MediaPipe Face Landmarker(新API)によるリアルタイムEAR(Eye Aspect Ratio)算出(ソースコードと説明と利用ガイド)
【概要】MediaPipe新APIでリアルタイムEAR算出を行う。目の開閉状態を数値化するEAR(Eye Aspect Ratio)をリアルタイムで計算し、瞬き検出を実現する。
特徴:
- 顔478点検出→目12点からEAR算出
- 時系列グラフで可視化
- 60fps動作(スレッド化フレーム取得)
- 動画/カメラ対応
用途: 眠気検出、集中度測定
【目次】
- プログラム利用ガイド
- Python開発環境、ライブラリ類
- MediaPipe Face Landmarker(新API)によるリアルタイムEAR(Eye Aspect Ratio)算出プログラム
- 実験・研究スキルの基礎:Windowsで学ぶ瞬き検出実験
プログラム利用ガイド
1. このプログラムの利用シーン
このプログラムは、動画ファイルやカメラ映像から目の開閉状態を定量的に測定し、瞬きを検出するソフトウェアである。眠気検出、集中度測定、視線分析の前処理として利用できる。
2. 主な機能
- リアルタイムEAR計算: 右目と左目のEAR値を独立して計算し、画面に表示する。
- 瞬き判定: EAR値が閾値(デフォルト0.2)を下回ると「瞬き」と判定する。
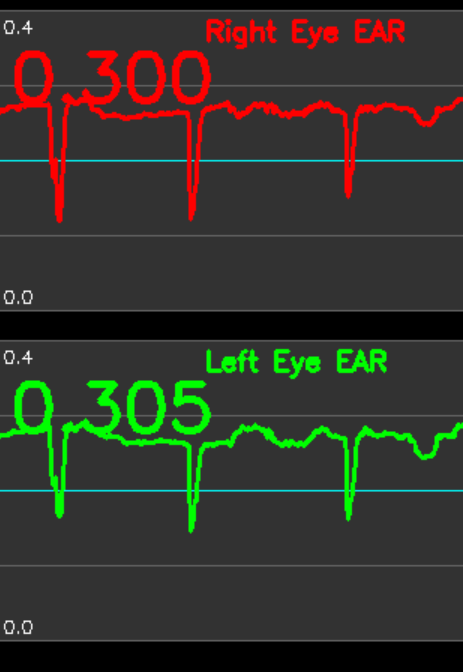
- 時系列グラフ表示: 過去1000フレーム分のEAR推移をグラフで可視化する。閾値ラインも表示される。
- ランドマーク可視化: 目の周囲12点(右目6点、左目6点)を映像上にプロットする。
- 処理結果の保存: 全フレームのEAR値をresult.txtファイルに保存する。
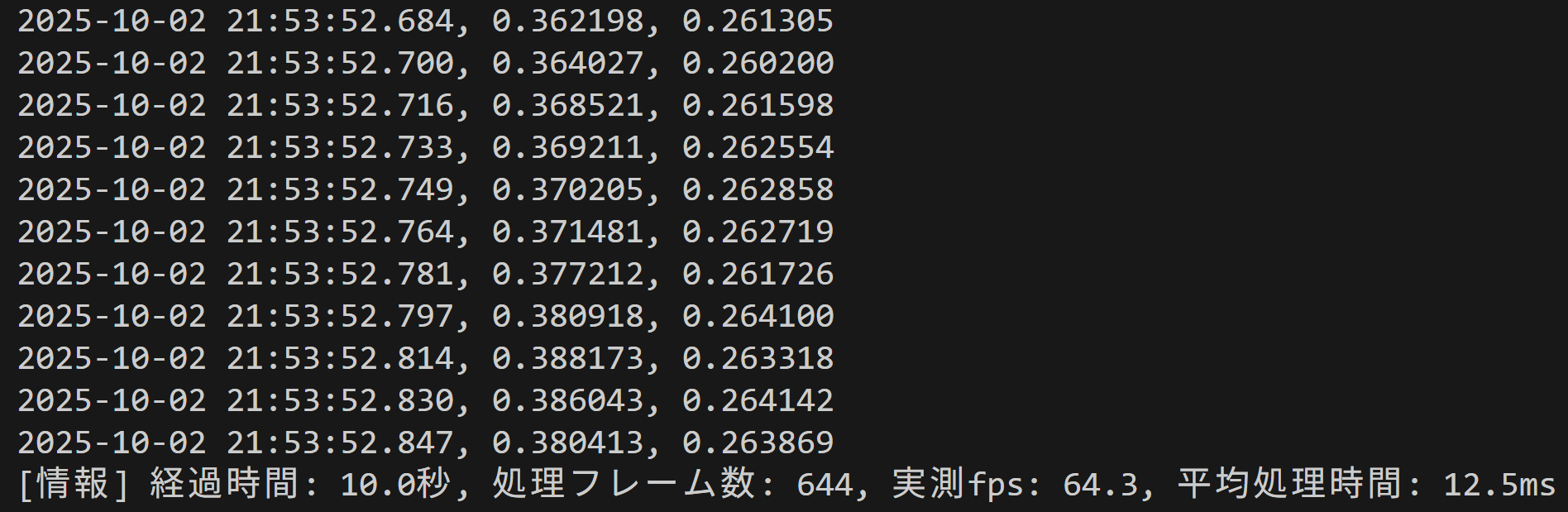
- パフォーマンス監視: カメラモードでは10秒ごとに実測fps、処理フレーム数、平均処理時間を表示する。
3. 基本的な使い方
- 起動と入力の選択:
キーボードで0(動画ファイル)、1(カメラ)、2(サンプル動画)のいずれかを入力し、Enterキーを押す。
- 処理の実行:
映像が表示され、リアルタイムでEAR値と瞬き判定が更新される。右側に時系列グラフが表示される。
- 終了方法:
映像が表示されている画面を選択した状態で、キーボードのqキーを押す。
4. 便利な機能
- 複数の入力ソース: 動画ファイル、カメラ、サンプル動画から選択できる。
- 自動モデルダウンロード: 初回実行時に学習済みモデルを自動的にダウンロードする。
- 詳細なコンソール出力: カメラモードではタイムスタンプ付き、動画モードではフレーム番号付きでEAR値を出力する。
- 結果ファイルの自動保存: プログラム終了時に全フレームの処理結果をresult.txtに保存する。
Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
インストール済みの場合は実行不要。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent --accept-source-agreements --accept-package-agreements
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】
Python の公式ページ: https://www.python.org/
AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AI エディタの利用を推奨する。ここでは,Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行して、Windsurfをシステム全体にインストールする。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
winget install --scope machine --id Codeium.Windsurf -e --silent --accept-source-agreements --accept-package-agreements【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
Visual Studio 2022 Build Toolsとランタイムのインストール
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Visual Studio 2022 Build Toolsとランタイムのインストール
winget install --scope machine --wait --accept-source-agreements --accept-package-agreements Microsoft.VisualStudio.2022.BuildTools Microsoft.VCRedist.2015+.x64
REM インストーラーとインストールパスの設定
set VS_INSTALLER="C:\Program Files (x86)\Microsoft Visual Studio\Installer\vs_installer.exe"
