OLLAMA LLaVA 1.6 による Visual Question Answering(ソースコードと実行結果)
Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
インストール済みの場合は実行不要。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent --accept-source-agreements --accept-package-agreements
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】
Python の公式ページ: https://www.python.org/
AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AI エディタの利用を推奨する。ここでは,Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行して、Windsurfをシステム全体にインストールする。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
winget install --scope machine --id Codeium.Windsurf -e --silent --accept-source-agreements --accept-package-agreements【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
必要なライブラリをシステム領域にインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する
pip install ollama pillow opencv-python
OLLAMA LLaVA 1.6 による Visual Question Answering プログラム
ソースコード
# プログラム名: OLLAMA LLaVA 1.6 による Visual Question Answering プログラム
# 特徴技術名: LLaVA (Large Language and Vision Assistant) v1.6
# 出典: Liu, H., Li, C., Wu, Q., & Lee, Y. J. (2024). Visual Instruction Tuning. NeurIPS.
# 特徴機能: Vision-Language Understanding - 画像とテキストを同時に理解し、画像に関する質問に自然言語で回答
#
# === LLaVA 1.6 公式仕様情報(2024年1月リリース) ===
# 主要改善点:
# - 4倍高解像度対応(最大672x672、336x1344、1344x336)
# - OCR機能強化と視覚推論改善、文書・図表・図解データセット追加学習
# - 多様なシナリオ対応の会話能力向上
# - 世界知識と論理推論能力強化
# - Apache 2.0 / LLaMA 2 Community Licenseによる寛容なライセンス
# ベンチマーク性能:
# - GPT-4比較相対スコア: 85.1%
# - ScienceQA精度: 90.92%
# - 視覚会話ベンチマークで優秀な性能
#
# 学習済みモデル詳細:
# - llava:13b (13Bパラメータ、Q4_K_M量子化、8.0GB、推奨RAM:16GB+、バランス型)
# - llava:34b (34Bパラメータ、Q4_K_M量子化、21GB、推奨RAM:32GB+、最高精度)
# - llava-llama3:8b (Llama3ベース8Bパラメータ、Q4_K_M量子化、4.9GB、推奨RAM:8GB+、軽量高速)
# URL: https://ollama.com/library/llava
#
# === OLLAMA生成パラメータ公式仕様 ===
# top_p: 核サンプリング(0.1-1.0、デフォルト0.9、確率質量閾値)
# top_k: トークン選択範囲(1-100、デフォルト40、候補数制限)
# num_ctx: コンテキストウィンドウ(デフォルト4096、メモリ使用量に影響)
# num_predict: 最大生成トークン数(デフォルト128、-1=無制限、-2=コンテキスト埋め)
# repeat_penalty: 繰り返しペナルティ(デフォルト1.1、高値=繰り返し抑制)
# repeat_last_n: 繰り返し検出範囲(デフォルト64、0=無効、-1=num_ctx)
# 注意: temperatureパラメータはLLaVAモデルでサーバーハング問題があるため除外
import ollama
import subprocess
import sys
import time
import base64
import io
import os
import cv2
import tkinter as tk
from tkinter import filedialog
import urllib.request
from PIL import Image
import re
# === 定数定義 ===
OLLAMA_PATHS = [
"ollama",
rf"C:\Users\{os.getenv('USERNAME')}\AppData\Local\Programs\Ollama\ollama.exe",
r"C:\Program Files\Ollama\ollama.exe",
r"C:\Program Files\WinGet\Links\ollama.exe"
]
MODELS = [
("llava:13b", "8.0GB", "推奨バランス型"),
("llava:34b", "21GB", "最高精度"),
("llava-llama3:8b", "4.9GB", "軽量高速")
]
DEFAULT_MODEL = "llava:13b"
MAX_SIZE = 1024
# === 生成パラメータ設定(公式仕様準拠、temperature除外) ===
GENERATION_PARAMS = {
"top_p": 0.9, # 核サンプリング(デフォルト0.9)
"top_k": 40, # トークン選択範囲(デフォルト40)
"num_ctx": 4096, # コンテキストウィンドウ(デフォルト4096)
"num_predict": 256, # 最大生成トークン数(デフォルト128)
"repeat_penalty": 1.1, # 繰り返しペナルティ(デフォルト1.1)
"repeat_last_n": 64, # 繰り返し検出範囲(デフォルト64)
"seed": -1 # ランダムシード(-1で無指定)
}
# === プロンプトテンプレート標準化 ===
PROMPT_TEMPLATES = {
"question_answer": "Question: {question}\nAnswer:",
