InsightFace による顔の変化分析(ソースコードと実行結果)
Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
インストール済みの場合は実行不要。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent --accept-source-agreements --accept-package-agreements
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】
Python の公式ページ: https://www.python.org/
AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AI エディタの利用を推奨する。ここでは,Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行して、Windsurfをシステム全体にインストールする。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
winget install --scope machine --id Codeium.Windsurf -e --silent --accept-source-agreements --accept-package-agreements【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
必要なライブラリをシステム領域にインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する
pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
pip install insightface matplotlib numpy onnxruntime
pip install -U opencv-python
InsightFace による顔の変化分析プログラム
概要
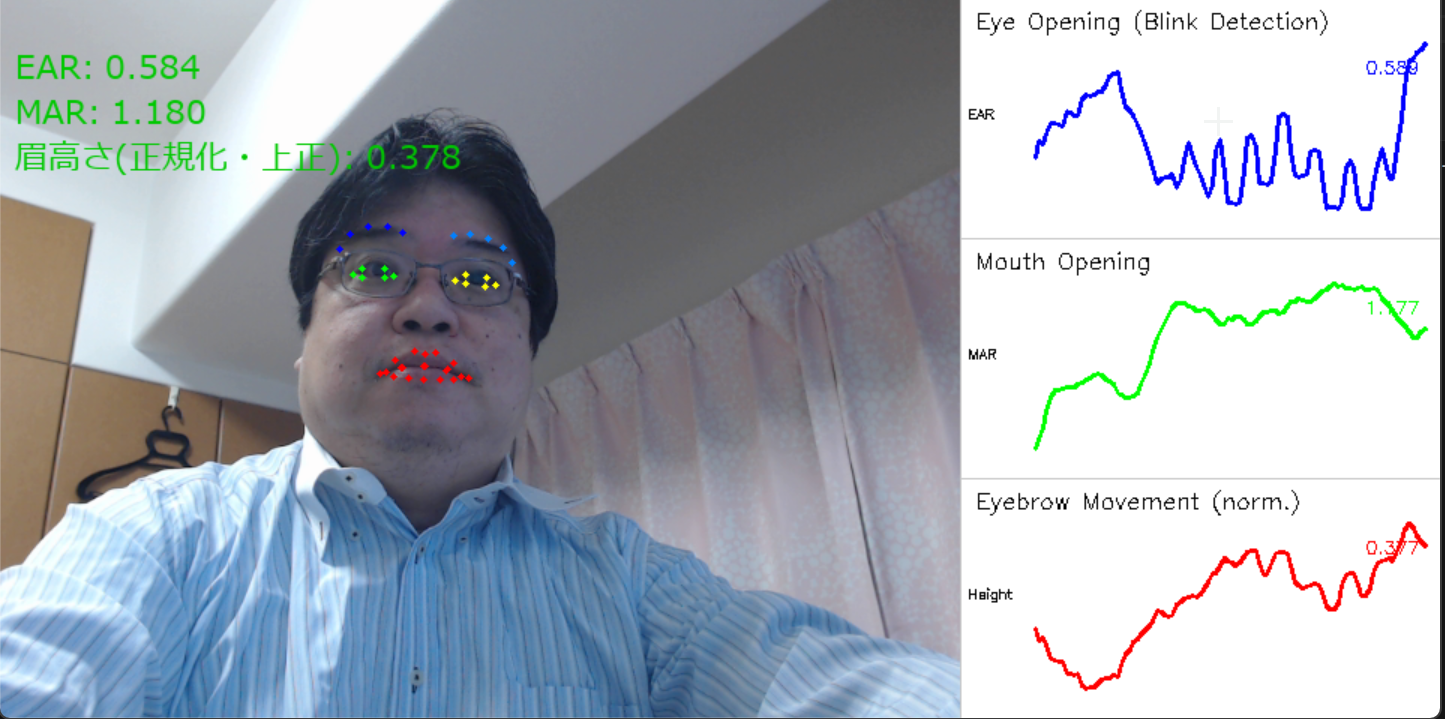
動画像から顔を検出し、106個の特徴点を抽出して目・口・眉の動きを数値化する。本プログラムは、リアルタイム顔表情分析能力を示している。具体的には、動画フレームから顔を検出し、106個の2D顔ランドマークを抽出して、瞬き(EAR: Eye Aspect Ratio)、口の開閉(MAR: Mouth Aspect Ratio)、眉の上下動を定量的に計測する。これらの微細な表情変化を時系列グラフとして可視化することで、人間の表情状態を客観的に分析できる。
主要技術
- InsightFace:深層学習ベースの顔分析フレームワークである。RetinaFaceによる顔検出と、2d106detモデルによる106点顔ランドマーク検出を統合している[1]。buffalo_lモデルは、大規模データセットで学習された汎用顔分析モデルである。
- 顔ランドマーク検出:顔の特徴的な位置(目、鼻、口、顔輪郭など)を2次元座標として検出する技術である。106個の特徴点により、表情変化を追跡できる[2]。
参考文献
[1] J. Guo, J. Deng, N. Xue, and S. Zafeiriou, "Stacked Dense U-Nets with Dual Transformers for Robust Face Alignment," arXiv preprint arXiv:1812.01936, 2018.
