EmbeddingGemma による文書の意味的検索(ソースコードと実行結果)
プログラム利用ガイド
1. このプログラムの利用シーン
大量の文書から関連情報を検索するためのアプリケーションである。企業の文書検索、研究論文の調査、技術文書の参照、法務文書の分析など、情報検索が必要な場面で活用できる。多言語対応により、日本語と英語の混在する文書環境での利用も可能である。
2. 主な機能
- 多種形式ファイル対応: PDF、Word、PowerPoint、HTML、CSVファイルを統一的に処理し、検索対象データベースに追加する。
- 意味的検索: キーワード一致ではなく、文章の意味に基づいた検索を実行する。検索クエリと類似する意味の文書を発見できる。
- 埋め込みモデル選択: 日本語対応のEmbeddingGemmaや多言語E5モデルなど、用途に応じてモデルを切り替えることができる。
- 永続化データベース: 一度処理した文書は自動的に保存され、アプリケーション再起動後も利用可能である。
- 類似度スコア表示: 検索結果に類似度スコアと距離を表示し、関連性の度合いを数値で確認できる。
3. 基本的な使い方
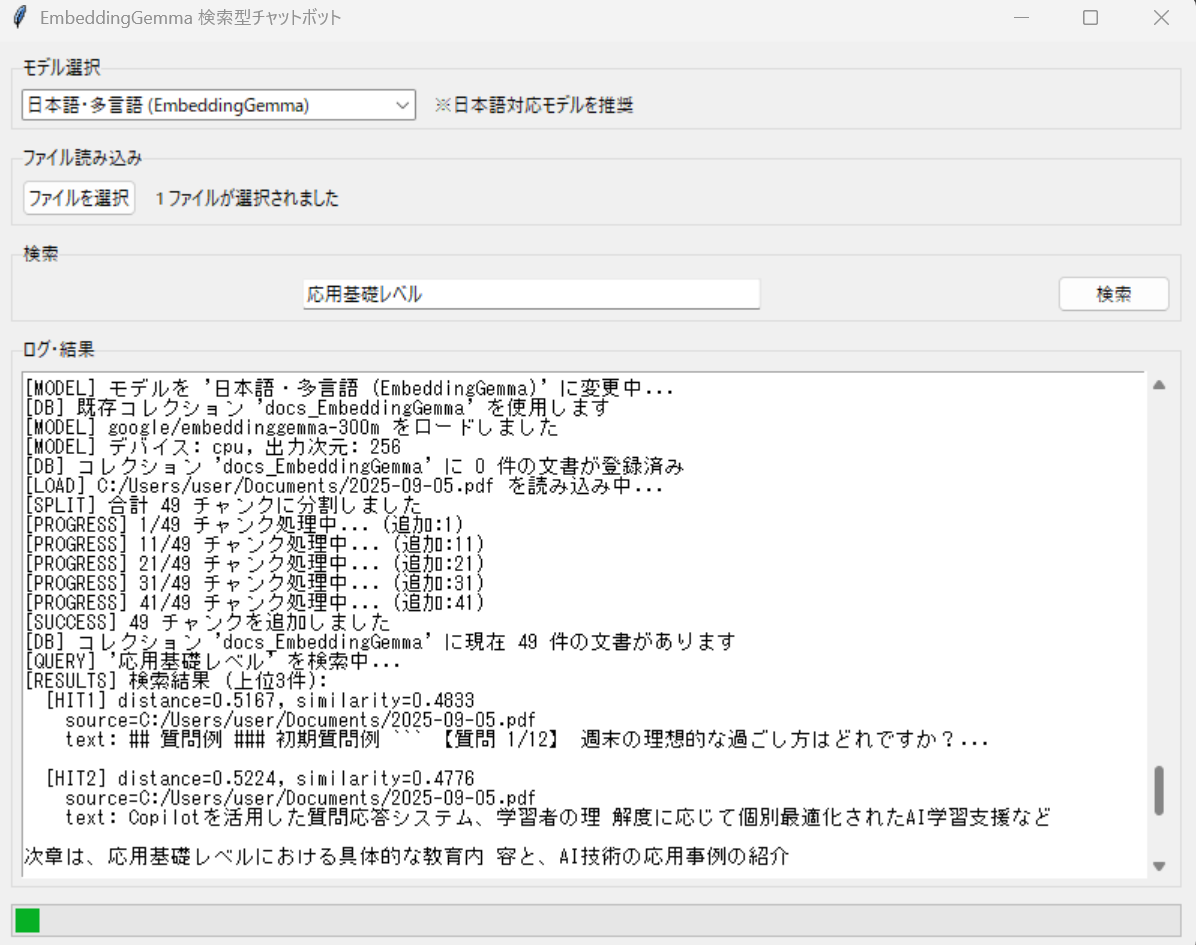
- アプリケーション起動: プログラムを実行すると、GUIウィンドウが表示される。初回起動時にモデルの自動ダウンロードが実行される。
- モデル選択: 上部のドロップダウンメニューから使用する埋め込みモデルを選択する。日本語文書の場合はEmbeddingGemmaを推奨する。
- 文書読み込み: 「ファイルを選択」ボタンをクリックし、検索対象とする文書ファイルを複数選択する。選択後、自動的に文書の分割と埋め込み生成が開始される。
- 検索実行: 検索ボックスに質問や検索したい内容を入力し、「検索」ボタンを押すまたはEnterキーを押す。
- 結果確認: 下部のログエリアに検索結果が表示される。各結果には類似度スコア、元ファイル名、関連する文章の一部が表示される。
4. 便利な機能
- プログレスバー表示: 文書処理や検索実行中の進捗状況をプログレスバーで確認できる。大量の文書処理時に有用である。
- 重複検出機能: 同一文書を複数回読み込んでも、重複を自動的に検出してスキップする。処理時間の短縮につながる。
- モデル別データ管理: 異なる埋め込みモデルのデータは独立して管理される。モデルを切り替えても既存データは保持される。
- エラーガイド表示: Hugging Face認証エラーが発生した場合、詳細なセットアップ手順が自動表示される。
Python 3.12 のインストール
インストール済みの場合は実行不要。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent --accept-source-agreements --accept-package-agreements
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】
Python の公式ページ: https://www.python.org/
AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AI エディタの利用を推奨する。ここでは,Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行して、Windsurfをシステム全体にインストールする。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
winget install --scope machine --id Codeium.Windsurf -e --silent --accept-source-agreements --accept-package-agreements【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
必要なライブラリをシステム領域にインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する
pip install
EmbeddingGemma による文書の意味的検索
概要
このプログラムは、EmbeddingGemma[1]の埋め込みモデルを活用した文書の意味的検索の実装である。PDF、Word、PowerPoint、HTML、CSVファイルなど多様な文書形式を読み込み、文書の意味的検索を可能にするGUIアプリケーションである。
主要技術
EmbeddingGemma