"detailed_description": "Image Description Request: {question}\nDetailed Description:",
"analysis": "Visual Analysis Task: {question}\nAnalysis Result:",
"conversation": "この画像について日本語で詳しく答えてください: {question}"
}
SAMPLE_URLS = [
"https://raw.githubusercontent.com/opencv/opencv/master/samples/data/fruits.jpg",
"https://raw.githubusercontent.com/opencv/opencv/master/samples/data/messi5.jpg",
"https://raw.githubusercontent.com/opencv/opencv/master/samples/data/aero3.jpg",
"https://upload.wikimedia.org/wikipedia/commons/3/3a/Cat03.jpg"
]
QUESTIONS = [
"Question: この画像には何が写っていますか? Answer:",
"Question: この画像の詳細を説明してください Answer:",
"Question: この画像の色や雰囲気について教えてください Answer:"
]
print("OLLAMA LLaVA 1.6 VQA システム(改良版)")
print("画像を入力し、質問に対する回答を生成します\n")
# OLLAMA確認と起動
ollama_path = None
for path in OLLAMA_PATHS:
try:
subprocess.run([path, "--version"], capture_output=True, check=True)
ollama_path = path
break
except:
continue
if not ollama_path:
print("エラー: OLLAMAがインストールされていません")
exit()
try:
ollama.list()
except:
subprocess.Popen([ollama_path, "serve"], stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL)
time.sleep(3)
# モデル選択
print("利用可能モデル:")
for i, (model, size, desc) in enumerate(MODELS, 1):
print(f"{i}. {model} ({size}) - {desc}")
print("Enter: デフォルト(llava:13b)を使用")
choice = input("\nモデル番号 (Enterでデフォルト): ")
model_name = DEFAULT_MODEL if choice == "" else MODELS[int(choice) - 1][0]
# パラメータ設定(temperature除外)
current_params = {
"top_p": 0.9,
"top_k": 40,
"num_ctx": 4096,
"num_predict": 256,
"repeat_penalty": 1.1,
"repeat_last_n": 64,
"seed": -1
}
# モデル確認とダウンロード
try:
model_list = ollama.list()
installed = []
if isinstance(model_list, dict) and 'models' in model_list:
installed = [m.get('name', '') for m in model_list.get('models', [])]
if model_name not in installed:
print(f"{model_name} をダウンロード中...")
try:
for progress in ollama.pull(model_name, stream=True):
if 'status' in progress:
print(f"\r{progress.get('status', '')}", end='', flush=True)
except TypeError:
ollama.pull(model_name)
print(f"\n{model_name} ダウンロード完了")
except Exception as e:
print(f"エラー: {e}")
exit()
results = []
def extract_response(response_text):
"""レスポンスからAnswer:以降の部分を抽出"""
match = re.search(r"Answer:\s*(.*?)(?:\n|$)", response_text, re.DOTALL)
if match:
return match.group(1).strip()
return response_text
def process_image(img):
if img is None:
print("画像の読み込みに失敗しました")
return
# 画像のリサイズ処理
height, width = img.shape[:2]
if width > MAX_SIZE or height > MAX_SIZE:
scale = MAX_SIZE / max(width, height)
new_width = int(width * scale)
new_height = int(height * scale)
img_resized = cv2.resize(img, (new_width, new_height))
else:
img_resized = img
# 質問選択
print("\n質問:")
for i, q in enumerate(QUESTIONS, 1):
print(f"{i}. {q}")
print("4. 自由入力")
q_choice = int(input("選択: "))
if q_choice <= 3:
prompt = QUESTIONS[q_choice-1]
else:
question = input("質問: ")
prompt = f"Question: {question} Answer:"
# Base64エンコード
pil_img = Image.fromarray(cv2.cvtColor(img_resized, cv2.COLOR_BGR2RGB))
buffer = io.BytesIO()
pil_img.save(buffer, format='PNG')
# 推論実行
print("回答生成中...")