[2] Y. Wu, T. Hassner, K. Kim, G. Medioni, and P. Natarajan, "Facial Landmark Detection with Tweaked Convolutional Neural Networks," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 40, no. 12, pp. 3067-3074, 2018.
ソースコード
# 顔の微細変化分析プログラム
# 特徴技術名: InsightFace 2D Face Landmarks Detection
# 出典: J. Guo et al., "InsightFace: 2D and 3D Face Analysis Project," arXiv:1801.07698, 2018.
# https://github.com/deepinsight/insightface
# 特徴機能: 106個の2D顔ランドマーク検出によるリアルタイム顔特徴点追跡(目・鼻・口・顔輪郭の位置推定)
# ランドマークインデックス:
# * 左目: `[35, 36, 37, 39, 41, 42]`
# * 右目: `[89, 90, 91, 93, 95, 96]`
# * 左眉: `[43, 48, 49, 50, 51]`
# * 右眉: `[101, 102, 103, 104, 105]`
# * 口(外側輪郭): `[52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71]`
# 学習済みモデル: buffalo_l(大規模顔認識モデル、RetinaFace検出器と2d106det landmarkモデルを含む統合モデル、自動ダウンロード)
# 方式設計:
# - 関連利用技術: OpenCV(動画処理・表示・グラフ描画)、numpy(ベクトル計算)、onnxruntime(モデル推論エンジン)
# - 入力と出力: 入力: 動画(ユーザは「0:動画ファイル,1:カメラ,2:サンプル動画」のメニューで選択.0:動画ファイルの場合はtkinterでファイル選択.1の場合はOpenCVでカメラが開く.2の場合はhttps://raw.githubusercontent.com/opencv/opencv/master/samples/data/vtest.aviを使用)、出力: 処理結果が画像化できる場合にはOpenCV画面でリアルタイムに表示.OpenCV画面内に処理結果をテキストで表示.さらに,処理結果を表示.プログラム終了時に表示した処理結果をresult.txtファイルに保存し,「result.txtに保存」したことを表示.プログラム開始時に,プログラムの概要,ユーザが行う必要がある操作(もしあれば)を表示.
# - 処理手順: 動画フレーム取得→InsightFaceで顔検出→106個の2Dランドマーク抽出→EAR/MAR/眉高さ計算→移動平均→グラフ更新→統合表示
# - 前処理、後処理: 前処理: 変換なし(OpenCVのBGR画像をそのまま渡す)、後処理: 特徴量の移動平均によるノイズ除去
# - 追加処理: 瞬き検出のためのEAR(Eye Aspect Ratio)計算、口の開き具合のMAR(Mouth Aspect Ratio)計算、眉の相対高さ計算
# - 調整を必要とする設定値: WINDOW_SIZE(移動平均のウィンドウサイズ、デフォルト10)- ノイズ除去の強度を制御、GRAPH_LENGTH(グラフ表示のデータ点数、デフォルト100)- 表示する履歴の長さを制御
# 将来方策: 動的に顔の動きの速度を検出し、WINDOW_SIZEを自動調整する機能の実装
# その他の重要事項: 顔が検出されない場合はグラフ更新が停止、複数の顔が検出された場合は最初の顔のみを処理
# 前準備:
# - pip install insightface numpy onnxruntime
# - pip install -U opencv-python
# 注記: グラフ描画はOpenCVで行っている
import os
import logging
import warnings
import cv2
import tkinter as tk
from tkinter import filedialog
import urllib.request
import time
from collections import deque
import numpy as np
from PIL import Image, ImageDraw, ImageFont
from datetime import datetime
# ログレベルの抑制
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
logging.getLogger('tensorflow').setLevel(logging.ERROR)
warnings.filterwarnings('ignore')
import insightface
from insightface.app import FaceAnalysis
# 調整可能な設定値
WINDOW_SIZE = 10 # 移動平均のウィンドウサイズ - ノイズ除去の強度を制御
GRAPH_LENGTH = 100 # グラフに表示するデータ点数 - 表示する履歴の長さを制御
DETECTION_THRESHOLD = 0.3 # 顔検出閾値(低い値ほど検出しやすいが誤検出も増える)
# プログラム開始時の説明
print('=== 顔の微細変化分析プログラム ===')
print('このプログラムは、InsightFaceを使用して顔の106個のランドマークを検出し、')
print('目の開き具合(EAR)、口の開き具合(MAR)、眉の高さを分析します。')
print('')
print('操作方法:')
print('- 0: 動画ファイルを選択(ダイアログが開きます)')
print('- 1: カメラから入力')
print('- 2: サンプル動画を使用(ネットワーク接続が必要)')
print('- qキー: プログラムを終了')