set VS_PATH="C:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools"
REM C++開発ワークロードのインストール(次のコマンドは全体で1行である)
%VS_INSTALLER% modify --installPath %VS_PATH% --add Microsoft.VisualStudio.Workload.VCTools --add Microsoft.VisualStudio.Component.VC.Tools.x86.x64 --add Microsoft.VisualStudio.Component.Windows11SDK.22621 --includeRecommended --quiet --norestart
必要なライブラリをシステム領域にインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する
pip install mediapipe opencv-python numpy
MediaPipe Face Landmarker(新API)によるリアルタイムEAR(Eye Aspect Ratio)算出プログラム
概要
このプログラムは、MediaPipe Face Landmarker[1][3]を用いて動画またはカメラ映像から顔のランドマーク478点を検出し、目の周囲12点の座標からEAR(Eye Aspect Ratio)を計算する。EAR値は目の開閉状態を数値化する指標であり[2]、リアルタイムで計算・表示することで瞬き検出を実現する。
主要技術
MediaPipe Face Landmarker
Google LLCが開発した顔ランドマーク検出技術である[1][3]。機械学習モデルにより顔の478点の特徴点を検出する。本プログラムでは新API(mediapipe.tasks.python.vision)を使用し、RunningMode.VIDEOモードで動画処理を行う。float16精度の軽量モデル(face_landmarker.task)により、リアルタイム処理を実現している。
EAR(Eye Aspect Ratio)
SoukupováとČechが2016年に提案した、目の開閉状態を数値化する計算手法である[2]。目の周囲6点の座標から、垂直方向の距離と水平方向の距離の比率を計算する。計算式はEAR = (||p2-p6|| + ||p3-p5||) / (2 × ||p1-p4||)である。EAR値が閾値を下回ると瞬きと判定される。
技術的特徴
- 連続フレーム間のトラッキング安定性
RunningMode.VIDEOモードを使用することで、前フレームの検出結果を次フレームの処理に活用する。これにより、顔の位置や向きが急激に変化する場合でも安定した検出を維持する。
- 軽量モデルによるリアルタイム処理
float16精度のモデル(約10MB)を使用することで、GPUおよびCPUの両方で30fps以上の処理速度を実現する。
- 左右独立したEAR計算
右目(インデックス362, 385, 387, 263, 373, 380)と左目(インデックス33, 160, 158, 133, 153, 144)のランドマークを別々に処理する。これにより、片目のみの瞬きや左右の目の開閉状態の違いを検出できる。
- 時系列グラフによる可視化
過去1000フレーム分のEAR値をdequeで管理し、右目と左目のグラフを別々に表示する。瞬き判定の閾値ラインも同時に表示することで、瞬きパターンの分析を支援する。
実装の特色
- 非同期フレーム取得
ThreadedVideoCaptureクラスにより、バックグラウンドスレッドで常に最新フレームを取得する。カメラ入力時の処理遅延によるフレーム蓄積を防止し、リアルタイム性を向上させる。
- タイムスタンプ管理機構
MediaPipe APIはRunningMode.VIDEOモードで単調増加するタイムスタンプ(ミリ秒)を要求する。本プログラムは動画のfpsから適切なタイムスタンプ増分を計算し、各フレームに付与する。
- 拡張キャンバスによる統合表示
入力映像の右側にグラフ領域を追加した拡張キャンバスを生成する。映像、ランドマークプロット、EAR値、瞬き判定、時系列グラフを1つの画面に統合表示する。
参考文献
[1] Lugaresi, C., Tang, J., Nash, H., McClanahan, C., Uboweja, E., Hays, M., Zhang, F., Chang, C. L., Yong, M. G., Lee, J., Chang, W. T., Hua, W., Georg, M., & Grundmann, M. (2019). MediaPipe: A Framework for Building Perception Pipelines. arXiv preprint arXiv:1906.08172. https://arxiv.org/abs/1906.08172
[2] Soukupová, T., & Čech, J. (2016). Real-Time Eye Blink Detection using Facial Landmarks. In Proceedings of the 21st Computer Vision Winter Workshop (pp. 1-8). Rimske Toplice, Slovenia.
