'right_forearm': (14, 16), # 右肘→右手首
'left_thigh': (23, 25), # 左腰→左膝
'right_thigh': (24, 26), # 右腰→右膝
'left_shin': (25, 27), # 左膝→左足首
'right_shin': (26, 28) # 右膝→右足首
}
# グローバル変数
frame_count = 0
results_log = []
start_time = 0
model_path = ""
detector = None
latest_result = None
latest_frame = None
result_lock = threading.Lock()
use_mirror = False # 鏡像表示フラグ
physics_constraints = None
temporal_smoother = None
current_pose_3d = None # 現在の3D姿勢データ
# フォント設定
FONT_PATH = 'C:/Windows/Fonts/meiryo.ttc'
FONT_SIZE = 12
def is_valid_2d_coordinate(x, y):
"""2D座標の有効性チェック"""
return 0 <= x <= 1 and 0 <= y <= 1 and not np.isnan(x) and not np.isnan(y)
def is_valid_3d_coordinate(x, y, z):
"""3D座標の有効性チェック(統一基準)"""
return (is_valid_2d_coordinate(x, y) and
not np.isnan(z) and z != 0)
def calculate_3d_distance_safe(pose_3d, idx1, idx2):
"""安全な3D距離計算(有効性チェック付き)"""
if (idx1 < len(pose_3d) and idx2 < len(pose_3d) and
is_valid_3d_coordinate(pose_3d[idx1][0], pose_3d[idx1][1], pose_3d[idx1][2]) and
is_valid_3d_coordinate(pose_3d[idx2][0], pose_3d[idx2][1], pose_3d[idx2][2])):
return np.linalg.norm(pose_3d[idx1][:3] - pose_3d[idx2][:3])
return None
def normalized_to_pixel(norm_x, norm_y, width, height):
"""正規化座標からピクセル座標への変換"""
return (min(int(norm_x * width), width - 1),
min(int(norm_y * height), height - 1))
class PhysicsConstraints:
def __init__(self):
self.bone_length_ratios = {
'head_neck': 0.15,
'neck_torso': 0.30,
'upper_arm': 0.18,
'forearm': 0.16,
'thigh': 0.25,
'shin': 0.25,
'foot': 0.08
}
self._cache = {}
self._cache_frame = -1
def validate_bone_lengths(self, pose_3d, frame_num=None):
"""骨格長の妥当性を検証"""
if frame_num is not None and frame_num == self._cache_frame:
if 'bone_lengths_score' in self._cache:
return self._cache['bone_lengths_score']
if pose_3d is None:
return 0.0
bone_lengths = {}
valid_joints = 0
# 各骨格の長さを計算(Z座標の有効性もチェック)
for name, (start_idx, end_idx) in BONE_PAIRS.items():
if start_idx < 33 and end_idx < 33:
# 統一された有効性チェックを使用
if (is_valid_3d_coordinate(pose_3d[start_idx][0], pose_3d[start_idx][1], pose_3d[start_idx][2]) and
is_valid_3d_coordinate(pose_3d[end_idx][0], pose_3d[end_idx][1], pose_3d[end_idx][2])):
distance = calculate_3d_distance_safe(pose_3d, start_idx, end_idx)
if distance is not None:
bone_lengths[name] = distance
valid_joints += 1
if len(bone_lengths) < 4:
return 0.3 # デフォルト値を上げる
# 左右対称性スコア計算
symmetry_score = 0.0
symmetry_count = 0
pairs = [
('left_upper_arm', 'right_upper_arm'),
('left_forearm', 'right_forearm'),
('left_thigh', 'right_thigh'),
('left_shin', 'right_shin')
]
epsilon = 0.001
for left, right in pairs:
if left in bone_lengths and right in bone_lengths:
max_length = max(bone_lengths[left], bone_lengths[right])
if max_length > epsilon:
ratio = min(bone_lengths[left], bone_lengths[right]) / max_length
symmetry_score += ratio
symmetry_count += 1
if symmetry_count > 0:
symmetry_score /= symmetry_count
else:
symmetry_score = 0.5