Googleが開発した308M パラメータの埋め込みモデルである[1]。Gemma 3アーキテクチャをベースとし、100以上の言語に対応した多言語モデルである。Matryoshka Representation Learning(MRL)により、768次元から128次元まで可変の出力次元を提供する[2]。
ChromaDB
オープンソースベクトルデータベースである[3]。高次元ベクトルデータの保存、インデックス化、クエリを可能にし、コサイン類似度による近似最近傍検索の機能を持つ。
Sentence Transformers
文章、テキスト、画像の埋め込みベクトル生成のためのライブラリである[4]。BERT などのTransformerモデルを基盤とし、意味的類似性検索や パラフレーズマイニングを可能にする。
LangChain
大規模言語モデルを活用したアプリケーション開発フレームワークである[5]。
技術的特徴
RecursiveCharacterTextSplitterによる適応的文書分割機能を実装している。これにより、文書の構造を保持しながら適切なサイズのチャンクに分割する。
モデル別コレクション管理により、異なる埋め込みモデルのデータを独立して管理する。これにより、複数のモデルを比較評価することが可能である。ChromaDBを用いた永続化ベクトルストレージにより、一度生成した埋め込みベクトルを再利用できる。
参考文献
[1] Google AI. (2025). EmbeddingGemma: A 308M parameter multilingual text embedding model. https://developers.googleblog.com/en/introducing-embeddinggemma/
[2] Google AI. (2025). EmbeddingGemma model card. https://ai.google.dev/gemma/docs/embeddinggemma/model_card
[3] Chroma Team. (2025). Chroma: Open-source search and retrieval database for AI applications. https://github.com/chroma-core/chroma
[4] Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv preprint arXiv:1908.10084. https://sbert.net/
[5] LangChain. (2024). LangChain documentation. https://python.langchain.com/
ソースコード
"""
このプログラムは EmbeddingGemma を用いた「検索型」チャットボットの最小構成です。
使い方は次のとおりです:
1. このコードを 1 つのファイル(例: bot.py)として保存してください。
2. 実行前に以下のコマンドで必要なパッケージをインストールしてください:
pip install chromadb langchain-community sentence-transformers>=5.0.0 pypdf unstructured[local-inference] python-docx python-pptx torch
pip install git+https://github.com/huggingface/transformers@v4.56.0-Embedding-Gemma-preview
3. プログラムを実行すると、
- モデルをロード(CPU または GPU を自動判別)
- Chroma 永続化DBを初期化または再利用
- sample.pdf, sample.html, sample.docx, sample.pptx があれば読み込み・分割・埋め込み保存
- 検索クエリ「東京の観光スポットを教えて」を実行し、検索結果を表示
という一連の処理が対話的に進みます。
4. 実際に利用する際は、ご自身の PDF/HTML/Word/PPT ファイルを
プログラムと同じディレクトリに置いてください。
5. 初回実行で埋め込んだデータは ./chroma_db に保存され、次回以降は再利用されます。
"""
import tkinter as tk
from tkinter import filedialog, messagebox, scrolledtext, ttk
import os
import threading
import webbrowser
import uuid
import hashlib
import re
from sentence_transformers import SentenceTransformer