[3] Google LLC. (2024). MediaPipe Face Landmarker. https://developers.google.com/mediapipe/solutions/vision/face_landmarker
ソースコード
# MediaPipe Face Landmarker(新API)によるリアルタイムEAR(Eye Aspect Ratio)算出プログラム
#
# - プログラム名: MediaPipe Face Landmarker EAR計算システム
#
# - 特徴技術名: MediaPipe Face Landmarker(新API)
#
# - 出典:
# Lugaresi, C., Tang, J., Nash, H., McClanahan, C., Uboweja, E., Hays, M., ... & Grundmann, M. (2019).
# MediaPipe: A Framework for Building Perception Pipelines.
# arXiv preprint arXiv:1906.08172.
# URL: https://developers.google.com/mediapipe
#
# EAR計算手法:
# Soukupová, T., & Čech, J. (2016).
# Real-Time Eye Blink Detection using Facial Landmarks.
# 21st Computer Vision Winter Workshop, Rimske Toplice, Slovenia.
#
# - 特徴機能: リアルタイム顔ランドマーク検出(478点)
# MediaPipe Face Landmarkerは、顔の詳細な特徴点478点を高速かつ高精度に検出する技術である。
# GPU/CPUの両方で30fps以上の処理速度を実現し、顔の回転や部分的な遮蔽に対して高いロバスト性を持つ。
# ビデオストリーム用の最適化された推論モード(RunningMode.VIDEO)により、連続フレーム間での
# トラッキングの安定性が向上している。本プログラムでは、目の周囲の特徴点(左目6点、右目6点)を
# 利用してEAR(Eye Aspect Ratio)を算出し、瞬き検出を実現する。
#
# - 学習済みモデル:
# 名称: face_landmarker.task(float16版)
# 概要: MediaPipe公式が提供する顔ランドマーク検出用の軽量モデル
# 特徴: float16精度により約10MBのファイルサイズを実現し、リアルタイム処理に最適化されている
# URL: https://storage.googleapis.com/mediapipe-models/face_landmarker/face_landmarker/float16/1/face_landmarker.task
#
# - 特徴技術および学習済モデルの利用制限:
# Apache License 2.0(MediaPipe)。学術研究および商用利用が可能。
# 詳細: https://github.com/google/mediapipe/blob/master/LICENSE
#
# - 方式設計:
# - 関連利用技術:
# 1. OpenCV(opencv-python): 動画入力、画像処理、画面表示を担当
# 2. NumPy: ランドマーク座標の数値計算、EAR計算に使用
# 3. tkinter: 動画ファイル選択用のGUIダイアログ
# 4. threading: カメラ入力の非同期処理による最新フレーム取得
# 5. urllib: 学習済みモデルとサンプル動画のダウンロード
#
# - 入力と出力:
# 入力: 動画(ユーザは「0:動画ファイル,1:カメラ,2:サンプル動画」のメニューで選択.
# 0:動画ファイルの場合はtkinterでファイル選択.1の場合はOpenCVでカメラが開く.
# 2の場合はhttps://raw.githubusercontent.com/opencv/opencv/master/samples/data/vtest.aviを使用)
# 出力: OpenCV画面にリアルタイムで処理結果を表示(右目・左目のEAR値、瞬き判定、
# 目の特徴点12点のプロット、EAR推移グラフ(右目・左目別々に表示)).
# print()で各フレームのEAR値を出力(カメラモードではタイムスタンプ付き、
# 動画モードではフレーム番号付き).プログラム終了時にresult.txtファイルに
# 全フレームの処理結果を保存し、「result.txtに保存」したことをprint()で表示.
# プログラム開始時に、プログラムの概要と操作方法(qキーで終了)をprint()で表示
#
# - 処理手順:
# 1. MediaPipe Face Landmarkerで顔の478点のランドマークを検出
# 2. 目の周囲の特徴点を抽出(左目: インデックス33,160,158,133,153,144、
# 右目: インデックス362,385,387,263,373,380)
# 3. 各目について6点の座標からEARを計算: EAR = (||p2-p6|| + ||p3-p5||) / (2 × ||p1-p4||)
# 4. EAR値を閾値(デフォルト0.2)と比較して瞬き判定
# 5. 処理結果を画面表示、コンソール出力、ファイル保存
#
# - 前処理、後処理:
# 前処理: 入力フレームをRGB形式に変換してMediaPipe Image形式に変換(MediaPipe APIの要件)
# 後処理: 検出されたランドマーク座標を画像サイズに合わせて正規化座標から
# ピクセル座標に変換(x座標 × 画像幅、y座標 × 画像高さ)
#
# - 追加処理:
# 1. スレッド化されたビデオキャプチャ(ThreadedVideoCapture): カメラモードで
# 常に最新フレームを取得することで、処理遅延によるフレーム蓄積を防止し、
# リアルタイム性を向上
# 2. EAR履歴管理(deque): 過去1000フレーム分のEAR値を保持し、時系列グラフとして
# 可視化することで、瞬きパターンの分析を容易にする
# 3. タイムスタンプ管理: ビデオモードでの正確なフレーム間隔計算により、
# MediaPipe APIの要求する厳密なタイムスタンプを提供
#
# - 調整を必要とする設定値:
# 1. EAR_THRESH(デフォルト: 0.2): 瞬き判定の閾値。この値より小さいEAR値を
# 「瞬き」と判定する。個人差(目の形状、まぶたの開き具合)により最適値が
# 異なるため、ユーザごとの調整が必要。値を小さくすると瞬き検出の感度が下がり、
# 大きくすると誤検出が増加する
# 2. CONF_THRESH(デフォルト: 0.5): 顔検出の信頼度閾値。照明条件や顔の向きにより
# 検出精度が変動する場合に調整
#
# - 将来方策:
# EAR_THRESHの個人別最適化機能: プログラム開始時に5秒間のキャリブレーション期間を設け、
# ユーザに通常の開眼状態を維持してもらい、その間のEAR平均値を測定する。
# 測定した平均値の70%を個人別閾値として自動設定することで、目の形状の個人差に対応した
# 高精度な瞬き検出が可能になる
#
# - その他の重要事項:
# 1. MediaPipe Face Landmarkerは新API(mediapipe.tasks.python.vision)を使用しており、
# 旧API(mediapipe.solutions.face_mesh)とは互換性がない
# 2. RunningMode.VIDEOモードでは、各フレームに単調増加するタイムスタンプ(ミリ秒)の
# 指定が必須である
# 3. カメラモードでは、実測fpsと平均処理時間を10秒ごとに表示し、パフォーマンス監視を支援
# 4. グラフ表示により、瞬きの頻度やパターンの視覚的分析が可能
#
# - 前準備: pip install mediapipe opencv-python numpy
import cv2
import tkinter as tk
from tkinter import filedialog
import os
import numpy as np
import urllib.request
import time
from datetime import datetime
from collections import deque
import threading
# MediaPipe新API
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
# ===== 設定 =====
# ウィンドウ名
WINDOW_NAME = 'EAR Detection'