# 有効関節数に基づく重み付け
joint_completeness = valid_joints / len(BONE_PAIRS)
final_score = symmetry_score * 0.7 + joint_completeness * 0.3
if frame_num is not None:
self._cache_frame = frame_num
self._cache['bone_lengths_score'] = final_score
return final_score
class TemporalSmoother:
def __init__(self, window_size=15, smoothing_factor=0.1):
self.window_size = window_size
self.smoothing_factor = smoothing_factor
self.pose_history = deque(maxlen=self.window_size)
def smooth_pose(self, pose_3d):
if pose_3d is None:
return None
self.pose_history.append(pose_3d.copy())
n = len(self.pose_history)
if n < 3:
return pose_3d
poses = np.array(list(self.pose_history))
smoothed = poses[-1].copy()
# 重み付き移動平均
if n >= 5:
window_size = min(5, n)
window = poses[-window_size:]
if window_size == 5:
weights = np.array([0.1, 0.15, 0.2, 0.25, 0.3])
else:
weights = np.ones(window_size) / window_size
ma_result = np.average(window, axis=0, weights=weights)
smoothed = 0.7 * smoothed + 0.3 * ma_result
# 外れ値補正
if n >= 3:
smoothed = self._outlier_correction(smoothed, poses)
# 骨格長の一貫性維持
if n >= 2:
prev_pose = self.pose_history[-2]
smoothed = self._maintain_bone_lengths(smoothed, prev_pose)
return smoothed
def _outlier_correction(self, pose, history):
if len(history) < 3:
return pose
corrected = pose.copy()
recent = history[-3:]
outlier_threshold = 0.1 # メートル
for joint_idx in range(min(33, pose.shape[0])):
# 統一されたZ座標有効性チェック
if not is_valid_3d_coordinate(pose[joint_idx][0], pose[joint_idx][1], pose[joint_idx][2]):
continue
distances = []
for frame in recent[:-1]:
if is_valid_3d_coordinate(frame[joint_idx][0], frame[joint_idx][1], frame[joint_idx][2]):
dist = np.linalg.norm(pose[joint_idx][:3] - frame[joint_idx][:3])
distances.append(dist)
if distances and np.mean(distances) > outlier_threshold:
valid_frames = [f for f in recent if is_valid_3d_coordinate(f[joint_idx][0], f[joint_idx][1], f[joint_idx][2])]
if len(valid_frames) >= 2:
corrected[joint_idx][:3] = np.mean([f[joint_idx][:3] for f in valid_frames], axis=0)
return corrected
def _maintain_bone_lengths(self, current, previous):
corrected = current.copy()
bone_length_threshold = 0.05 # メートル
for name, (start, end) in BONE_PAIRS.items():
if start < 33 and end < 33:
# 統一されたZ座標有効性チェック
if (is_valid_3d_coordinate(current[start][0], current[start][1], current[start][2]) and
is_valid_3d_coordinate(current[end][0], current[end][1], current[end][2]) and
is_valid_3d_coordinate(previous[start][0], previous[start][1], previous[start][2]) and
is_valid_3d_coordinate(previous[end][0], previous[end][1], previous[end][2])):
prev_length = np.linalg.norm(previous[end][:3] - previous[start][:3])
curr_length = np.linalg.norm(current[end][:3] - current[start][:3])
if abs(curr_length - prev_length) > bone_length_threshold:
direction = current[end][:3] - current[start][:3]
if np.linalg.norm(direction) > 0:
direction = direction / np.linalg.norm(direction)
