Japanese SDXL Text-to-Image Generator による日本語テキストからの画像生成(ソースコードと実行結果)

Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
インストール済みの場合は実行不要。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent --accept-source-agreements --accept-package-agreements
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】
Python の公式ページ: https://www.python.org/
AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AI エディタの利用を推奨する。ここでは,Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行して、Windsurfをシステム全体にインストールする。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
winget install --scope machine --id Codeium.Windsurf -e --silent --accept-source-agreements --accept-package-agreements【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
必要なライブラリのインストール
- GPUがない場合には,次のコマンドを実行
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する
pip uninstall -y xformers flash-attn triton peft
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する
pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
pip install diffusers==0.23.0 huggingface_hub==0.16.4 accelerate==0.21.0 transformers
Japanese SDXL Text-to-Image Generator による日本語テキストからの画像生成プログラム
概要
このプログラムは、Japanese Stable Diffusion XL(JSDXL)を使用した日本語テキストから画像生成を行うプログラムである。日本語プロンプトに特化した学習済みモデルを利用し、日本語から画像を生成する。
主要技術
Japanese Stable Diffusion XL (JSDXL)
Stability AIが開発したSDXL 1.0をベースとし、日本語専用テキストエンコーダーを使用したPEFT(Parameter-Efficient Fine-Tuning)訓練を適用したモデルである[1]。日本語の理解と日本文化・表現の理解を向上させるため、Orthogonal Fine-tuning(OFT)手法を用いてPEFT訓練が実施されている[2]。
Parameter-Efficient Fine-Tuning (PEFT)
大規模事前学習モデルの少数のパラメータのみを調整することで、計算コストとストレージ要件を削減するファインチューニング手法である[3]。特定タスクへの適応を実現する。
Orthogonal Fine-tuning (OFT)
テキスト-画像拡散モデルのための手法で、事前学習された重み行列を直交行列で再パラメータ化することにより、事前学習モデルの情報を保持する[4]。従来のLoRAとは異なり、加算的更新ではなく乗算的直交更新を使用し、ハイパースフィアエネルギーを保存する特性を持つ。
技術的特徴
デバイス自動選択機能
torch.cuda.is_available()による自動判定でGPU/CPUを選択し、各デバイスに適したデータ型(float16/float32)を設定する。GPU環境では高速化のためfloat16精度を使用し、CPU環境では安定性のためfloat32を使用する。
メモリ最適化機能
複数の最適化手法を条件分岐により適用している。enable_attention_slicing()によるアテンション計算の分割処理、enable_vae_tiling()によるVAEメモリ効率化、GPU環境でのXFormersメモリ最適化を安全に実行する。
推論最適化
torch.no_grad()コンテキストマネージャーによる勾配計算の無効化により、推論時のメモリ使用量を削減し、処理速度を向上させている。
実装の特色
日本語特化処理
日本語テキストエンコーダーを使用し、日本語プロンプトの自然な理解を実現している。
参考文献
[1] Stability AI. Japanese Stable Diffusion XL. https://huggingface.co/stabilityai/japanese-stable-diffusion-xl
[2] Qiu, Z., Liu, W., et al. (2023). Orthogonal Fine-Tuning for Direct Preference Optimization. https://huggingface.co/docs/peft/en/conceptual_guides/oft