# モデル情報
MODEL_URL = 'https://storage.googleapis.com/mediapipe-models/face_landmarker/face_landmarker/float16/1/face_landmarker.task'
MODEL_PATH = 'face_landmarker.task'
# MediaPipe設定
CONF_THRESH = 0.5
# 目のランドマークインデックス(EAR計算用)
LEFT_EYE_INDICES = [33, 160, 158, 133, 153, 144]
RIGHT_EYE_INDICES = [362, 385, 387, 263, 373, 380]
# 色定数
RIGHT_EYE_COLOR = (0, 0, 255) # 赤
LEFT_EYE_COLOR = (0, 255, 0) # 緑
# EAR閾値(瞬き判定用)
EAR_THRESH = 0.2
# グラフ設定
GRAPH_WIDTH = 400
GRAPH_HEIGHT = 200
GRAPH_MARGIN = 20
EAR_HISTORY_SIZE = 1000
# EAR履歴管理
right_ear_history = deque(maxlen=EAR_HISTORY_SIZE)
left_ear_history = deque(maxlen=EAR_HISTORY_SIZE)
class ThreadedVideoCapture:
"""スレッド化されたVideoCapture(常に最新フレームを取得)"""
def __init__(self, src, is_camera=False):
if is_camera:
self.cap = cv2.VideoCapture(src, cv2.CAP_DSHOW)
fourcc = cv2.VideoWriter_fourcc('M', 'J', 'P', 'G')
self.cap.set(cv2.CAP_PROP_FOURCC, fourcc)
self.cap.set(cv2.CAP_PROP_FPS, 60)
else:
self.cap = cv2.VideoCapture(src)
self.grabbed, self.frame = self.cap.read()
self.stopped = False
self.lock = threading.Lock()
self.thread = threading.Thread(target=self.update, args=())
self.thread.daemon = True
self.thread.start()
def update(self):
"""バックグラウンドでフレームを取得し続ける"""
while not self.stopped:
grabbed, frame = self.cap.read()
with self.lock:
self.grabbed = grabbed
if grabbed:
self.frame = frame
def read(self):
"""最新フレームを返す"""
with self.lock:
return self.grabbed, self.frame.copy() if self.grabbed else None
def isOpened(self):
return self.cap.isOpened()
def get(self, prop):
return self.cap.get(prop)
def release(self):
self.stopped = True
self.thread.join()
self.cap.release()
print('=== MediaPipe EAR算出プログラム(新API版) ===')
print('機能: 目の開き具合(EAR)をリアルタイムで計算・表示')
print()
# モデルダウンロード
if not os.path.exists(MODEL_PATH):
print('モデルをダウンロード中...')
try:
urllib.request.urlretrieve(MODEL_URL, MODEL_PATH)
print('ダウンロード完了')
except Exception as e:
print(f'ダウンロード失敗: {e}')
raise SystemExit(1)
# MediaPipe Face Landmarker初期化(新API)
base_options = python.BaseOptions(model_asset_path=MODEL_PATH)
options = vision.FaceLandmarkerOptions(
base_options=base_options,
running_mode=vision.RunningMode.VIDEO,
num_faces=1,
min_face_detection_confidence=CONF_THRESH,
min_face_presence_confidence=CONF_THRESH,
min_tracking_confidence=CONF_THRESH,
output_face_blendshapes=False,
output_facial_transformation_matrixes=False
)
face_landmarker = vision.FaceLandmarker.create_from_options(options)
print(f'MediaPipe Face Landmarker初期化完了(新API, ランドマーク数: 478点)')
print()
def calculate_ear(eye_landmarks):
"""Eye Aspect Ratio (EAR)を計算
EAR = (||p2-p6|| + ||p3-p5||) / (2 * ||p1-p4||)
eye_landmarks: 目の6点 [p1, p2, p3, p4, p5, p6]
"""
v1 = np.linalg.norm(eye_landmarks[1] - eye_landmarks[5])
v2 = np.linalg.norm(eye_landmarks[2] - eye_landmarks[4])
h = np.linalg.norm(eye_landmarks[0] - eye_landmarks[3])
ear = (v1 + v2) / (2.0 * h) if h > 0 else 0
return ear
def is_blink(ear):
"""EAR値から瞬き判定を行う"""
return "瞬き" if ear < EAR_THRESH else "開眼"
def draw_single_ear_graph(frame, history, graph_x, graph_y, color, label):
"""単一のEARグラフを描画"""
# グラフ背景
cv2.rectangle(frame, (graph_x, graph_y),
(graph_x + GRAPH_WIDTH, graph_y + GRAPH_HEIGHT),
(50, 50, 50), -1)
# グリッド線(横線)
for i in range(5):
y = graph_y + int(i * GRAPH_HEIGHT / 4)
cv2.line(frame, (graph_x, y), (graph_x + GRAPH_WIDTH, y), (100, 100, 100), 1)
# Y軸ラベル
y_min, y_max = 0.0, 0.4
cv2.putText(frame, f'{y_max:.1f}', (graph_x + 5, graph_y + 15),
cv2.FONT_HERSHEY_SIMPLEX, 0.4, (255, 255, 255), 1)
cv2.putText(frame, f'{y_min:.1f}', (graph_x + 5, graph_y + GRAPH_HEIGHT - 5),
cv2.FONT_HERSHEY_SIMPLEX, 0.4, (255, 255, 255), 1)
# グラフタイトル
cv2.putText(frame, label, (graph_x + GRAPH_WIDTH // 2 - 60, graph_y + 20),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, color, 2)
# 現在のEAR値を大きく表示
if len(history) > 0:
current_ear = history[-1]
cv2.putText(frame, f'{current_ear:.3f}', (graph_x + 10, graph_y + 60),
cv2.FONT_HERSHEY_SIMPLEX, 1.5, color, 3)