corrected[end][:3] = current[start][:3] + direction * prev_length
return corrected
def calculate_landmark_quality(landmarks, world_landmarks):
"""
ランドマークの品質を計算
visibility/presence属性の問題を回避し、座標の有効性に基づいて品質を評価
"""
if not landmarks or not world_landmarks:
return 0.0
valid_2d_count = 0
valid_3d_count = 0
total_landmarks = len(landmarks)
# 主要関節のインデックス(より重要な関節に重みを付ける)
key_joints = [0, 11, 12, 13, 14, 15, 16, 23, 24, 25, 26, 27, 28]
key_joint_score = 0.0
for i, (lm_2d, lm_3d) in enumerate(zip(landmarks, world_landmarks)):
# 統一された2D座標有効性チェック
if is_valid_2d_coordinate(lm_2d.x, lm_2d.y):
valid_2d_count += 1
# 統一された3D座標有効性チェック
if is_valid_3d_coordinate(lm_3d.x, lm_3d.y, lm_3d.z):
valid_3d_count += 1
# 主要関節の品質評価
if i in key_joints:
key_joint_score += 1.0
# 基本品質スコア
basic_quality = (valid_2d_count / total_landmarks) * 0.4 + (valid_3d_count / total_landmarks) * 0.6
# 主要関節品質スコア
key_joint_quality = key_joint_score / len(key_joints)
# 最終品質スコア
final_quality = basic_quality * 0.6 + key_joint_quality * 0.4
return min(1.0, max(0.0, final_quality))
def show_3d_plot(pose_3d):
"""3D座標をプロット表示"""
if pose_3d is None:
return
fig = plt.figure(figsize=(12, 10))
ax = fig.add_subplot(111, projection='3d')
x_coords = []
y_coords = []
z_coords = []
colors = []
sizes = []
for i in range(min(33, len(pose_3d))):
x = pose_3d[i][0]
y = -pose_3d[i][1] # Y軸反転
z = -pose_3d[i][2] # Z軸反転
x_coords.append(x)
y_coords.append(y)
z_coords.append(z)
# Z座標の有効性に基づく色とサイズ設定
if not np.isnan(z) and z != 0:
colors.append('red')
sizes.append(60)
elif not np.isnan(x) and not np.isnan(y):
colors.append('orange')
sizes.append(40)
else:
colors.append('gray')
sizes.append(20)
ax.scatter(x_coords, y_coords, z_coords, c=colors, s=sizes, alpha=0.8)
# 接続線の描画
for connection in solutions.pose.POSE_CONNECTIONS:
start_idx, end_idx = connection
if start_idx < len(pose_3d) and end_idx < len(pose_3d):
start_z = pose_3d[start_idx][2]
end_z = pose_3d[end_idx][2]
if not np.isnan(start_z) and not np.isnan(end_z) and start_z != 0 and end_z != 0:
ax.plot([x_coords[start_idx], x_coords[end_idx]],
[y_coords[start_idx], y_coords[end_idx]],
[z_coords[start_idx], z_coords[end_idx]],
'b-', linewidth=1, alpha=0.7)
ax.set_xlabel('X軸(左右)[m]')
ax.set_ylabel('Y軸(上下・表示反転)[m]')
ax.set_zlabel('Z軸(前後・表示反転)[m]')
ax.set_title('3次元姿勢推定結果')
ax.set_xlim([-0.5, 0.5])
ax.set_ylim([-0.5, 0.5])
ax.set_zlim([-0.5, 0.5])
ax.view_init(elev=10, azim=-90)
plt.show()
def draw_landmarks(img, landmarks, world_landmarks, is_mirrored=False):
"""ランドマークとスケルトンを描画(単一人物専用最適化版)"""
global current_pose_3d
result_text = ""
# 画像の高さと幅を取得
image_height, image_width = img.shape[:2]
# 3D座標配列の作成
pose_3d = np.zeros((33, 4), dtype=float) # visibilityを含む4次元配列
if world_landmarks:
valid_3d_points = []
bone_lengths = {}
# world_landmarksのコピーを作成(鏡像処理用)
world_landmarks_copy = list(world_landmarks)
for i, (lm, wlm) in enumerate(zip(landmarks, world_landmarks_copy)):