print('- 分析結果はコンソールに表示されます')
print('- 終了時に結果がresult.txtに保存されます')
print('注意: 画面内の日本語テキスト表示にはMeiryoフォント(C:/Windows/Fonts/meiryo.ttc)を使用します。')
# InsightFace初期化
app = FaceAnalysis(name='buffalo_l')
app.prepare(ctx_id=-1, det_size=(640, 640), det_thresh=DETECTION_THRESHOLD)
# 特徴量計算用のランドマークインデックス(106個のランドマークに対応)
LEFT_EYE_INDICES = [35, 36, 37, 39, 41, 42] # 左目
RIGHT_EYE_INDICES = [89, 90, 91, 93, 95, 96] # 右目
LEFT_EYEBROW_INDICES = [43, 48, 49, 50, 51] # 左眉
RIGHT_EYEBROW_INDICES = [101, 102, 103, 104, 105] # 右眉
MOUTH_OUTER_INDICES = [52, 53, 54, 55, 56, 57, 58, 59,
60, 61, 62, 63, 64, 65, 66, 67,
68, 69, 70, 71] # 口(外側輪郭)
# 日本語描画用フォント設定
FONT_PATH = 'C:/Windows/Fonts/meiryo.ttc'
FONT_SIZE = 22
def calculate_ear(eye_landmarks):
"""Eye Aspect Ratio(目の開き具合)を計算"""
v1 = np.linalg.norm(eye_landmarks[1] - eye_landmarks[5])
v2 = np.linalg.norm(eye_landmarks[2] - eye_landmarks[4])
h = np.linalg.norm(eye_landmarks[0] - eye_landmarks[3])
ear = (v1 + v2) / (2.0 * h) if h > 0 else 0.0
return ear
def calculate_mar(mouth_landmarks):
"""Mouth Aspect Ratio(口の開き具合)を計算"""
if len(mouth_landmarks) >= 12:
v1 = np.linalg.norm(mouth_landmarks[2] - mouth_landmarks[18]) # 52-70
v2 = np.linalg.norm(mouth_landmarks[3] - mouth_landmarks[17]) # 53-69
v3 = np.linalg.norm(mouth_landmarks[4] - mouth_landmarks[16]) # 54-68
h = np.linalg.norm(mouth_landmarks[0] - mouth_landmarks[10]) # 52-62
mar = (v1 + v2 + v3) / (3.0 * h) if h > 0 else 0.0
else:
mar = 0.0
return mar
def calculate_eyebrow_height(eyebrow_landmarks, eye_center, inter_eye_dist):
"""眉の高さ(両眼中心間距離で正規化,上方向を正とする)"""
eyebrow_center = np.mean(eyebrow_landmarks, axis=0)
raw = eyebrow_center[1] - eye_center[1]
height = (-raw / inter_eye_dist) if inter_eye_dist > 0 else 0.0
return height
def extract_features(landmarks_2d):
"""2Dランドマークから特徴量を抽出"""
landmarks_array = landmarks_2d
left_eye = landmarks_array[LEFT_EYE_INDICES]
left_ear = calculate_ear(left_eye)
right_eye = landmarks_array[RIGHT_EYE_INDICES]
right_ear = calculate_ear(right_eye)
avg_ear = (left_ear + right_ear) / 2.0
mouth = landmarks_array[MOUTH_OUTER_INDICES]
mar = calculate_mar(mouth)
left_eye_center = np.mean(left_eye, axis=0)
right_eye_center = np.mean(right_eye, axis=0)
inter_eye_dist = float(np.linalg.norm(left_eye_center - right_eye_center))
left_eyebrow = landmarks_array[LEFT_EYEBROW_INDICES]
right_eyebrow = landmarks_array[RIGHT_EYEBROW_INDICES]
left_eyebrow_height = calculate_eyebrow_height(left_eyebrow, left_eye_center, inter_eye_dist)
right_eyebrow_height = calculate_eyebrow_height(right_eyebrow, right_eye_center, inter_eye_dist)
avg_eyebrow_height = (left_eyebrow_height + right_eyebrow_height) / 2.0
return {'ear': avg_ear, 'mar': mar, 'eyebrow': avg_eyebrow_height}