# 閾値ライン
thresh_y = graph_y + GRAPH_HEIGHT - int((EAR_THRESH - y_min) / (y_max - y_min) * GRAPH_HEIGHT)
cv2.line(frame, (graph_x, thresh_y), (graph_x + GRAPH_WIDTH, thresh_y), (255, 255, 0), 1)
# データプロット
if len(history) < 2:
return
points = []
for i, value in enumerate(history):
x = graph_x + int(i * GRAPH_WIDTH / EAR_HISTORY_SIZE)
y = graph_y + GRAPH_HEIGHT - int((value - y_min) / (y_max - y_min) * GRAPH_HEIGHT)
y = max(graph_y, min(graph_y + GRAPH_HEIGHT, y))
points.append((x, y))
for i in range(1, len(points)):
cv2.line(frame, points[i-1], points[i], color, 2)
def process_video_frame(frame, timestamp_ms, is_camera):
"""動画フレーム処理"""
# グラフ領域を含む拡張キャンバス作成
graph_area_height = GRAPH_HEIGHT * 2 + GRAPH_MARGIN * 3
extended_height = max(frame.shape[0], graph_area_height)
extended_width = frame.shape[1] + GRAPH_WIDTH + GRAPH_MARGIN * 2
extended_frame = np.zeros((extended_height, extended_width, 3), dtype=np.uint8)
extended_frame[:frame.shape[0], :frame.shape[1]] = frame
# MediaPipe Image形式に変換
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
# 新API: detect_for_video を使用
detection_result = face_landmarker.detect_for_video(mp_image, timestamp_ms)
result = ""
if detection_result.face_landmarks:
height, width = frame.shape[:2]
for face_idx, face_landmarks in enumerate(detection_result.face_landmarks):
# ランドマーク数の検証(最大インデックス387を確認)
if len(face_landmarks) < 388:
continue
# ランドマーク配列作成
landmarks_array = np.array([
(lm.x * width, lm.y * height)
for lm in face_landmarks
])
# 目のランドマーク取得
left_eye_points = landmarks_array[LEFT_EYE_INDICES]
right_eye_points = landmarks_array[RIGHT_EYE_INDICES]
# EAR計算
left_ear = calculate_ear(left_eye_points)
right_ear = calculate_ear(right_eye_points)
# 最初の顔のEARのみ履歴に追加
if face_idx == 0:
right_ear_history.append(right_ear)
left_ear_history.append(left_ear)
# EAR算出ポイント(12点)をプロット
for point in right_eye_points:
cv2.circle(extended_frame, (int(point[0]), int(point[1])), 3, RIGHT_EYE_COLOR, -1)
for point in left_eye_points:
cv2.circle(extended_frame, (int(point[0]), int(point[1])), 3, LEFT_EYE_COLOR, -1)
# 瞬き判定
right_blink = is_blink(right_ear)
left_blink = is_blink(left_ear)
# 画面表示
y_pos = 30 + face_idx * 50
cv2.putText(extended_frame, f'Face {face_idx+1}:', (10, y_pos),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 255, 255), 2)
cv2.putText(extended_frame, f'Right EAR: {right_ear:.3f} ({right_blink})', (10, y_pos+20),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, RIGHT_EYE_COLOR, 1)
cv2.putText(extended_frame, f'Left EAR: {left_ear:.3f} ({left_blink})', (10, y_pos+40),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, LEFT_EYE_COLOR, 1)
# 結果文字列作成
result = f'{right_ear:.6f}, {left_ear:.6f}'
# グラフ描画(右目・左目)
graph_x = extended_frame.shape[1] - GRAPH_WIDTH - GRAPH_MARGIN
# 右目グラフ(上段)
right_graph_y = GRAPH_MARGIN
draw_single_ear_graph(extended_frame, right_ear_history, graph_x, right_graph_y,
RIGHT_EYE_COLOR, "Right Eye EAR")
# 左目グラフ(下段)
left_graph_y = GRAPH_MARGIN * 2 + GRAPH_HEIGHT
draw_single_ear_graph(extended_frame, left_ear_history, graph_x, left_graph_y,
LEFT_EYE_COLOR, "Left Eye EAR")
return extended_frame, result
def video_frame_processing(frame, timestamp_ms, is_camera):
"""動画フレーム処理(標準形式)"""
global frame_count
current_time = time.time()
frame_count += 1
processed_frame, result = process_video_frame(frame, timestamp_ms, is_camera)
return processed_frame, result, current_time
# 入力選択
print('0: 動画ファイル')
print('1: カメラ')
print('2: サンプル動画')
choice = input('選択: ')
is_camera = (choice == '1')
if choice == '0':
root = tk.Tk()
root.withdraw()
path = filedialog.askopenfilename()
if not path:
raise SystemExit(1)
cap = ThreadedVideoCapture(path, is_camera=False)
elif choice == '1':
cap = ThreadedVideoCapture(0, is_camera=True)
else:
SAMPLE_URL = 'https://raw.githubusercontent.com/opencv/opencv/master/samples/data/vtest.avi'
SAMPLE_FILE = 'vtest.avi'
print('サンプル動画をダウンロード中...')