# 鏡像表示の場合、3D座標のx軸も反転
if is_mirrored:
pose_3d[i] = [-wlm.x, wlm.y, wlm.z, lm.visibility]
else:
pose_3d[i] = [wlm.x, wlm.y, wlm.z, lm.visibility]
if not np.isnan(wlm.z) and wlm.z != 0:
if is_mirrored:
valid_3d_points.append(f"{POSE_LANDMARKS[i]}:({-wlm.x:.3f},{wlm.y:.3f},{wlm.z:.3f})")
else:
valid_3d_points.append(f"{POSE_LANDMARKS[i]}:({wlm.x:.3f},{wlm.y:.3f},{wlm.z:.3f})")
# 新しい品質計算方法を使用
confidence = calculate_landmark_quality(landmarks, world_landmarks)
# 物理制約検証
physics_score = physics_constraints.validate_bone_lengths(pose_3d, frame_count)
# 時系列平滑化
pose_3d = temporal_smoother.smooth_pose(pose_3d)
# グローバル変数に保存
current_pose_3d = pose_3d
# 骨格長さの計算
for bone_name, (start_idx, end_idx) in BONE_PAIRS.items():
if start_idx < len(world_landmarks_copy) and end_idx < len(world_landmarks_copy):
start = world_landmarks_copy[start_idx]
end = world_landmarks_copy[end_idx]
if is_valid_3d_coordinate(start.x, start.y, start.z) and is_valid_3d_coordinate(end.x, end.y, end.z):
# 鏡像表示でも骨格長さは変わらない
length = np.sqrt((end.x - start.x)**2 + (end.y - start.y)**2 + (end.z - start.z)**2)
bone_lengths[bone_name] = length
# 結果テキスト作成(単一人物専用)
if valid_3d_points:
key_points = [p for i, p in enumerate(valid_3d_points) if i in [0, 11, 12]]
if key_points:
result_text = ",".join(key_points[:2])
# 左右の腕の長さを表示
if bone_lengths:
if 'left_upper_arm' in bone_lengths:
result_text += f" | 左上腕長:{bone_lengths['left_upper_arm']:.3f}m"
if 'right_upper_arm' in bone_lengths:
result_text += f" | 右上腕長:{bone_lengths['right_upper_arm']:.3f}m"
# 信頼度と物理スコアを追加
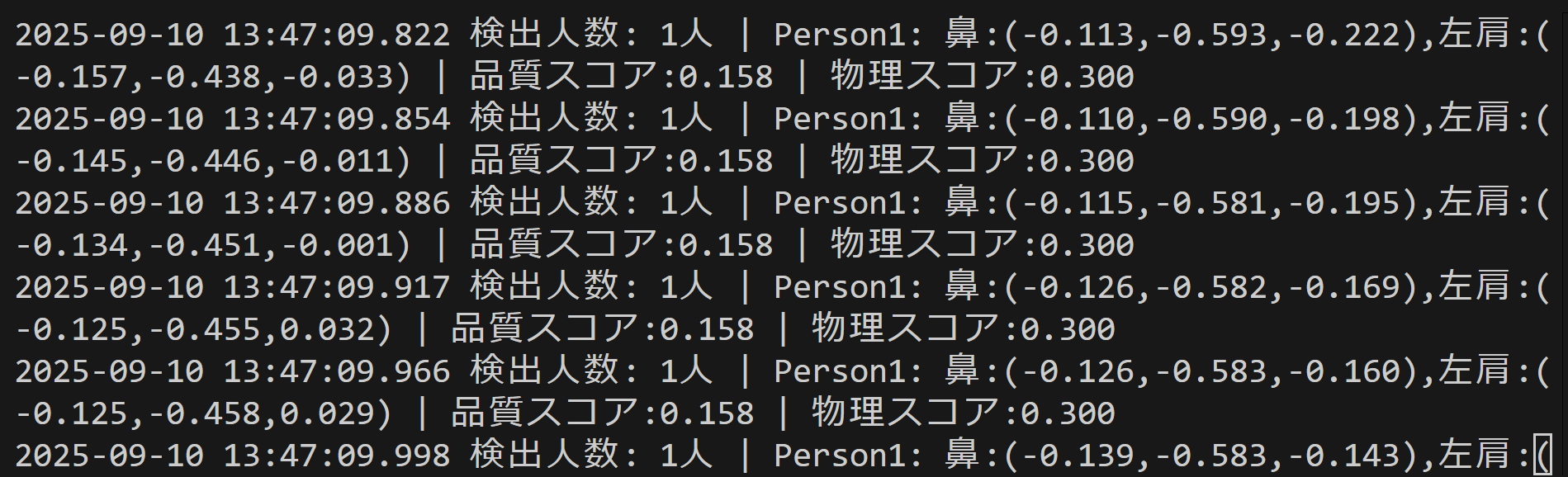
result_text += f" | 品質スコア:{confidence:.3f} | 物理スコア:{physics_score:.3f}"
else:
# world_landmarksがない場合
for i, lm in enumerate(landmarks):
pose_3d[i] = [lm.x, lm.y, np.nan, lm.visibility]
# 接続線の描画
for connection in solutions.pose.POSE_CONNECTIONS:
start_idx, end_idx = connection
if start_idx < len(landmarks) and end_idx < len(landmarks):
start_lm = landmarks[start_idx]
end_lm = landmarks[end_idx]
# 統一された可視性チェック
if is_valid_2d_coordinate(start_lm.x, start_lm.y) and is_valid_2d_coordinate(end_lm.x, end_lm.y):
# 統一された座標変換を使用
start_point = normalized_to_pixel(start_lm.x, start_lm.y, image_width, image_height)
end_point = normalized_to_pixel(end_lm.x, end_lm.y, image_width, image_height)
start_color = LANDMARK_COLORS.get(start_idx, (255, 255, 255))
end_color = LANDMARK_COLORS.get(end_idx, (255, 255, 255))
line_color = tuple((s + e) // 2 for s, e in zip(start_color, end_color))
cv2.line(img, start_point, end_point, line_color, 2)
# ランドマークポイントの描画
for idx, lm in enumerate(landmarks):
if is_valid_2d_coordinate(lm.x, lm.y): # 統一された座標有効性チェック
point = normalized_to_pixel(lm.x, lm.y, image_width, image_height)
color = LANDMARK_COLORS.get(idx, (255, 255, 255))
cv2.circle(img, point, 4, color, -1)
cv2.circle(img, point, 5, (255, 255, 255), 1)
# 日本語テキストの描画
try:
font = ImageFont.truetype(FONT_PATH, FONT_SIZE)