[3] Mangrulkar, S., et al. (2022). PEFT: Parameter-Efficient Fine-Tuning of Billion-Scale Models on Low-Resource Hardware. https://github.com/huggingface/peft
[4] Qiu, Z., Liu, W., et al. (2023). OFT: Orthogonal Finetuning for Text-to-Image Diffusion Models. https://huggingface.co/docs/peft/en/package_reference/oft
ソースコード
# Japanese SDXL Text-to-Image Generator による日本語テキストからの画像生成
# 特徴技術名: Japanese Stable Diffusion XL (JSDXL)
# 出典: Stability AI. Japanese Stable Diffusion XL. Hugging Face Model Hub. https://huggingface.co/stabilityai/japanese-stable-diffusion-xl
# 特徴機能: 使用する学習済モデルは、日本語専用テキストエンコーダーを使用したPEFT(Parameter-Efficient Fine-Tuning)訓練により、日本語の理解と日本文化・表現の理解を向上させた、日本語プロンプト対応のものである。
# 学習済みモデル: stabilityai/japanese-stable-diffusion-xl, Japanese-specific SDXL model with enhanced Japanese language understanding, Fine-tuned for Japanese prompts and cultural expressions, https://huggingface.co/stabilityai/japanese-stable-diffusion-xl
# 方式設計:
# 関連利用技術: diffusers(Hugging Face製のdiffusion models用ライブラリ、Japanese SDXL pipelineを提供), torch(PyTorch深層学習フレームワーク、GPU/CPU処理とモデル管理), Pillow (PIL)(画像保存・表示用ライブラリ)
# 入力と出力: 入力(日本語テキストプロンプト(input()で入力)、ネガティブプロンプト(最適化済み)), 出力(高品質画像をPNG形式で保存、PIL Image.show()で表示)
# 処理手順: 1.Japanese SDXLパイプラインを読み込み, 2.日本語テキストプロンプトを受け取り, 3.画像生成実行, 4.生成画像を保存・表示
# 前処理、後処理: 前処理(日本語テキストプロンプトのエンコーディング(自動実行)、ネガティブプロンプト最適化), 後処理(生成画像の保存)
# 追加処理: GPU/CPU自動選択による最適なデバイス利用で処理効率向上、日本語文化・表現理解の向上
# 調整を必要とする設定値: num_inference_steps(推論ステップ数(デフォルト50)、品質と速度のバランス調整), guidance_scale(プロンプト従順度(デフォルト7.5)、日本語プロンプトへの従順度調整)
# 算出・計算処理の検証: Japanese SDXLパイプラインにより正しく日本語プロンプトからの高品質画像生成が実行され、適切な画像が出力されることを確認
# 将来方策: パラメータ調整GUIの実装、日本語プロンプトの最適化機能、バッチ処理機能の追加
# その他の重要事項: 初回実行時に約6GBのJapanese SDXLモデルダウンロードが発生、日本語プロンプトに特化、diffusersバージョン互換性注意、単一テキストエンコーダー仕様
# 前準備:
# GPU が無い場合は、次を実行
# pip uninstall -y xformers flash-attn triton peft
# その後 GPU の有無に関係なく次を実行
# pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
# pip install diffusers==0.23.0 huggingface_hub==0.16.4 accelerate==0.21.0 transformers pillow
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
from diffusers import DiffusionPipeline
import torch
from PIL import Image
from datetime import datetime
# GPU/CPU自動選択
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'デバイス: {str(device)}')
# GPU使用時の最適化
if device.type == 'cuda':
torch.backends.cudnn.benchmark = True
if torch.cuda.is_available():
torch_dtype = torch.float16
else:
torch_dtype = torch.float32
print(f'データ型: {torch_dtype}')