urllib.request.urlretrieve(SAMPLE_URL, SAMPLE_FILE)
cap = ThreadedVideoCapture(SAMPLE_FILE, is_camera=False)
if not cap.isOpened():
print('動画ファイル・カメラを開けませんでした')
raise SystemExit(1)
# カメラ情報表示とタイムスタンプ増分計算
if is_camera:
actual_fps = cap.get(cv2.CAP_PROP_FPS)
print(f'カメラのfps: {actual_fps}')
timestamp_increment = int(1000 / actual_fps) if actual_fps > 0 else 33
else:
video_fps = cap.get(cv2.CAP_PROP_FPS)
timestamp_increment = int(1000 / video_fps) if video_fps > 0 else 33
print()
print('\n=== 動画処理開始 ===')
print('操作方法:')
print(' q キー: プログラム終了')
print()
frame_count = 0
results_log = []
start_time = time.time()
last_info_time = start_time
info_interval = 10.0
timestamp_ms = 0
total_processing_time = 0.0
try:
while True:
ret, frame = cap.read()
if not ret:
break
timestamp_ms += timestamp_increment
processing_start = time.time()
processed_frame, result, current_time = video_frame_processing(frame, timestamp_ms, is_camera)
processing_time = time.time() - processing_start
total_processing_time += processing_time
cv2.imshow(WINDOW_NAME, processed_frame)
if result:
if is_camera:
timestamp = datetime.fromtimestamp(current_time).strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]
print(f'{timestamp}, {result}')
else:
print(f'Frame {frame_count}: {result}')
results_log.append(result)
# 情報提供(カメラモードのみ、10秒ごと)
if is_camera:
elapsed = current_time - last_info_time
if elapsed >= info_interval:
total_elapsed = current_time - start_time
actual_fps = frame_count / total_elapsed if total_elapsed > 0 else 0
avg_processing_time = (total_processing_time / frame_count * 1000) if frame_count > 0 else 0
print(f'[情報] 経過時間: {total_elapsed:.1f}秒, 処理フレーム数: {frame_count}, 実測fps: {actual_fps:.1f}, 平均処理時間: {avg_processing_time:.1f}ms')
last_info_time = current_time
if cv2.waitKey(1) & 0xFF == ord('q'):
break
finally:
print('\n=== プログラム終了 ===')
cap.release()
cv2.destroyAllWindows()
face_landmarker.close()
if results_log:
with open('result.txt', 'w', encoding='utf-8') as f:
f.write('=== EAR計算結果(新API版) ===\n')
f.write(f'処理フレーム数: {frame_count}\n')
if is_camera:
f.write('形式: タイムスタンプ, 右EAR, 左EAR\n')
else:
f.write('形式: フレーム番号, 右EAR, 左EAR\n')
f.write('\n')
f.write('\n'.join(results_log))
print('処理結果をresult.txtに保存しました')
カメラ60fps動作のための実装技術
本プログラムでは、カメラを60fpsで動作させるために複数の技術的工夫を実装している。以下、ソースコードを引用しながら各技術について解説する。
1. DirectShowバックエンドの明示的指定
self.cap = cv2.VideoCapture(src, cv2.CAP_DSHOW)Windows環境でカメラを開く際にcv2.CAP_DSHOWを明示的に指定している。OpenCVはデフォルトで複数のバックエンドを試行するが、DirectShowを直接指定することで初期化時間を短縮し、カメラとの通信を安定化させる。DirectShowはWindowsのマルチメディアフレームワークであり、カメラデバイスへの低レイテンシなアクセスを提供する。
2. Motion JPEGコーデックの設定
fourcc = cv2.VideoWriter_fourcc('M', 'J', 'P', 'G')
self.cap.set(cv2.CAP_PROP_FOURCC, fourcc)Motion JPEG(MJPEG)コーデックを明示的に設定している。多くのWebカメラはMJPEG形式での転送をサポートしており、YUV等の非圧縮形式と比較してUSBバス帯域幅を削減できる。これにより60fpsでのデータ転送が物理的に可能になる。
3. フレームレートの明示的要求
self.cap.set(cv2.CAP_PROP_FPS, 60)カメラに対して60fpsのフレームレートを要求している。カメラがこの設定をサポートしている場合、ハードウェアレベルで60fpsのキャプチャが有効化される。実際に達成されるfpsはカメラの仕様と環境条件に依存する。
4. スレッド化されたフレーム取得
class ThreadedVideoCapture:
def __init__(self, src, is_camera=False):