from langchain_community.document_loaders import (
UnstructuredPDFLoader, UnstructuredHTMLLoader,
UnstructuredWordDocumentLoader, UnstructuredPowerPointLoader,
TextLoader, CSVLoader
)
from langchain.text_splitter import RecursiveCharacterTextSplitter
import chromadb
import torch
class EmbeddingGemmaSearchBot:
def __init__(self):
# 利用可能なモデル定義(日本語対応優先)
self.available_models = {
"日本語・多言語 (EmbeddingGemma)": "google/embeddinggemma-300m",
"日本語・多言語 (E5-large)": "intfloat/multilingual-e5-large",
"日本語・多言語 (E5-base)": "intfloat/multilingual-e5-base",
"英語 (all-MiniLM-L6-v2)": "sentence-transformers/all-MiniLM-L6-v2",
"英語 (all-mpnet-base-v2)": "sentence-transformers/all-mpnet-base-v2"
}
# デフォルトモデル(日本語対応)
self.current_model_name = "日本語・多言語 (EmbeddingGemma)"
self.current_model_id = self.available_models[self.current_model_name]
self.setup_ui()
self.setup_model()
def show_huggingface_guide(self, error_message):
"""Hugging Faceトークン・モデル許可取得ガイド表示"""
guide_window = tk.Toplevel(self.root)
guide_window.title("Hugging Face セットアップガイド")
guide_window.geometry("600x500")
guide_window.resizable(False, False)
# メインフレーム
main_frame = ttk.Frame(guide_window, padding="20")
main_frame.pack(fill=tk.BOTH, expand=True)
# タイトル
title_label = ttk.Label(main_frame, text="EmbeddingGemma使用のためのセットアップ",
font=("Arial", 14, "bold"))
title_label.pack(pady=(0, 20))
# エラー情報
error_frame = ttk.LabelFrame(main_frame, text="エラー情報", padding="10")
error_frame.pack(fill=tk.X, pady=(0, 20))
error_text = tk.Text(error_frame, height=3, wrap=tk.WORD, bg="#ffeeee")
error_text.pack(fill=tk.X)
error_text.insert("1.0", error_message)
error_text.config(state=tk.DISABLED)
# ガイド内容
guide_frame = ttk.LabelFrame(main_frame, text="セットアップ手順", padding="10")
guide_frame.pack(fill=tk.BOTH, expand=True)
guide_text = scrolledtext.ScrolledText(guide_frame, height=15, wrap=tk.WORD)
guide_text.pack(fill=tk.BOTH, expand=True)
guide_content = """【必要な手順】
1. Hugging Face アカウント作成(無料)
• https://huggingface.co/ にアクセス
• 「Sign Up」をクリックしてアカウントを作成
2. EmbeddingGemmaモデルのライセンス同意
• https://huggingface.co/google/embeddinggemma-300m にアクセス
• 「Acknowledge license」ボタンをクリック