img_pil = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_pil)
for idx, lm in enumerate(landmarks):
if idx in [0, 11, 12, 15, 16, 23, 24, 27, 28] and is_valid_2d_coordinate(lm.x, lm.y):
point = normalized_to_pixel(lm.x, lm.y, image_width, image_height)
point = (point[0] + 5, point[1] - 5) # オフセット追加
color_rgb = LANDMARK_COLORS.get(idx, (255, 255, 255))
color_rgb = (color_rgb[2], color_rgb[1], color_rgb[0])
draw.text(point, POSE_LANDMARKS[idx], font=font, fill=color_rgb)
img = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
except:
for idx, lm in enumerate(landmarks):
if idx in [0, 11, 12, 15, 16, 23, 24, 27, 28] and is_valid_2d_coordinate(lm.x, lm.y):
point = normalized_to_pixel(lm.x, lm.y, image_width, image_height)
point = (point[0] + 5, point[1] - 5) # オフセット追加
color = LANDMARK_COLORS.get(idx, (255, 255, 255))
cv2.putText(img, str(idx), point, cv2.FONT_HERSHEY_SIMPLEX, 0.3, color, 1)
return img, result_text, pose_3d
def livestream_callback(result: vision.PoseLandmarkerResult, output_image: mp.Image, timestamp_ms: int):
"""LIVE_STREAMモード用のコールバック関数"""
global latest_result, latest_frame, frame_count
with result_lock:
frame_count += 1
latest_result = result
# BGRに変換してOpenCV形式にする(反転なし)
latest_frame = cv2.cvtColor(output_image.numpy_view(), cv2.COLOR_RGB2BGR)
def video_frame_processing(frame):
"""VIDEOモード用の処理関数(単一人物専用最適化版)"""
global frame_count, start_time, detector, current_pose_3d
current_time = time.time()
frame_count += 1
img = frame.copy()
rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# MediaPipe Tasks API用の画像形式に変換
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=rgb)
# VIDEOモードで姿勢検出実行
frame_timestamp_ms = int((current_time - start_time) * 1000)
try:
detection_result = detector.detect_for_video(mp_image, frame_timestamp_ms)
except Exception as e:
print(f"検出エラー: {e}")
return img, "検出エラー", current_time
result_text = ""
if detection_result.pose_landmarks:
# 単一人物専用:常に最初(唯一)の人物のデータを使用
landmarks = detection_result.pose_landmarks[0]
world_landmarks = detection_result.pose_world_landmarks[0] if detection_result.pose_world_landmarks else None
# 新しい品質評価と物理制約検証
if world_landmarks:
# pose_3dを作成
pose_3d = np.zeros((33, 4))
for i, lm in enumerate(world_landmarks):
pose_3d[i] = [lm.x, lm.y, lm.z, lm.visibility]
# 物理制約スコア計算
physics_score = physics_constraints.validate_bone_lengths(pose_3d, frame_count)
# 時系列平滑化
pose_3d = temporal_smoother.smooth_pose(pose_3d)
# グローバル変数に保存
current_pose_3d = pose_3d
img, person_result, _ = draw_landmarks(img, landmarks, world_landmarks, is_mirrored=False)
if person_result:
result_text = person_result
else:
result_text = "人物未検出"
# モデル名とAPIモードを画面に表示
cv2.putText(img, f"Model: {os.path.basename(model_path)} | Mode: VIDEO", (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 255, 255), 2)
return img, result_text, current_time
# 初期化
physics_constraints = PhysicsConstraints()
temporal_smoother = TemporalSmoother()