# ... 初期化処理 ...
self.thread = threading.Thread(target=self.update, args=())
self.thread.daemon = True
self.thread.start()
def update(self):
"""バックグラウンドでフレームを取得し続ける"""
while not self.stopped:
grabbed, frame = self.cap.read()
with self.lock:
self.grabbed = grabbed
if grabbed:
self.frame = frameThreadedVideoCaptureクラスは、フレーム取得を独立したスレッドで実行する。メインスレッドが画像処理や描画に時間を費やしている間も、バックグラウンドスレッドは継続的にカメラから最新フレームを取得する。これにより処理遅延によるフレームドロップを防止する。
スレッド間の排他制御にはthreading.Lockを使用している。
self.lock = threading.Lock()update()メソッドとread()メソッドの両方でwith self.lock:ブロックを使用することで、フレームデータへの同時アクセスを防止し、データ競合を回避している。
5. デーモンスレッドの活用
self.thread.daemon = True取得スレッドをデーモンスレッドとして設定している。これによりメインプログラムが終了する際に明示的なスレッド終了処理を待たずにプロセス全体を終了できる。ただし、適切なリソース解放のためにrelease()メソッドも実装されている。
def release(self):
self.stopped = True
self.thread.join()
self.cap.release()6. 最新フレームの優先取得
def read(self):
"""最新フレームを返す"""
with self.lock:
return self.grabbed, self.frame.copy() if self.grabbed else Noneread()メソッドは常に最新のフレームを返す。従来の同期的な実装では、処理が遅延すると内部バッファに古いフレームが蓄積され、表示が実時間から遅れる現象が発生する。本実装では、バッファリングを行わず常に最新フレームのみを保持することでリアルタイム性を確保している。
7. フレームのコピーによるデータ保護
return self.grabbed, self.frame.copy() if self.grabbed else Noneread()メソッドはフレームのコピーを返している。これによりメインスレッドがフレームを処理している間にバックグラウンドスレッドが同じメモリ領域を上書きすることを防止する。copy()によるオーバーヘッドは発生するが、データ整合性を保証するために必要な処理である。
8. 実測fpsの監視機能
if is_camera:
actual_fps = cap.get(cv2.CAP_PROP_FPS)
print(f'カメラのfps: {actual_fps}')カメラの実際のfps設定値を取得し表示している。これにより60fpsの要求が実際に受け入れられたかを確認できる。
さらに実行中の実測fpsも定期的に計算・表示している。
if is_camera:
elapsed = current_time - last_info_time
if elapsed >= info_interval:
total_elapsed = current_time - start_time
actual_fps = frame_count / total_elapsed if total_elapsed > 0 else 0
avg_processing_time = (total_processing_time / frame_count * 1000) if frame_count > 0 else 0
print(f'[情報] 経過時間: {total_elapsed:.1f}秒, 処理フレーム数: {frame_count}, 実測fps: {actual_fps:.1f}, 平均処理時間: {avg_processing_time:.1f}ms')10秒ごとに実測fps、処理フレーム数、平均処理時間を表示することで、実際のパフォーマンスを監視できる。
まとめ
本プログラムは、DirectShowバックエンドの指定、MJPEGコーデックの設定、明示的なfps要求、スレッド化されたフレーム取得、最新フレーム優先の戦略を組み合わせることで、カメラの60fps動作を実現している。これらの技術は相互に補完的であり、単一の技術では達成困難なフレームレートでの動作を可能にしている。
実験・研究スキルの基礎:Windowsで学ぶ瞬き検出実験
1. 実験・研究のスキル構成要素
実験や研究を行うには、以下の5つの構成要素を理解する必要がある。
1.1 実験用データ
このプログラムでは、動画ファイルまたはカメラ映像が実験用データである。顔が映っている動画であれば、目の開閉状態を数値化して分析できる。
1.2 実験計画
何を明らかにするために実験を行うのかを定める。
計画例:
- EAR閾値が瞬き検出精度に与える影響を調べる
- 顔検出信頼度閾値が検出安定性に与える影響を調べる
- 照明条件の変化が検出精度に与える影響を調べる
- 顔の向きや角度が検出精度に与える影響を調べる
- 誤検出(瞬きではないのに瞬きと判定)を最小化するパラメータ設定を調べる
- 見逃し(実際の瞬きを検出できない)を減らすパラメータ設定を調べる
1.3 プログラム
実験を実施するためのツールである。このプログラムはMediaPipe Face Landmarkerを使用して顔の478点のランドマークを検出し、目の周囲12点の座標からEAR(Eye Aspect Ratio)を計算する。
- プログラムの機能を理解して活用することが基本である
- 基本となるプログラムを出発点として、将来、様々な機能を自分で追加することができる
1.4 プログラムの機能
このプログラムは2つのパラメータで瞬き検出を制御する。
入力パラメータ:
- EAR閾値(EAR_THRESH): 瞬き判定の基準値(デフォルト0.2)。この値より小さいEAR値を「瞬き」と判定する
- 顔検出信頼度閾値(CONF_THRESH): 顔検出の最低信頼度(デフォルト0.5)
出力情報:
- 入力映像に目のランドマーク12点(右目6点、左目6点)を描画して表示
- 右目と左目のEAR値をリアルタイムで数値表示
- 瞬き判定結果(「瞬き」または「開眼」)を表示
- 右目と左目のEAR推移グラフを別々に表示
- コンソールに各フレームのEAR値を出力
- プログラム終了時にresult.txtファイルに全フレームの処理結果を保存
EAR(Eye Aspect Ratio)の計算原理:
- 目の周囲6点の座標から、垂直方向の距離と水平方向の距離の比率を求める
- 計算式: EAR = (||p2-p6|| + ||p3-p5||) / (2 × ||p1-p4||)
- 目が開いているときはEAR値が大きく、閉じているときは小さくなる
1.5 検証(結果の確認と考察)
プログラムの実行結果を観察し、パラメータの影響を考察する。
基本認識:
- パラメータを変えると結果が変わる。その変化を観察することが実験である