def draw_single_graph(img, data, x_offset, y_offset, width, height, color, title, ylabel):
"""単一のグラフをOpenCVで描画"""
cv2.rectangle(img, (x_offset, y_offset), (x_offset + width, y_offset + height), (200, 200, 200), 1)
cv2.putText(img, title, (x_offset + 10, y_offset + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 1)
cv2.putText(img, ylabel, (x_offset + 5, y_offset + height // 2), cv2.FONT_HERSHEY_SIMPLEX, 0.3, (0, 0, 0), 1)
if len(data) > 1:
data_min = min(data)
data_max = max(data)
data_range = data_max - data_min if data_max > data_min else 0.1
graph_x = x_offset + 50
graph_y = y_offset + 30
graph_w = width - 60
graph_h = height - 50
points = []
for i, value in enumerate(data):
x = graph_x + int(i * graph_w / (len(data) - 1))
normalized_value = (value - data_min) / data_range if data_range > 0 else 0.5
y = graph_y + graph_h - int(normalized_value * graph_h)
points.append((x, y))
for i in range(len(points) - 1):
cv2.line(img, points[i], points[i + 1], color, 2)
cv2.putText(img, f'{data[-1]:.3f}', (graph_x + graph_w - 40, graph_y + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.4, color, 1)
def draw_graphs(data_history, width, height):
"""OpenCVでグラフを描画"""
img = np.ones((height, width, 3), dtype=np.uint8) * 255
graph_height = height // 3
draw_single_graph(img, list(data_history['ear']), 0, 0, width, graph_height, (255, 0, 0), 'Eye Opening (Blink Detection)', 'EAR')
draw_single_graph(img, list(data_history['mar']), 0, graph_height, width, graph_height, (0, 255, 0), 'Mouth Opening', 'MAR')
draw_single_graph(img, list(data_history['eyebrow']), 0, graph_height * 2, width, graph_height, (0, 0, 255), 'Eyebrow Movement (norm.)', 'Height')
return img
# データ履歴の初期化
data_history = {
'ear': deque(maxlen=GRAPH_LENGTH),
'mar': deque(maxlen=GRAPH_LENGTH),
'eyebrow': deque(maxlen=GRAPH_LENGTH)
}
# 移動平均用のバッファ
moving_avg_buffer = {
'ear': deque(maxlen=WINDOW_SIZE),
'mar': deque(maxlen=WINDOW_SIZE),
'eyebrow': deque(maxlen=WINDOW_SIZE)
}
frame_count = 0
results_log = []
def video_frame_processing(frame):
global frame_count, data_history, moving_avg_buffer
current_time = time.time()
frame_count += 1
frame_height, frame_width = frame.shape[:2]
# 顔検出と特徴量抽出(BGR画像をそのまま渡す)
faces = app.get(frame)
features = None
if len(faces) > 0:
face = faces[0]
landmarks_2d = face.landmark_2d_106
features = extract_features(landmarks_2d)
# ランドマーク描画(目、眉、口のみ描画)
for idx in LEFT_EYE_INDICES:
x = int(landmarks_2d[idx][0]); y = int(landmarks_2d[idx][1])
cv2.circle(frame, (x, y), 2, (0, 255, 0), -1)
for idx in RIGHT_EYE_INDICES:
x = int(landmarks_2d[idx][0]); y = int(landmarks_2d[idx][1])
cv2.circle(frame, (x, y), 2, (0, 255, 255), -1)
for idx in LEFT_EYEBROW_INDICES:
x = int(landmarks_2d[idx][0]); y = int(landmarks_2d[idx][1])
cv2.circle(frame, (x, y), 2, (255, 0, 0), -1)