• Gemmaの利用規約に同意
3. Hugging Face アクセストークン生成
• https://huggingface.co/settings/tokens にアクセス
• 「New token」をクリック
• 名前を入力(例:「embedding_app」)
• Type: Read を選択
• 「Generate a token」をクリック
• 生成されたトークンをコピー(安全に保管)
4. トークンの設定方法
方法A: 環境変数設定(推奨)
Windows:
set HUGGINGFACE_HUB_TOKEN=your_token_here
Mac/Linux:
export HUGGINGFACE_HUB_TOKEN=your_token_here
方法B: huggingface-hubライブラリでログイン
ターミナル/コマンドプロンプトで実行:
pip install huggingface-hub
python -c "from huggingface_hub import login; login()"
5. 必要なTransformersバージョンのインストール
pip install git+https://github.com/huggingface/transformers@v4.56.0-Embedding-Gemma-preview
【重要な注意事項】
• トークンは他人と共有しないでください
• モデルの商用利用にはGemma利用規約を確認してください
• 初回モデルダウンロード時は時間がかかる場合があります
設定完了後、アプリケーションを再起動してください。
"""
guide_text.insert("1.0", guide_content)
guide_text.config(state=tk.DISABLED)
# ボタンフレーム
button_frame = ttk.Frame(main_frame)
button_frame.pack(fill=tk.X, pady=(20, 0))
# リンクボタン
def open_hf_signup():
webbrowser.open("https://huggingface.co/")
def open_model_page():
webbrowser.open("https://huggingface.co/google/embeddinggemma-300m")
def open_tokens_page():
webbrowser.open("https://huggingface.co/settings/tokens")
ttk.Button(button_frame, text="Hugging Face サインアップ",
command=open_hf_signup).pack(side=tk.LEFT, padx=(0, 10))
ttk.Button(button_frame, text="EmbeddingGemma ページ",
command=open_model_page).pack(side=tk.LEFT, padx=(0, 10))
ttk.Button(button_frame, text="トークン設定ページ",
command=open_tokens_page).pack(side=tk.LEFT, padx=(0, 10))
ttk.Button(button_frame, text="閉じる",
command=guide_window.destroy).pack(side=tk.RIGHT)
def change_model(self):
"""モデル変更"""
selected_name = self.model_var.get()
if selected_name == self.current_model_name:
return # 同じモデルの場合は何もしない
if messagebox.askyesno("モデル変更",
f"モデルを'{selected_name}'に変更しますか?\n"
f"データベースは再作成されます。"):
self.current_model_name = selected_name
self.current_model_id = self.available_models[selected_name]
# モデル再ロード
threading.Thread(target=self.reload_model, daemon=True).start()
def reload_model(self):
"""モデル再ロード"""
self.start_progress()
try:
self.log_message(f"[MODEL] モデルを '{self.current_model_name}' に変更中...")