- 「良い結果」「悪い結果」は目的によって異なる
- EAR値には個人差がある。目の形状やまぶたの開き具合により最適な閾値が異なる
観察のポイント:
- EAR値は瞬き時にどの程度まで下がるか
- 通常の開眼状態でのEAR値はどの程度か
- 誤検出(瞬きではないのに瞬きと判定される)は発生しているか
- 見逃し(実際の瞬きが検出されない)は発生しているか
- 左右の目でEAR値に差があるか
- 顔の向きを変えたときに検出精度は変化するか
2. 間違いの原因と対処方法
2.1 プログラムのミス(人為的エラー)
プログラムがエラーで停止する場合
- 原因: 必要なライブラリがインストールされていない、またはPythonバージョンの不整合
- 対処方法: 「pip install mediapipe opencv-python numpy」を実行してライブラリをインストールする
モデルのダウンロードに失敗する場合
- 原因: ネットワーク接続の問題、またはファイアウォールによるブロック
- 対処方法: ネットワーク接続を確認する。モデルファイル(face_landmarker.task)を手動でダウンロードし、プログラムと同じフォルダに配置する
カメラが開けない場合
- 原因: カメラが他のアプリケーションで使用中、またはカメラドライバの問題
- 対処方法: 他のアプリケーション(ビデオ会議ソフトなど)を終了する。デバイスマネージャでカメラドライバを確認する
動画ファイルが開けない場合
- 原因: ファイルパスに日本語が含まれている、またはサポートされていない動画形式
- 対処方法: ファイルを英数字のみのパスに移動する。MP4やAVI形式の動画を使用する
2.2 期待と異なる結果が出る場合
顔が検出されない場合
- 原因: 照明が暗すぎる、顔が小さすぎる、または顔が大きく傾いている
- 対処方法: 照明を明るくする。カメラに顔を近づける。顔を正面に向ける
瞬きが検出されない場合
- 原因: EAR閾値が低すぎる
- 対処方法: EAR_THRESHの値を0.25や0.3に上げて確認する。自分の通常のEAR値を観察してから閾値を調整する
常に「瞬き」と判定される場合
- 原因: EAR閾値が高すぎる、または目の形状により通常のEAR値が低い
- 対処方法: EAR_THRESHの値を0.15や0.1に下げて確認する。グラフで自分の通常のEAR値を確認する
左右の目で検出精度が異なる場合
- 原因: 顔が斜めを向いている、または左右の目の形状に差がある
- 対処方法: 左右の目の形状に差がある場合、これは正常な結果である。左右それぞれのEAR値を観察し、必要に応じて左右別々の閾値を設定することを検討する
処理速度が遅い場合
- 原因: PCの性能不足、または他のアプリケーションがリソースを消費している
- 対処方法: 不要なアプリケーションを終了する。動画ファイルを使用する場合は解像度の低い動画を使用する
3. 実験レポートのサンプル
EAR閾値の最適化による瞬き検出精度の向上
実験目的:
自分の目の形状に適したEAR閾値を見つけ、誤検出と見逃しを最小化する。
実験計画:
顔検出信頼度閾値(CONF_THRESH)をxxxxに固定し、EAR閾値(EAR_THRESH)を変化させて最適値を探す。
実験方法:
カメラを使用してリアルタイムで計測を行う。以下の手順で評価する。
- まず通常の開眼状態でのEAR値を10秒間観察し、平均値を記録する
- 意図的に瞬きを10回行い、瞬き時のEAR最小値を記録する
- 異なるEAR閾値を設定し、30秒間の瞬き検出精度を評価する
評価基準:
- 正検出数: 実際の瞬きが正しく検出された回数
- 誤検出数: 瞬きではないのに瞬きと判定された回数
- 見逃し数: 実際の瞬きが検出されなかった回数
実験結果:
| EAR閾値 | 正検出数 | 誤検出数 | 見逃し数 | 総合評価 |
|---|---|---|---|---|
| xxxx | x | x | x | x |
| xxxx | x | x | x | x |
| xxxx | x | x | x | x |
| xxxx | x | x | x | x |
考察:
- (例文)通常の開眼状態でのEAR平均値はxxxxであり、瞬き時のEAR最小値はxxxxであった。この差を考慮して閾値を設定する必要がある
- (例文)EAR閾値xxxxでは誤検出が多発した。目を細めたり、下を向いたりするだけで瞬きと判定される傾向が見られた
- (例文)EAR閾値xxxxでは見逃しが増加した。素早い瞬きや浅い瞬きが検出されない傾向が見られた
- (例文)EAR閾値を上げると誤検出は減るが、同時に見逃しも増えるというトレードオフの関係が確認できた
結論:
(例文)本実験において、自分の目の形状に最適なEAR閾値はxxxxであった。この値は通常の開眼状態のEAR平均値のxxxx%に相当する。個人差が大きいため、使用者ごとにキャリブレーション(開眼状態のEAR値測定)を行い、その値に基づいて閾値を設定することが望ましい。
心理状態・生理状態と瞬き頻度の関係
実験目的:
自分の心理状態や生理状態が瞬き頻度に与える影響を観察し、状態と瞬きパターンの関係を把握する。
実験計画:
EAR閾値(EAR_THRESH)をxxxxに固定し、異なる状態での瞬き頻度を計測して比較する。
実験方法:
カメラを使用して各状態で60秒間の計測を行う。以下の条件で計測を行い、瞬き頻度を記録する。
- リラックス状態: 深呼吸を数回行い、落ち着いた状態で計測する
- 集中状態: 計算問題や文章読解など、注意を要する課題を行いながら計測する
- 緊張状態: 制限時間内に暗算を行う、または人前で話すことを想定して原稿を読み上げるなど、プレッシャーを感じる状況で計測する
- 疲労状態: 長時間の作業後や睡眠不足の状態で計測する
- 眠気がある状態: 眠気を感じている時間帯に計測する
評価基準:
- 瞬き頻度: 1分あたりの瞬き回数
- 平均瞬き間隔: 瞬きと瞬きの間の平均時間(秒)
- EAR最小値: 瞬き時のEAR最小値の平均
実験結果:
| 状態 | 瞬き頻度(回/分) | 平均瞬き間隔(秒) | EAR最小値平均 |
|---|---|---|---|
| リラックス | x | x | x |
| 集中 | x | x | x |
| 緊張 | x | x | x |
| 疲労 | x | x | x |
| 眠気 | x | x | x |
考察:
- (例文)リラックス状態での瞬き頻度はxxxx回/分であり、これを基準値として他の状態と比較した
- (例文)集中状態では瞬き頻度がxxxx回/分に減少した。注意を要する課題に取り組んでいる間、瞬きが抑制される傾向が観察された
- (例文)緊張状態では瞬き頻度がxxxx回/分に増加した。プレッシャーを感じている状況で瞬きが増える傾向が見られた
- (例文)疲労状態では瞬き頻度がxxxx回/分となり、瞬き1回あたりの閉眼時間が長くなる傾向が観察された
- (例文)眠気がある状態ではEAR最小値が他の状態より低く、目を閉じている時間が長い傾向が見られた
結論:
(例文)本実験において、心理状態や生理状態によって瞬き頻度やパターンに違いがあることが観察された。集中時には瞬きが減少し、緊張時には増加する傾向が見られた。また、疲労や眠気がある状態では瞬きの質(閉眼時間やEAR最小値)にも変化が現れた。これらの観察結果から、瞬きパターンの分析が自己の状態把握に活用できる可能性が示唆された。