InsightFaceによる68点3Dランドマーク検出
【概要】 InsightFaceフレームワークの68点3Dランドマーク検出技術を用いた顔解析プログラムの実装と実験を行う。68点3Dランドマーク検出は顔の主要な 特徴点を3次元座標で特定する技術である。Webカメラから顔と68点ランドマークを検出する。Windows環境での実行手順、プログラムコード、実験アイデアを含む。
目次
1. はじめに
68点3Dランドマーク検出技術
InsightFaceは顔認識・解析のための統合フレームワークであり、68点3Dランドマーク検出はその中で使用される顔特徴点抽出アルゴリズムの一つである。ランドマーク検出は画像から顔の主要な解剖学的特徴点の位置を特定する技術であり、顔認識、表情解析、3D顔面復元の前段階として使用される。
技術名: 1k3d68(68点3次元顔面ランドマーク検出)
フレームワーク: InsightFace(深層学習ベースの顔解析ツールボックス)
GitHub: https://github.com/deepinsight/insightface
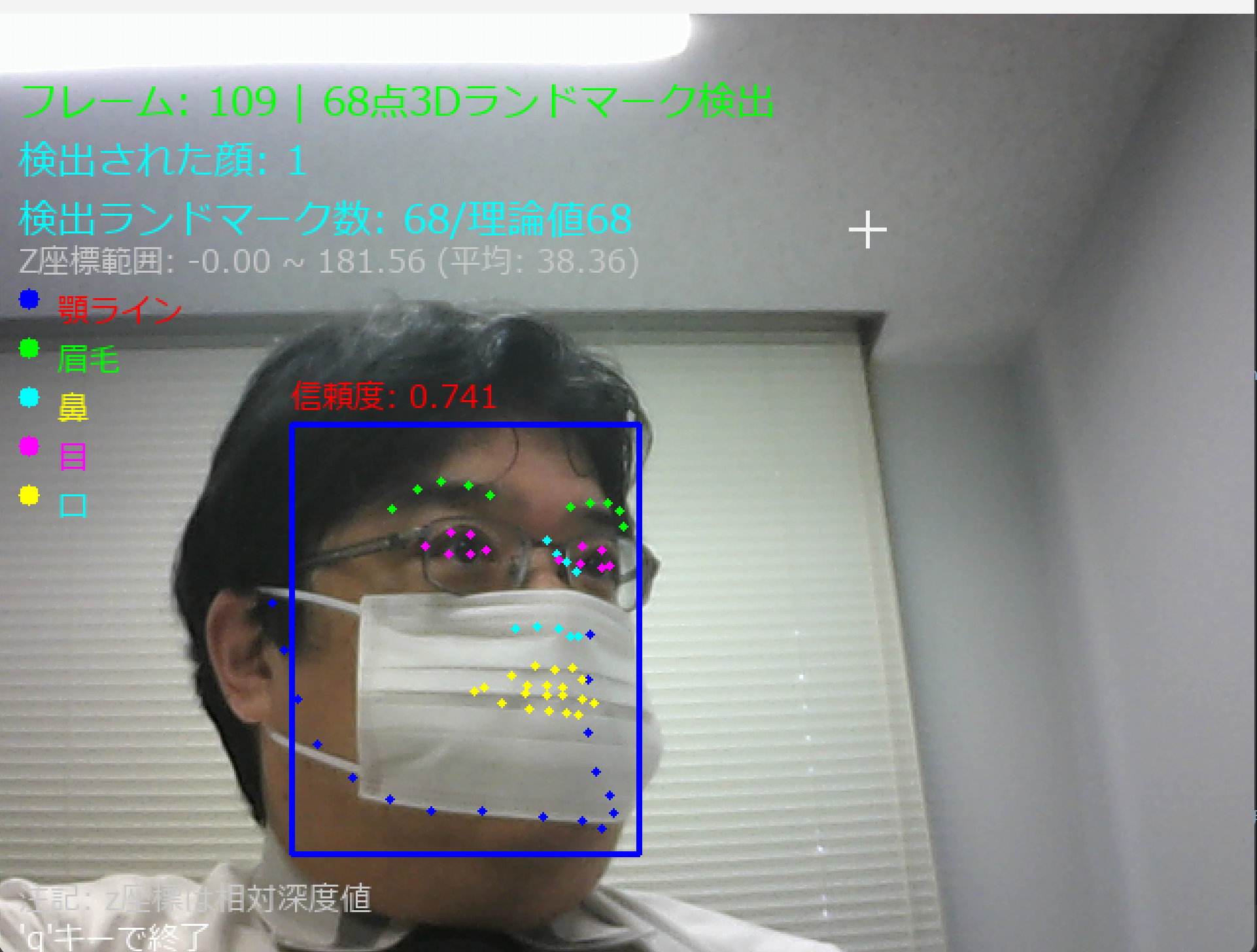
68点3Dランドマーク検出は顔の主要な解剖学的特徴点を3次元座標(x, y, z)で特定することを特徴とする顔解析技術である。Webカメラからの映像をリアルタイムで処理し、顔検出と68点ランドマーク(顎のライン、眉毛、目、鼻、口の詳細な特徴点)の検出を実行する。
68点ランドマークの構成
- 顎のライン(1-17点): 顔の輪郭を定義する点
- 右眉毛(18-22点): 右眉の形状を表現する点
- 左眉毛(23-27点): 左眉の形状を表現する点
- 鼻(28-36点): 鼻梁と鼻先の形状を表現する点
- 右目(37-42点): 右目の輪郭を表現する点
- 左目(43-48点): 左目の輪郭を表現する点
- 口(49-68点): 唇の外側と内側の形状を表現する点
2. Python開発環境,ライブラリ類
Python 3.12 のインストール
インストール済みの場合は実行不要。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent --accept-source-agreements --accept-package-agreements
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】
Python の公式ページ: https://www.python.org/
AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AI エディタの利用を推奨する。ここでは,Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行して、Windsurfをシステム全体にインストールする。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
winget install --scope machine --id Codeium.Windsurf -e --silent --accept-source-agreements --accept-package-agreements【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
CMakeのインストール
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
REM CMake をシステム領域にインストール
winget install --scope machine --id Kitware.CMake -e --silent
REM CMake のパス設定
set "GMAKE_PATH=C:\Program Files\CMake\bin"
if exist "%GMAKE_PATH%" (
echo "%PATH%" | find /i "%GMAKE_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%GMAKE_PATH%" /M >nul
)
必要なライブラリをシステム領域にインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する
pip install insightface opencv-python onnxruntime pillow
3. プログラムコード
概要
このプログラムは、InsightFaceフレームワークを用いて動画や静止画から顔を検出し、68点の3次元顔ランドマーク(特徴点)を抽出・可視化する。顔の各部位(顎ライン、眉毛、鼻、目、口)を色分けして表示し、各ランドマークのx, y座標に加えて相対深度情報(z座標)も取得する。リアルタイム処理に対応し、カメラ入力と動画ファイル入力の両方をサポートする。