self.setup_model()
except Exception as e:
self.log_message(f"[ERROR] モデル変更エラー: {str(e)}")
messagebox.showerror("エラー", f"モデルの変更に失敗しました: {str(e)}")
finally:
self.stop_progress()
def is_embeddinggemma_model(self, model_id):
"""EmbeddingGemmaモデルかどうかを判定"""
return "embeddinggemma" in model_id.lower()
def normalize_collection_name(self, name):
"""ChromaDBコレクション名の正規化"""
# 英数字とハイフン、アンダースコア、ドットのみを保持
normalized = re.sub(r'[^a-zA-Z0-9\-_.]', '_', name)
# 先頭と末尾を小文字の英数字にする
normalized = normalized.strip('._-').lower()
# 連続するドットを削除
normalized = re.sub(r'\.{2,}', '.', normalized)
# 長さを制限(3-63文字)
if len(normalized) < 3:
normalized = f"collection_{normalized}"
if len(normalized) > 63:
normalized = normalized[:63]
# 先頭と末尾が英数字でない場合の修正
if not normalized[0].isalnum():
normalized = 'c' + normalized[1:]
if not normalized[-1].isalnum():
normalized = normalized[:-1] + 'x'
return normalized
def check_sentence_transformers_version(self):
"""sentence-transformersのバージョンをチェック"""
try:
import sentence_transformers
version_str = sentence_transformers.__version__
major_version = int(version_str.split('.')[0])
return major_version >= 5
except:
return False
def encode_query_compat(self, model, query):
"""互換性を考慮したクエリエンコード"""
try:
# v5.0以降の場合、encode_queryメソッドを使用
if hasattr(model, 'encode_query'):
return model.encode_query(query)
# v5.0未満またはメソッドが存在しない場合
elif self.is_embeddinggemma_model(self.current_model_id):
# EmbeddingGemmaの場合はencode_queryがなければencodeを使用
if hasattr(model, 'encode'):
# プロンプトを追加してencodeを使用
# EmbeddingGemmaは正規化が不要(モデル側で処理される)
return model.encode(query, prompt_name="query" if hasattr(model, 'prompts') else None)
elif "multilingual-e5" in self.current_model_id.lower():
# E5系モデルの場合
return model.encode("query: " + query, normalize_embeddings=True)
else:
# その他のモデル
return model.encode(query, normalize_embeddings=True)
except Exception as e:
# フォールバック: 通常のencodeメソッドを使用
return model.encode(query, normalize_embeddings=True)
def encode_document_compat(self, model, text):
"""互換性を考慮したドキュメントエンコード"""
try:
# v5.0以降の場合、encode_documentメソッドを使用
if hasattr(model, 'encode_document'):
return model.encode_document(text)
# v5.0未満またはメソッドが存在しない場合
elif self.is_embeddinggemma_model(self.current_model_id):
# EmbeddingGemmaの場合
if hasattr(model, 'encode'):
# EmbeddingGemmaは正規化が不要(モデル側で処理される)
return model.encode(text, prompt_name="document" if hasattr(model, 'prompts') else None)
elif "multilingual-e5" in self.current_model_id.lower():
# E5系モデルの場合
return model.encode("passage: " + text, normalize_embeddings=True)
else:
# その他のモデル
return model.encode(text, normalize_embeddings=True)
except Exception as e:
# フォールバック: 通常のencodeメソッドを使用
return model.encode(text, normalize_embeddings=True)
def setup_model(self):
"""モデルとDBの初期化"""
try:
# デバイス設定
self.device = "cuda" if torch.cuda.is_available() else "cpu"
# モデルロード
model_params = {
"device": self.device,
}
# EmbeddingGemmaの場合のみtruncate_dim設定
if self.is_embeddinggemma_model(self.current_model_id):
model_params["truncate_dim"] = 256