# プログラム開始
print("\n=== リアルタイム3D人体姿勢推定システム (MediaPipe Tasks API - 単一人物最適化版) ===")
print("このプログラムは、MediaPipe Pose Landmarker Tasks APIを使用して")
print("リアルタイムで人体の3D姿勢を推定します。")
print("\n操作方法:")
print(" q キー: プログラム終了")
print(" m キー: 鏡像表示の切り替え(カメラ使用時)")
print(" s キー: 3Dプロット表示")
print("")
# モデル選択とダウンロード処理
print("\n" + "="*60)
print("MediaPipe Pose Landmarker モデル選択")
print("="*60)
for key, model in MODELS.items():
print(f"\n[{key}] {model['description']}")
print(f" モデル名: {model['name']}")
print(f" 学習データ: {model['training_data']}")
print("\n" + "="*60)
while True:
choice = input("使用するモデルを選択してください (1-3): ")
if choice in MODELS:
selected_model = MODELS[choice]
print(f"\n選択されたモデル: {selected_model['description']}")
model_path = selected_model['name']
if not os.path.exists(model_path):
print(f"\nモデルをダウンロード中: {selected_model['name']}")
try:
urllib.request.urlretrieve(selected_model['url'], model_path)
print(f"ダウンロード完了: {model_path}")
break
except Exception as e:
print(f"ダウンロードエラー: {e}")
print("モデルのダウンロードに失敗しました。別のモデルを選択してください。")
else:
print(f"モデルは既に存在します: {model_path}")
break
else:
print("無効な選択です。1-3の数字を入力してください。")
# 動画入力選択
print("\n動画入力選択")
print("0: 動画ファイル")
print("1: カメラ")
print("2: サンプル動画")
choice = input("選択: ")
# MediaPipe Tasks APIの初期化(正しいモード選択)
# モデルをファイルパスで読み込み
base_options = python.BaseOptions(model_asset_path=model_path)
if choice == '1':
# カメラの場合はLIVE_STREAMモード
# コールバック関数を事前に定義
def result_callback(result: vision.PoseLandmarkerResult, output_image: mp.Image, timestamp_ms: int):
global latest_result, latest_frame, frame_count
with result_lock:
frame_count += 1
latest_result = result
latest_frame = cv2.cvtColor(output_image.numpy_view(), cv2.COLOR_RGB2BGR)
options = vision.PoseLandmarkerOptions(
base_options=base_options,
running_mode=vision.RunningMode.LIVE_STREAM,
min_pose_detection_confidence=0.5,
min_pose_presence_confidence=0.5,
min_tracking_confidence=0.5,
output_segmentation_masks=False,
result_callback=result_callback
)
detector = vision.PoseLandmarker.create_from_options(options)
print(f"\nTasks API実行モード: LIVE_STREAM (カメラ入力)")
use_mirror = True # カメラの場合はデフォルトで鏡像表示
else:
# 動画ファイルの場合はVIDEOモード
options = vision.PoseLandmarkerOptions(
base_options=base_options,
running_mode=vision.RunningMode.VIDEO,
min_pose_detection_confidence=0.5,
min_pose_presence_confidence=0.5,
min_tracking_confidence=0.5,
output_segmentation_masks=False
)
detector = vision.PoseLandmarker.create_from_options(options)
print(f"\nTasks API実行モード: VIDEO (動画ファイル入力)")
if choice == '0':
root = tk.Tk()
root.withdraw()
path = filedialog.askopenfilename()
if not path:
exit()
cap = cv2.VideoCapture(path)
elif choice == '1':
cap = cv2.VideoCapture(0, cv2.CAP_DSHOW)
if not cap.isOpened():
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
else:
# サンプル動画ダウンロード
SAMPLE_URL = 'https://raw.githubusercontent.com/opencv/opencv/master/samples/data/vtest.avi'
SAMPLE_FILE = 'vtest.avi'
print("サンプル動画をダウンロード中...")