主要技術
InsightFace
深層学習ベースの顔解析フレームワークであり、顔検出、顔認識、顔属性推定、顔ランドマーク検出などの機能を統合的に提供する[1]。本プログラムでは、buffalo_lモデルによる顔検出とlandmark_3d_68モジュールによる68点3Dランドマーク検出を組み合わせて使用している。
68点顔ランドマークモデル
顔の主要な特徴点を68個の座標として表現する標準的な顔ランドマーク表現方式である[2]。顎ライン(1-17番)、右眉毛(18-22番)、左眉毛(23-27番)、鼻(28-36番)、右目(37-42番)、左目(43-48番)、口(49-68番)の各部位に対応する点群で構成される。
技術的特徴
本実装では、2次元座標に加えて相対深度値(z座標)を取得し、3次元的な顔形状情報を抽出する。z座標はカメラからの相対的な奥行きを表し、顔の立体構造を把握するための重要な情報となる。検出されたランドマークは部位ごとに異なる色で可視化され、視覚的に理解しやすい表示を実現している。
処理性能の面では、ONNXRuntimeを活用した推論により、リアルタイム処理を可能にしている。検出サイズを640×640ピクセルに設定することで、精度と処理速度のバランスを取っている。
実装の特色
- 日本語表示対応:PillowライブラリとMeiryoフォントを使用し、画面上に日本語でガイダンスや統計情報を表示
- z座標統計情報:検出された全ランドマークのz座標から最小値、最大値、平均値を算出し、深度分布を可視化
- 実測値と理論値の比較:実際に検出されたランドマーク数と理論値(顔数×68)を並列表示し、検出品質を評価可能
- 多様な入力ソース:動画ファイル、Webカメラ、サンプル動画の3種類の入力に対応
- 結果の永続化:処理結果をresult.txtファイルに自動保存し、後から分析可能
参考文献
[1] Guo, J., Deng, J., Lattas, A., & Zafeiriou, S. (2021). Sample and Computation Redistribution for Efficient Face Detection. arXiv preprint arXiv:2105.04714. https://arxiv.org/abs/2105.04714
[2] Sagonas, C., Antonakos, E., Tzimiropoulos, G., Zafeiriou, S., & Pantic, M. (2016). 300 Faces In-The-Wild Challenge: database and results. Image and Vision Computing, 47, 3-18. https://doi.org/10.1016/j.imavis.2016.01.002
ソースコード
# InsightFace 68点3Dランドマーク検出プログラム(3Dモード)
# 特徴技術名: InsightFace - 深層学習ベースの顔解析フレームワーク
# 出典: Deng, J., Guo, J., Ververas, E., Kotsia, I., & Zafeiriou, S. (2020).
# RetinaFace: Single-Shot Multi-Level Face Localisation in the Wild. In CVPR.
# 特徴機能: 68点3Dランドマーク検出(顎ライン1-17、眉毛18-27、鼻28-36、目37-48、口49-68)
# 学習済みモデル: buffalo_l + landmark_3d_68(公式配布を想定。環境により利用可否が異なる)
# I/O仕様:
# 入力: 0=動画ファイル, 1=カメラ, 2=サンプル動画(vtest.avi)
# 出力: 画面表示(Pillow+OpenCVで日本語)、終了時にresult.txtへ保存
# 注記: z座標はモデル内部の相対値(物理的距離ではない)
# 事前準備: pip install insightface opencv-python onnxruntime pillow
import cv2
import numpy as np
from insightface.app import FaceAnalysis
from PIL import Image, ImageDraw, ImageFont
import os
import tkinter as tk
from tkinter import filedialog
import urllib.request
import time
from datetime import datetime
import sys