model_params["similarity_fn_name"] = "cosine"
# E5系モデルの場合のプロンプト設定
if "multilingual-e5" in self.current_model_id.lower():
# E5系モデル用のプロンプト設定
model_params["prompts"] = {
"query": "query: ",
"passage": "passage: "
}
self.model = SentenceTransformer(self.current_model_id, **model_params)
# 永続化DB初期化 - モデル別にコレクション作成
DB_PATH = "./chroma_db"
self.client = chromadb.PersistentClient(path=DB_PATH)
# モデル名をベースにしたコレクション名(正規化)
model_short_name = self.current_model_name.split('(')[1].split(')')[0] if '(' in self.current_model_name else self.current_model_name
collection_name = self.normalize_collection_name(f"docs_{model_short_name}")
# 既存のコレクションがあれば取得、なければ作成
try:
self.collection = self.client.get_collection(collection_name)
self.log_message(f"[DB] 既存コレクション '{collection_name}' を使用します")
except Exception:
try:
self.collection = self.client.create_collection(
name=collection_name,
metadata={"hnsw:space": "cosine"}
)
self.log_message(f"[DB] コレクション '{collection_name}' をコサイン距離で作成しました")
except Exception as e:
# get_or_create_collectionにフォールバック
self.collection = self.client.get_or_create_collection(
name=collection_name,
metadata={"hnsw:space": "cosine"}
)
self.log_message(f"[DB] コレクション '{collection_name}' を取得/作成しました")
self.log_message(f"[MODEL] {self.current_model_id} をロードしました")
self.log_message(f"[MODEL] デバイス: {self.device}, 出力次元: {self.model.get_sentence_embedding_dimension()}")
self.log_message(f"[DB] コレクション '{self.collection.name}' に {self.collection.count()} 件の文書が登録済み")
# sentence-transformersバージョン確認
if self.is_embeddinggemma_model(self.current_model_id):
v5_available = self.check_sentence_transformers_version()
if not v5_available:
self.log_message("[WARNING] sentence-transformers v5.0未満を使用中。一部機能が制限される可能性があります")
self.log_message("[INFO] 最新機能を使用するには: pip install sentence-transformers>=5.0.0")
except Exception as e:
error_msg = str(e)
self.log_message(f"[ERROR] モデル初期化エラー: {error_msg}")
# Hugging Face関連エラーの場合、ガイドを表示
if any(keyword in error_msg.lower() for keyword in
['token', 'authentication', 'access', 'login', 'unauthorized', 'forbidden',
'repository not found', 'gated model', 'agreement']):
self.show_huggingface_guide(error_msg)
else:
messagebox.showerror("エラー", f"モデルの初期化に失敗しました: {error_msg}")
def setup_ui(self):
"""GUI初期化"""
self.root = tk.Tk()
self.root.title("EmbeddingGemma 検索型チャットボット")
self.root.geometry("800x600")
# メインフレーム
main_frame = ttk.Frame(self.root, padding="10")
main_frame.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
# モデル選択セクション
model_frame = ttk.LabelFrame(main_frame, text="モデル選択", padding="5")
model_frame.grid(row=0, column=0, sticky=(tk.W, tk.E), pady=(0, 10))
self.model_var = tk.StringVar(value=self.current_model_name)
model_combo = ttk.Combobox(model_frame, textvariable=self.model_var,
values=list(self.available_models.keys()),
state="readonly", width=40)
model_combo.grid(row=0, column=0, padx=(0, 10))
model_combo.bind('<<ComboboxSelected>>', lambda e: self.change_model())