for idx in RIGHT_EYEBROW_INDICES:
x = int(landmarks_2d[idx][0]); y = int(landmarks_2d[idx][1])
cv2.circle(frame, (x, y), 2, (255, 128, 0), -1)
for idx in MOUTH_OUTER_INDICES:
x = int(landmarks_2d[idx][0]); y = int(landmarks_2d[idx][1])
cv2.circle(frame, (x, y), 2, (0, 0, 255), -1)
# 移動平均の計算
for key in ['ear', 'mar', 'eyebrow']:
moving_avg_buffer[key].append(features[key])
avg_value = float(np.mean(moving_avg_buffer[key]))
data_history[key].append(avg_value)
# グラフ描画
graph_width = frame_width // 2
graph_image = draw_graphs(data_history, graph_width, frame_height)
# 画像結合
processed_frame = np.hstack([frame, graph_image])
# テキスト表示(Pillowで描画)
if features:
font = ImageFont.truetype(FONT_PATH, FONT_SIZE)
img_pil = Image.fromarray(cv2.cvtColor(processed_frame, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_pil)
lines = [
f"EAR: {features['ear']:.3f}",
f"MAR: {features['mar']:.3f}",
f"眉高さ(正規化・上正): {features['eyebrow']:.3f}"
]
x, y = 10, 30
for line in lines:
draw.text((x, y), line, font=font, fill=(0, 200, 0))
y += 30
processed_frame = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
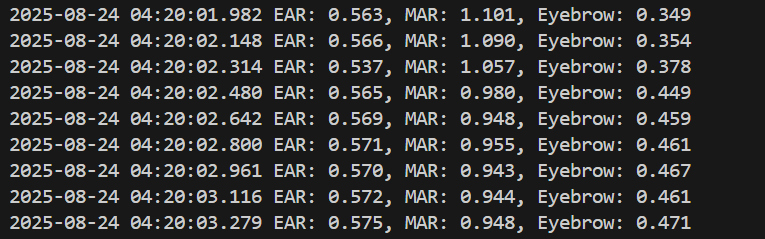
result = f"EAR: {features['ear']:.3f}, MAR: {features['mar']:.3f}, Eyebrow: {features['eyebrow']:.3f}"
else:
result = "No face detected"
return processed_frame, result, current_time
print("0: 動画ファイル")
print("1: カメラ")
print("2: サンプル動画")
choice = input("選択: ")
if choice == '0':
root = tk.Tk()
root.withdraw()
path = filedialog.askopenfilename()
if not path:
exit()
cap = cv2.VideoCapture(path)
elif choice == '1':
cap = cv2.VideoCapture(0, cv2.CAP_DSHOW)
if not cap.isOpened():
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
else:
SAMPLE_URL = 'https://raw.githubusercontent.com/opencv/opencv/master/samples/data/vtest.avi'
SAMPLE_FILE = 'vtest.avi'
urllib.request.urlretrieve(SAMPLE_URL, SAMPLE_FILE)
cap = cv2.VideoCapture(SAMPLE_FILE)
if not cap.isOpened():
print('動画ファイル・カメラを開けませんでした')
exit()
print('\n=== 動画処理開始 ===')
print('操作方法:')
print(' q キー: プログラム終了')
try:
while True:
ret, frame = cap.read()
if not ret:
break
MAIN_FUNC_DESC = "顔の微細変化分析"
processed_frame, result, current_time = video_frame_processing(frame)
cv2.imshow(MAIN_FUNC_DESC, processed_frame)
if choice == '1':
print(datetime.fromtimestamp(current_time).strftime("%Y-%m-%d %H:%M:%S.%f")[:-3], result)
else:
print(frame_count, result)
results_log.append(result)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
finally:
print('\n=== プログラム終了 ===')
cap.release()
cv2.destroyAllWindows()
if results_log:
with open('result.txt', 'w', encoding='utf-8') as f:
f.write('=== 結果 ===\n')
f.write(f'処理フレーム数: {frame_count}\n')
f.write('\n')
f.write('\n'.join(results_log))
print(f'\n処理結果をresult.txtに保存しました')