# 定数定義
CTX_ID = 0
DET_SIZE = (640, 640)
FONT_COLOR_INFO = (0, 255, 0) # BGR
FONT_COLOR_COUNT = (0, 255, 255) # BGR
BBOX_COLOR = (255, 0, 0) # BGR
LM_COLOR = (0, 255, 0) # BGR
LM_RADIUS = 2
# 日本語フォント設定(Meiryo)
FONT_PATH = 'C:/Windows/Fonts/meiryo.ttc'
FONT_SIZE = 20
FONT_SIZE_SMALL = 16
# ランドマーク色(部位別、BGR)
LANDMARK_COLORS = {
'jawline': (255, 0, 0),
'right_eyebrow': (0, 255, 0),
'left_eyebrow': (0, 255, 0),
'nose': (255, 255, 0),
'right_eye': (255, 0, 255),
'left_eye': (255, 0, 255),
'mouth': (0, 255, 255)
}
# ガイダンス
print("=" * 60)
print("InsightFace 68点3Dランドマーク検出プログラム(3Dモード)")
print("=" * 60)
print("\n【概要説明】")
print("このプログラムは、動画から顔を検出し、")
print("68点の3次元ランドマーク(特徴点)を抽出・表示する。")
print("\n【操作方法】")
print("- 'q'キー: プログラムを終了")
print("- カメラまたは動画に顔を向けると自動的に検出を開始する")
print("\n【注意事項】")
print("- 適切な照明環境で使用する")
print("- カメラから適度な距離(50-100cm)を保つ")
print("- landmark_3d_68モデルが必要(未提供時は起動時に終了)")
print("- z座標はモデル内部の相対値(物理的距離ではない)")
print("-" * 60)
# 結果記録
results_log = []
frame_count = 0
# FaceAnalysis 初期化(3D)
try:
app = FaceAnalysis(name='buffalo_l', allowed_modules=['detection', 'landmark_3d_68'])
app.prepare(ctx_id=CTX_ID, det_size=DET_SIZE)
available_modules = set(getattr(app, 'models', {}).keys()) if hasattr(app, 'models') else set()
print(f"利用可能モジュール: {sorted(available_modules)}")
if 'landmark_3d_68' not in available_modules:
print("エラー: 'landmark_3d_68' モジュールが利用できないため終了する。")
sys.exit(1)
print("68点3Dランドマーク検出モデル(landmark_3d_68)をロードした。")
except Exception as e:
print(f"エラー: insightfaceの初期化に失敗: {e}")
sys.exit(1)
# 日本語フォントの初期化
try:
if os.path.exists(FONT_PATH):
font = ImageFont.truetype(FONT_PATH, FONT_SIZE)
font_small = ImageFont.truetype(FONT_PATH, FONT_SIZE_SMALL)
print(f"日本語フォントを読み込んだ: {FONT_PATH}")
else:
font = None
font_small = None
print("警告: 日本語フォントが見つからないため、OpenCVのデフォルトフォントを使用する。")
except Exception as e:
font = None
font_small = None
print(f"警告: フォント読み込みエラー: {e}")
def get_landmark_color(landmark_idx: int):
if 1 <= landmark_idx <= 17:
return LANDMARK_COLORS['jawline']
elif 18 <= landmark_idx <= 22:
return LANDMARK_COLORS['right_eyebrow']
elif 23 <= landmark_idx <= 27:
return LANDMARK_COLORS['left_eyebrow']