ttk.Label(model_frame, text="※日本語対応モデルを推奨").grid(row=0, column=1, sticky=tk.W)
# ファイル読み込みセクション
file_frame = ttk.LabelFrame(main_frame, text="ファイル読み込み", padding="5")
file_frame.grid(row=1, column=0, sticky=(tk.W, tk.E), pady=(0, 10))
ttk.Button(file_frame, text="ファイルを選択", command=self.select_files).grid(row=0, column=0, padx=(0, 10))
self.file_label = ttk.Label(file_frame, text="ファイルが選択されていません")
self.file_label.grid(row=0, column=1, sticky=tk.W)
# 検索セクション
search_frame = ttk.LabelFrame(main_frame, text="検索", padding="5")
search_frame.grid(row=2, column=0, sticky=(tk.W, tk.E), pady=(0, 10))
self.query_entry = ttk.Entry(search_frame, width=50)
self.query_entry.grid(row=0, column=0, padx=(0, 10))
self.query_entry.bind('<Return>', lambda event: self.search_documents())
ttk.Button(search_frame, text="検索", command=self.search_documents).grid(row=0, column=1)
# 結果表示エリア
result_frame = ttk.LabelFrame(main_frame, text="ログ・結果", padding="5")
result_frame.grid(row=3, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
self.result_text = scrolledtext.ScrolledText(result_frame, height=15, width=80)
self.result_text.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
# プログレスバー
self.progress = ttk.Progressbar(main_frame, mode='indeterminate')
self.progress.grid(row=4, column=0, sticky=(tk.W, tk.E), pady=(10, 0))
# グリッド設定
self.root.columnconfigure(0, weight=1)
self.root.rowconfigure(0, weight=1)
main_frame.columnconfigure(0, weight=1)
main_frame.rowconfigure(3, weight=1)
model_frame.columnconfigure(1, weight=1)
file_frame.columnconfigure(1, weight=1)
search_frame.columnconfigure(0, weight=1)
result_frame.columnconfigure(0, weight=1)
result_frame.rowconfigure(0, weight=1)
def generate_unique_id(self, text, source):
"""文書の一意なID生成"""
# テキストとソースファイルパスを組み合わせてハッシュ化
content = f"{source}_{text[:100]}" # ソース + テキスト先頭100文字
hash_object = hashlib.md5(content.encode('utf-8'))
return f"doc_{hash_object.hexdigest()}"
def select_files(self):
"""ファイル選択とロード"""
filetypes = [
("All supported", "*.pdf;*.html;*.htm;*.docx;*.pptx;*.txt;*.csv"),
("PDF files", "*.pdf"),
("HTML files", "*.html;*.htm"),
("Word files", "*.docx"),
("PowerPoint files", "*.pptx"),
("Text files", "*.txt"),
("CSV files", "*.csv"),
("All files", "*.*")
]
files = filedialog.askopenfilenames(
title="ファイルを選択してください(複数選択可)",
filetypes=filetypes
)
if files:
self.file_label.config(text=f"{len(files)} ファイルが選択されました")
# ファイル読み込みを別スレッドで実行
threading.Thread(target=self.load_files, args=(files,), daemon=True).start()
def load_files(self, files):
"""ファイルの読み込みと埋め込み処理"""
self.start_progress()
try:
# ファイル形式別ローダーマッピング
loader_map = {
'.pdf': UnstructuredPDFLoader,
'.html': UnstructuredHTMLLoader,
'.htm': UnstructuredHTMLLoader,
'.docx': UnstructuredWordDocumentLoader,
'.pptx': UnstructuredPowerPointLoader,
'.txt': TextLoader,
'.csv': CSVLoader
}
docs = []
for file_path in files:
ext = os.path.splitext(file_path)[1].lower()
if ext in loader_map:
self.log_message(f"[LOAD] {file_path} を読み込み中...")