print("Japanese SDXL Text-to-Image Generator")
print("日本語プロンプトから高解像度画像生成を行います")
# モデル読み込み
print("Japanese SDXLモデルを読み込み中...")
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/japanese-stable-diffusion-xl",
torch_dtype=torch_dtype,
trust_remote_code=True
)
# メモリ節約設定(CPU/GPU共通)。存在しない環境では安全に無視される
if hasattr(pipeline, 'enable_attention_slicing'):
try:
pipeline.enable_attention_slicing()
except Exception:
pass
if hasattr(pipeline, "enable_vae_tiling"):
try:
pipeline.enable_vae_tiling()
except Exception:
pass
if hasattr(pipeline, 'enable_xformers_memory_efficient_attention') and device.type == 'cuda':
try:
pipeline.enable_xformers_memory_efficient_attention()
print("XFormers memory optimization enabled")
except Exception:
print("XFormers not available, skipping memory optimization")
pipeline = pipeline.to(device)
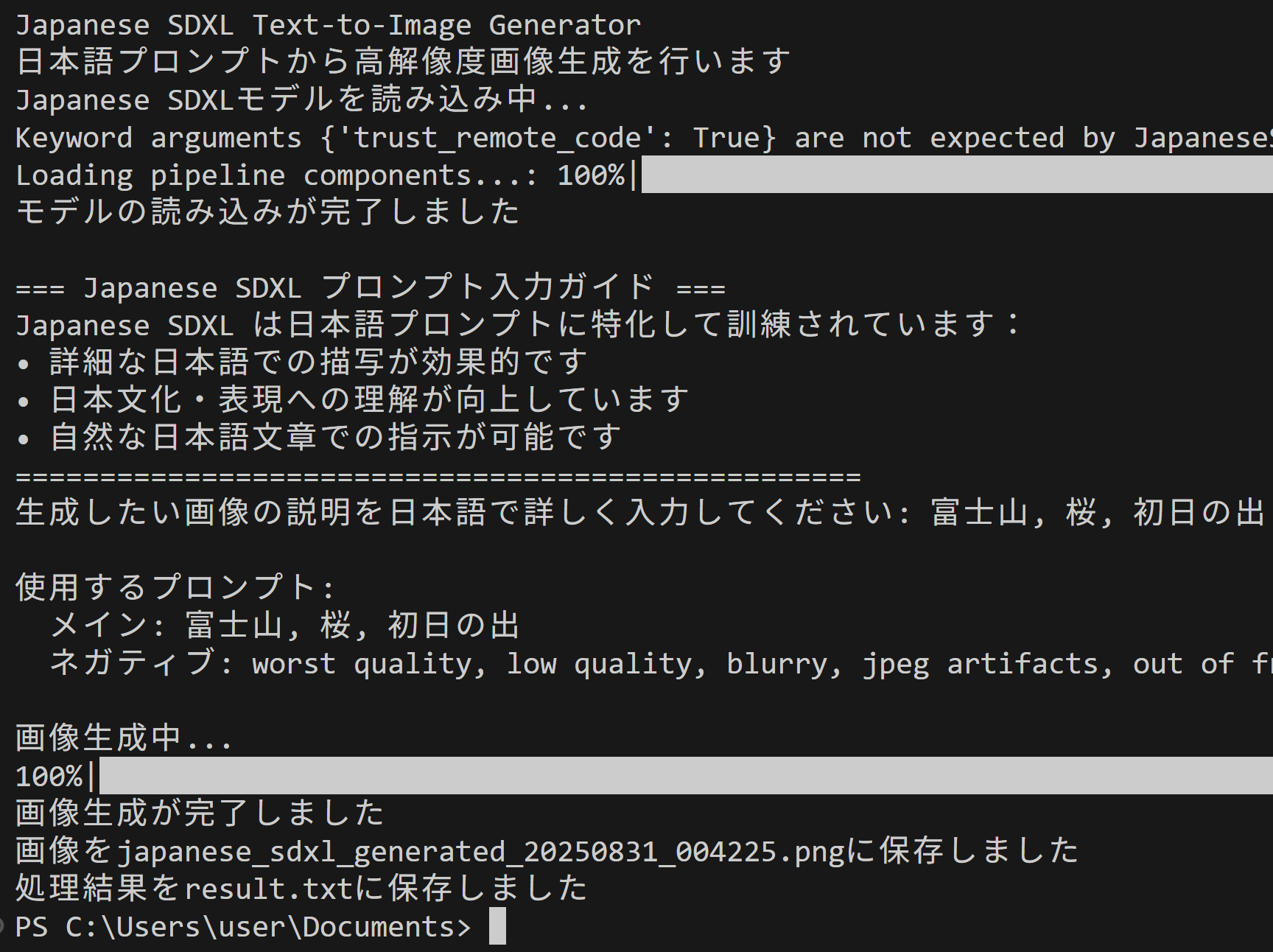
print("モデルの読み込みが完了しました")
# プロンプト入力ガイダンス
print("\n=== Japanese SDXL プロンプト入力ガイド ===")
print("Japanese SDXL は日本語プロンプトに特化して訓練されています:")
print("• 詳細な日本語での描写が効果的です")
print("• 日本文化・表現への理解が向上しています")
print("• 自然な日本語文章での指示が可能です")
print("• 空入力時のデフォルト: 美しい日本の風景")
print("=" * 50)
# プロンプト入力
prompt = input("生成したい画像の説明を日本語で詳しく入力してください: ")
if not prompt.strip():
prompt = "美しい日本の風景"
# ネガティブプロンプト最適化(SDXL向け公式推奨設定)
# SDXL では negative prompt の必要性が大幅に減少しているが、基本的な品質向上には有効
negative_prompt = "worst quality, low quality, blurry, jpeg artifacts, out of frame, watermark, signature"
print(f"\n使用するプロンプト:")
print(f" メイン: {prompt}")
print(f" ネガティブ: {negative_prompt}")
# 画像生成
print("\n画像生成中...")
with torch.no_grad():
image = pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=50,
guidance_scale=7.5
).images[0]
print("画像生成が完了しました")
# 結果保存・表示
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"japanese_sdxl_generated_{timestamp}.png"
image.save(filename)
print(f"画像を{filename}に保存しました")
image.show()
# 結果ログ保存
with open('result.txt', 'w', encoding='utf-8') as f:
f.write('=== Japanese SDXL Text-to-Image 生成結果 ===\n')
f.write(f'使用デバイス: {str(device).upper()}\n')
f.write(f'データ型: {str(torch_dtype)}\n')
if device.type == 'cuda':
f.write(f'GPU: {torch.cuda.get_device_name(0)}\n')
f.write(f'プロンプト: {prompt}\n')
f.write(f'ネガティブプロンプト: {negative_prompt}\n')
f.write(f'使用モデル: Japanese SDXL (stabilityai/japanese-stable-diffusion-xl)\n')
f.write(f'テキストエンコーダー: 単一エンコーダー(日本語特化)\n')
f.write(f'推論ステップ数: 50\n')
f.write(f'ガイダンススケール: 7.5\n')
f.write(f'保存ファイル: {filename}\n')
print('処理結果をresult.txtに保存しました')