elif 28 <= landmark_idx <= 36:
return LANDMARK_COLORS['nose']
elif 37 <= landmark_idx <= 42:
return LANDMARK_COLORS['right_eye']
elif 43 <= landmark_idx <= 48:
return LANDMARK_COLORS['left_eye']
elif 49 <= landmark_idx <= 68:
return LANDMARK_COLORS['mouth']
else:
return LM_COLOR
def draw_japanese_text(frame, text, position, font_to_use, color_bgr):
# PillowはRGB前提のため、BGR→RGBに変換して色を渡す
if font_to_use is not None:
img_pil = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_pil)
color_rgb = (int(color_bgr[2]), int(color_bgr[1]), int(color_bgr[0]))
draw.text(position, text, font=font_to_use, fill=color_rgb)
return cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
else:
cv2.putText(frame, text, position, cv2.FONT_HERSHEY_SIMPLEX, 0.5, color_bgr, 1)
return frame
def video_frame_processing(frame):
global frame_count
current_time = time.time()
frame_count += 1
faces = app.get(frame)
# 実際に検出されたランドマーク数をカウント
actual_landmark_count = 0
z_values = [] # z座標値を収集
# 描画(2D: x, y)とz座標の収集(3D前提)
for face_idx, face in enumerate(faces):
# バウンディングボックス
if hasattr(face, 'bbox') and face.bbox is not None:
bbox = face.bbox.astype(int)
cv2.rectangle(frame, (bbox[0], bbox[1]), (bbox[2], bbox[3]), BBOX_COLOR, 2)
# 信頼度
confidence = face.det_score if hasattr(face, 'det_score') else 0.0
conf_text = f"信頼度: {confidence:.3f}"
if hasattr(face, 'bbox') and face.bbox is not None:
frame = draw_japanese_text(frame, conf_text, (int(face.bbox[0]), int(face.bbox[1]) - 25), font_small, BBOX_COLOR)
# 3D 68点ランドマークのみ処理
if hasattr(face, 'landmark_3d_68') and face.landmark_3d_68 is not None:
landmarks = face.landmark_3d_68
# 点数・次元の簡易検証
if len(landmarks) != 68:
continue
face_landmark_count = 0
for i, landmark in enumerate(landmarks):
if len(landmark) >= 3:
x, y, z = int(landmark[0]), int(landmark[1]), float(landmark[2])
z_values.append(z)
face_landmark_count += 1
else:
# 3D前提のため、次元が不足する点は描画しない
continue
color = get_landmark_color(i + 1)
cv2.circle(frame, (x, y), LM_RADIUS, color, -1)
# フレーム番号が30の倍数の時にランドマーク番号を表示
if frame_count % 30 == 0:
cv2.putText(frame, str(i + 1), (x + 3, y - 3),
cv2.FONT_HERSHEY_SIMPLEX, 0.3, color, 1)