try:
loader_class = loader_map[ext]
if ext == '.txt':
loader = loader_class(file_path, encoding='utf-8')
else:
loader = loader_class(file_path)
docs.extend(loader.load())
except Exception as e:
self.log_message(f"[ERROR] {file_path} の読み込みエラー: {str(e)}")
else:
self.log_message(f"[WARNING] 非対応ファイル形式: {file_path}")
if docs:
# 文書分割
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
splits = splitter.split_documents(docs)
self.log_message(f"[SPLIT] 合計 {len(splits)} チャンクに分割しました")
# 埋め込み生成・保存
added_count = 0
for i, d in enumerate(splits):
text = str(d.page_content).strip()
if not text:
continue
# 一意なID生成
source = d.metadata.get("source", "unknown")
doc_id = self.generate_unique_id(text, source)
# 既存チェック
try:
existing = self.collection.get(ids=[doc_id])
if existing['ids']:
continue # 既存の場合はスキップ
except:
pass
# 互換性を考慮したエンコード
try:
emb = self.encode_document_compat(self.model, text)
# numpy配列の場合はリストに変換
if hasattr(emb, 'tolist'):
emb = emb.tolist()
elif hasattr(emb, 'numpy'):
emb = emb.numpy().tolist()
except Exception as e:
self.log_message(f"[ERROR] 埋め込み生成エラー: {str(e)}")
continue
self.collection.add(
documents=[text],
metadatas=[{"source": source}],
ids=[doc_id],
embeddings=[emb],
)
added_count += 1
if i % 10 == 0: # 進捗表示
self.log_message(f"[PROGRESS] {i+1}/{len(splits)} チャンク処理中... (追加:{added_count})")
self.log_message(f"[SUCCESS] {added_count} チャンクを追加しました")
self.log_message(f"[DB] コレクション '{self.collection.name}' に現在 {self.collection.count()} 件の文書があります")
else:
self.log_message("[WARNING] 読み込み可能な文書がありませんでした")
except Exception as e:
self.log_message(f"[ERROR] ファイル処理エラー: {str(e)}")
finally:
self.stop_progress()
def search_documents(self):
"""文書検索"""
query = self.query_entry.get().strip()
if not query:
messagebox.showwarning("警告", "検索クエリを入力してください")
return
self.start_progress()
threading.Thread(target=self._search_documents, args=(query,), daemon=True).start()
def _search_documents(self, query):
"""実際の検索処理"""
try:
self.log_message(f"[QUERY] '{query}' を検索中...")
# 互換性を考慮したクエリエンコード
try:
q_emb = self.encode_query_compat(self.model, query)
# numpy配列の場合はリストに変換
if hasattr(q_emb, 'tolist'):
q_emb = q_emb.tolist()
elif hasattr(q_emb, 'numpy'):
q_emb = q_emb.numpy().tolist()
except Exception as e:
self.log_message(f"[ERROR] クエリ埋め込み生成エラー: {str(e)}")
return
res = self.collection.query(query_embeddings=[q_emb], n_results=3)
docs = res["documents"][0]
metas = res["metadatas"][0]
distances = res["distances"][0]
# コサイン距離の場合、距離が小さいほど類似度が高い
scores = [1 - d for d in distances]
self.log_message(f"[RESULTS] 検索結果 (上位3件):")
for i, (doc, meta, score, distance) in enumerate(zip(docs, metas, scores, distances)):
self.log_message(f" [HIT{i+1}] distance={distance:.4f}, similarity={score:.4f}")
self.log_message(f" source={meta.get('source','')}")
self.log_message(f" text: {doc[:100]}...")
self.log_message("")
except Exception as e:
self.log_message(f"[ERROR] 検索エラー: {str(e)}")
finally:
self.stop_progress()
def log_message(self, message):
"""ログメッセージ表示"""
def update_text():
self.result_text.insert(tk.END, message + "\n")
self.result_text.see(tk.END)
self.root.after(0, update_text)
def start_progress(self):
"""プログレスバー開始"""
self.root.after(0, lambda: self.progress.start())
def stop_progress(self):
"""プログレスバー停止"""
self.root.after(0, lambda: self.progress.stop())
def run(self):
"""アプリケーション実行"""
self.root.mainloop()
if __name__ == "__main__":
try:
app = EmbeddingGemmaSearchBot()
app.run()
except Exception as e:
print(f"アプリケーション起動エラー: {str(e)}")
try:
messagebox.showerror("エラー", f"アプリケーションの起動に失敗しました: {str(e)}")
except:
pass # tkinterが利用できない場合