try:
urllib.request.urlretrieve(SAMPLE_URL, SAMPLE_FILE)
print("ダウンロード完了")
except Exception as e:
print(f"サンプル動画のダウンロードに失敗しました: {e}")
exit()
cap = cv2.VideoCapture(SAMPLE_FILE)
if not cap.isOpened():
print('動画ファイル・カメラを開けませんでした')
exit()
start_time = time.time()
# メイン処理
print('\n=== 動画処理開始 ===')
print('操作方法:')
print(' q キー: プログラム終了')
if choice == '1':
print(' m キー: 鏡像表示の切り替え')
print(' s キー: 3Dプロット表示')
try:
while True:
ret, frame = cap.read()
if not ret:
break
MAIN_FUNC_DESC = "3D人体姿勢推定(単一人物最適化版)"
if choice == '1':
# LIVE_STREAMモード(カメラ)- 単一人物専用最適化
# 鏡像表示の適用
display_frame = cv2.flip(frame, 1) if use_mirror else frame
rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # 処理は元のフレームで行う
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=rgb)
# 非同期処理のためタイムスタンプを計算
frame_timestamp_ms = int((time.time() - start_time) * 1000)
detector.detect_async(mp_image, frame_timestamp_ms)
# コールバックで処理された最新結果を取得
with result_lock:
if latest_frame is not None:
processed_frame = latest_frame.copy()
# 表示用に鏡像変換を適用
if use_mirror:
processed_frame = cv2.flip(processed_frame, 1)
if latest_result and latest_result.pose_landmarks:
# 単一人物専用:常に最初(唯一)の人物のデータを使用
landmarks = latest_result.pose_landmarks[0]
world_landmarks = latest_result.pose_world_landmarks[0] if latest_result.pose_world_landmarks else None
# 鏡像表示の場合、ランドマークのx座標を反転
if use_mirror:
for lm in landmarks:
lm.x = 1.0 - lm.x
processed_frame, result, _ = draw_landmarks(processed_frame, landmarks, world_landmarks, is_mirrored=use_mirror)
else:
result = "人物未検出"
# モデル名とAPIモードを画面に表示
cv2.putText(processed_frame, f"Model: {os.path.basename(model_path)} | Mode: LIVE_STREAM | Mirror: {use_mirror}", (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 255, 255), 2)
else:
processed_frame = display_frame
result = "初期化中..."
current_time = time.time()
print(datetime.fromtimestamp(current_time).strftime("%Y-%m-%d %H:%M:%S.%f")[:-3], result)
else:
# VIDEOモード(動画ファイル)
processed_frame, result, current_time = video_frame_processing(frame)
print(f"Frame {frame_count}: {result}")
cv2.imshow(MAIN_FUNC_DESC, processed_frame)
results_log.append(result)
key = cv2.waitKey(1) & 0xFF
if key == ord('q'):
break
elif key == ord('m') and choice == '1':
use_mirror = not use_mirror
print(f"鏡像表示: {'ON' if use_mirror else 'OFF'}")
elif key == ord('s'):
# 3Dプロット表示
if current_pose_3d is not None:
show_3d_plot(current_pose_3d)
finally:
print('\n=== プログラム終了 ===')
cap.release()
cv2.destroyAllWindows()
detector.close()
if results_log:
with open('result_optimized.txt', 'w', encoding='utf-8') as f:
f.write('=== 3D人体姿勢推定結果 (MediaPipe Tasks API - 単一人物最適化版) ===\n')