actual_landmark_count += face_landmark_count
# 画面情報
info_text = f"フレーム: {frame_count} | 68点3Dランドマーク検出"
frame = draw_japanese_text(frame, info_text, (10, 30), font, FONT_COLOR_INFO)
face_count_text = f"検出された顔: {len(faces)}"
frame = draw_japanese_text(frame, face_count_text, (10, 60), font, FONT_COLOR_COUNT)
# 実際に検出されたランドマーク数を表示(理論値は常に68点)
landmark_text = f"検出ランドマーク数: {actual_landmark_count}/理論値{len(faces)*68}"
frame = draw_japanese_text(frame, landmark_text, (10, 90), font, FONT_COLOR_COUNT)
# z座標の統計情報を表示(データがある場合)
if z_values:
z_min = min(z_values)
z_max = max(z_values)
z_mean = sum(z_values) / len(z_values)
z_info_text = f"Z座標範囲: {z_min:.2f} ~ {z_max:.2f} (平均: {z_mean:.2f})"
frame = draw_japanese_text(frame, z_info_text, (10, 115), font_small, (200, 200, 200))
# 色分け凡例
legend_y = 145
legend_items = [
("顎ライン", LANDMARK_COLORS['jawline']),
("眉毛", LANDMARK_COLORS['right_eyebrow']),
("鼻", LANDMARK_COLORS['nose']),
("目", LANDMARK_COLORS['right_eye']),
("口", LANDMARK_COLORS['mouth'])
]
for i, (label, color) in enumerate(legend_items):
y_pos = legend_y + i * 25
cv2.circle(frame, (15, y_pos), 5, color, -1)
frame = draw_japanese_text(frame, label, (30, y_pos - 5), font_small, color)
# 注記
height = frame.shape[0]
frame = draw_japanese_text(frame, "注記: z座標はモデル内部の相対値(物理的距離ではない)", (10, height - 40), font_small, (200, 200, 200))
# 操作案内
frame = draw_japanese_text(frame, "'q'キーで終了", (10, height - 20), font_small, (255, 255, 255))
# z座標情報を結果に含める
z_info = f"Z範囲:{z_min:.2f}~{z_max:.2f}" if z_values else "Z:なし"
result = f"フレーム:{frame_count} 顔数:{len(faces)} ランドマーク:{actual_landmark_count} {z_info}"
return frame, result, current_time
# 入力選択メニュー
print("\n0: 動画ファイル")
print("1: カメラ")
print("2: サンプル動画")
choice = input("選択: ")
if choice == '0':
root = tk.Tk()
root.withdraw()
path = filedialog.askopenfilename()
if not path:
sys.exit(0)
cap = cv2.VideoCapture(path)
elif choice == '1':
cap = cv2.VideoCapture(0, cv2.CAP_DSHOW)
if not cap.isOpened():
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
else:
# サンプル動画ダウンロード・処理(失敗時は終了)
SAMPLE_URL = 'https://raw.githubusercontent.com/opencv/opencv/master/samples/data/vtest.avi'