response = ollama.generate(
model=model_name,
prompt=f"この画像について日本語で詳しく答えてください: {prompt}",
images=[base64.b64encode(buffer.getvalue()).decode()],
options=current_params
)
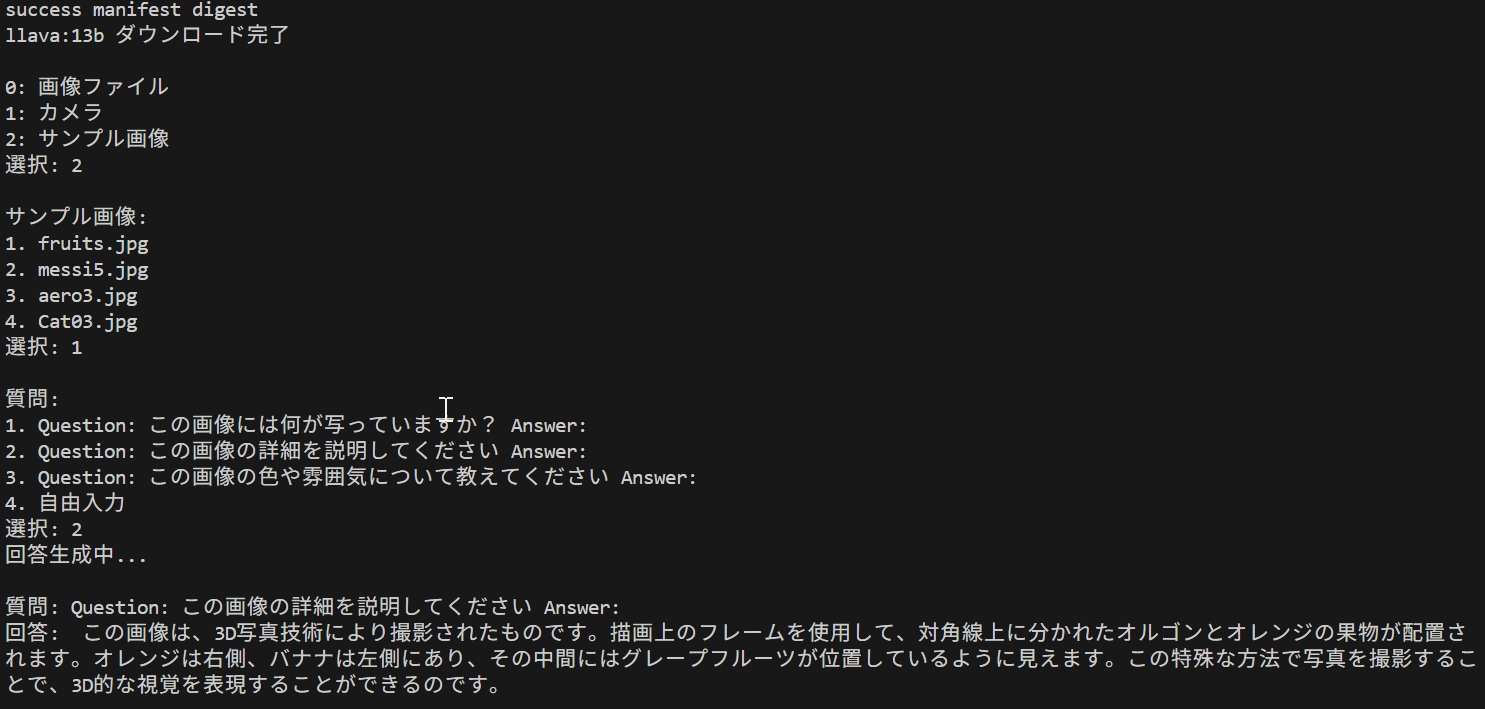
result = f"\n質問: {prompt}\n回答: {response['response']}\n"
print(result)
results.append(result)
cv2.imshow('Image', img)
cv2.waitKey(0)
print("\n0: 画像ファイル")
print("1: カメラ")
print("2: サンプル画像")
choice = input("選択: ")
if choice == '0':
root = tk.Tk()
root.withdraw()
paths = filedialog.askopenfilenames()
if not paths:
exit()
for path in paths:
process_image(cv2.imread(path))
elif choice == '1':
cap = cv2.VideoCapture(0, cv2.CAP_DSHOW)
print("\nスペースキー: 撮影, Qキー: 終了")
try:
while True:
cap.grab()
ret, frame = cap.retrieve()
if not ret:
break
cv2.imshow('Camera', frame)
key = cv2.waitKey(1) & 0xFF
if key == ord(' '):
process_image(frame)
elif key == ord('q'):
break
finally:
cap.release()
elif choice == '2':
print("\nサンプル画像:")
print("1. fruits.jpg")
print("2. messi5.jpg")
print("3. aero3.jpg")
print("4. Cat03.jpg")
idx = int(input("選択: ")) - 1
filename = f"sample_{idx}.jpg"
try:
urllib.request.urlretrieve(SAMPLE_URLS[idx], filename)
process_image(cv2.imread(filename))
os.remove(filename)
except Exception as e:
print(f"画像のダウンロードに失敗しました: {e}")
exit()
cv2.destroyAllWindows()
# 結果保存
if results:
with open('result.txt', 'w', encoding='utf-8') as f:
f.writelines(results)