f.write(f'処理フレーム数: {frame_count}\n')
f.write(f'使用モデル: {model_path}\n')
f.write(f'APIバージョン: MediaPipe Tasks API (非Legacy)\n')
f.write(f'実行モード: {"LIVE_STREAM" if choice == "1" else "VIDEO"}\n')
f.write(f'最適化: 単一人物検出専用\n')
f.write('\n')
f.write('\n'.join(results_log))
print(f'\n処理結果をresult_optimized.txtに保存しました')
print("\nプログラムを終了しました。")
技術詳細
概要
MediaPipe Pose Landmarker Tasks APIは、Googleが開発したMediaPipeフレームワークにおける最新の人体姿勢推定技術である。単一のカメラ映像から人体の33個のランドマーク点を2次元画像座標と3次元世界座標で推定する。Legacy APIに代わる新しい実装であり、BlazePoseアーキテクチャに基づいている。
基本仕様
- 入力形式: 動画ファイル、カメラ、サンプル動画
- 出力形式: 33個のランドマーク(pose_landmarksとpose_world_landmarks)
- 世界座標系: 腰部中央を原点とする3次元座標(メートル単位)
- モデル: 3種類(pose_landmarker_lite.task、pose_landmarker_full.task、pose_landmarker_heavy.task)
- 実行モード: VIDEO(動画ファイル)、LIVE_STREAM(カメラ)
- 検出信頼度閾値: min_pose_detection_confidence(0.5)
- トラッキング信頼度閾値: min_tracking_confidence(0.5)
処理フロー
Tasks APIの処理フローは入力に応じて最適化される。
【VIDEOモード(動画ファイル)】 ┌─────────────┐ ┌──────────────────┐ ┌─────────────────┐ │ 動画フレーム │───→│ detect_for_video │───→│ 同期処理で結果 │ │ +タイムスタンプ│ │ (同期処理) │ │ を即座返却 │ └─────────────┘ └──────────────────┘ └─────────────────┘ 【LIVE_STREAMモード(カメラ)】 ┌─────────────┐ ┌──────────────────┐ ┌─────────────────┐ │ カメラフレーム │───→│ detect_async │───→│ コールバック関数 │ │ +タイムスタンプ│ │ (非同期処理) │ │ で結果受信 │ └─────────────┘ └──────────────────┘ └─────────────────┘
座標系と出力データ
- pose_landmarks: 画像内の相対位置(0.0-1.0の範囲)
- pose_world_landmarks: メートル単位の3次元座標
- 各ランドマーク属性: x, y, z座標、visibility(0.0-1.0)
- 鏡像表示時: x座標を反転(2D: 1.0-x、3D: -x)
33個のランドマーク点配置(正しい左右対応)
0(鼻)
/ \
1(左目内) 2(左目) 3(左目外) 4(右目内) 5(右目) 6(右目外)
7(左耳) 8(右耳)
9(口左) 10(口右)
11(左肩) 12(右肩)
| |
13(左肘) 14(右肘)
| |
15(左手首) 16(右手首)
| |
17(左小指) 19(左人差指) 18(右小指) 20(右人差指)
| | | |
21(左親指) 22(右親指)
23(左腰) 24(右腰)
| |
25(左膝) 26(右膝)
| |
27(左足首) 28(右足首)
| |
29(左かかと) 31(左足指) 30(右かかと) 32(右足指)
骨格ペアの定義(BONE_PAIRS)
正しい左右の対応: 'left_upper_arm': (11, 13) # 左肩(11) → 左肘(13) 'right_upper_arm': (12, 14) # 右肩(12) → 右肘(14) 'left_forearm': (13, 15) # 左肘(13) → 左手首(15) 'right_forearm': (14, 16) # 右肘(14) → 右手首(16) 'left_thigh': (23, 25) # 左腰(23) → 左膝(25) 'right_thigh': (24, 26) # 右腰(24) → 右膝(26) 'left_shin': (25, 27) # 左膝(25) → 左足首(27) 'right_shin': (26, 28) # 右膝(26) → 右足首(28)
姿勢・動作分析機能
- モデル選択: 1でLite版、2でFull版、3でHeavy版を選択(自動ダウンロード)
- 動画入力選択: 0で動画ファイル(tkinter使用)、1でカメラ、2でサンプル動画
- 実行モード自動選択: カメラ時LIVE_STREAM、動画時VIDEO
- リアルタイム表示: OpenCVウィンドウに推定結果と骨格長を表示
- 複数人物検出: 同時に複数人を検出し、異なる色で表示
- 部位別色分け: 顔(赤系)、上半身(緑系)、下半身(青系)
- 鏡像表示切り替え: カメラ時にmキーで切り替え(フィットネス用途)
- 日本語ラベル: Pillowによる主要部位の日本語名表示
- 骨格長計算: 左右の上腕、前腕、大腿、下腿の長さをメートル単位で表示
- 結果保存: 処理結果をresult.txtファイルに自動保存