SAMPLE_FILE = 'vtest.avi'
try:
urllib.request.urlretrieve(SAMPLE_URL, SAMPLE_FILE)
except Exception as e:
print(f"エラー: サンプル動画のダウンロードに失敗: {e}")
sys.exit(1)
cap = cv2.VideoCapture(SAMPLE_FILE)
if not cap.isOpened():
print('動画ファイル・カメラを開けなかった。')
sys.exit(1)
# メイン処理
print('\n=== 動画処理開始 ===')
print('操作方法:')
print(' q キー: プログラム終了')
try:
while True:
ret, frame = cap.read()
if not ret:
break
MAIN_FUNC_DESC = "InsightFace 68点3Dランドマーク検出"
processed_frame, result, current_time = video_frame_processing(frame)
cv2.imshow(MAIN_FUNC_DESC, processed_frame)
if choice == '1': # カメラの場合
print(datetime.fromtimestamp(current_time).strftime("%Y-%m-%d %H:%M:%S.%f")[:-3], result)
else: # 動画ファイルまたはサンプルの場合
print(frame_count, result)
results_log.append(result)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
finally:
print('\n=== プログラム終了 ===')
cap.release()
cv2.destroyAllWindows()
if results_log:
with open('result.txt', 'w', encoding='utf-8') as f:
f.write('=== 結果 ===\n')
f.write(f'処理フレーム数: {frame_count}\n')
f.write('\n')
f.write('\n'.join(results_log))
print('処理結果をresult.txtに保存した。')
4. 使用方法
- 上記のプログラムを実行する
- Webカメラの映像が表示され、検出された顔に赤色の境界ボックスと色分けされた68点ランドマークが表示される。
- ランドマークは以下のように色分けされる:
- 顎のライン(1-17点): 赤色
- 眉毛(18-27点): 緑色
- 鼻(28-36点): 黄色
- 目(37-48点): マゼンタ色
- 口(49-68点): シアン色
- 各顔の上部に検出信頼度(0.000~1.000)が表示される。検出信頼度は0.0から1.0の値で、1.0に近いほど顔である確信度が高い。0.5以上を閾値として使用することが多い。
- 画面左側に色分け凡例が表示される。
- 'q'キーを押すとプログラムが終了する。
5. 実験・探求のアイデア
AIモデル選択による比較実験
プログラム内のname='buffalo_sc'を以下のモデルに変更して、性能の違いを確認する。
buffalo_l: 最高精度、処理速度は低いbuffalo_m: 中規模、バランス型buffalo_s: 軽量で高速buffalo_sc: 小規模、高速処理
検出サイズの変更実験
DET_SIZE = (640, 640)の値を変更して、検出精度と処理速度への影響を確認する。
- (320, 320): 高速処理、小さい顔の検出が困難
- (1280, 1280): 高精度、処理速度が低下
様々な条件での検出性能テスト
- 複数人の同時検出
- 横顔や斜め顔での検出精度
- マスク着用時の検出性能
- 暗い環境での検出限界
- 手で顔の一部を隠した場合の挙動
- 表情変化によるランドマーク位置の変動解析
68点ランドマーク活用の探求
検出された68点ランドマークの座標を利用して、以下の解析を実行する:
- 頭部姿勢推定: 鼻尖と目の位置関係から頭部の向きを計算
- 表情認識: 口角と眉毛の位置変化から基本表情を判定
- 目の開閉検出: 目のランドマーク(37-48点)から目のアスペクト比(EAR)を計算
- 口の動き解析: 口のランドマーク(49-68点)から口のアスペクト比(MAR)を計算
- 顔の対称性解析: 左右のランドマーク位置から顔の対称性を評価
- 3D顔面形状復元: 68点の3次元座標から顔面メッシュを構築
ランドマーク精度評価実験
- 異なる照明条件下での検出精度比較
- 顔の角度変化に対するランドマーク安定性評価