SigLIP2によるゼロショット画像分類
SigLIP2(Vision Transformerベース)を用いて事前学習なしの単語等による画像分類を行うゼロショット学習。SigLIP2の4種類のモデル(base-patch16-224からso400m-patch14-384)の性能比較ができるPythonプログラム、画像とテキストの埋め込み空間や類似度計算などの解説付き。

目次
基本概念
2.1 ゼロショット学習の原理
ゼロショット学習は、画像とテキストを同一の高次元空間(埋め込み空間)にマッピングし、その空間内での類似度を計算することで分類を行う[1]。
処理フロー:
[入力画像] → [画像encoder] → [画像特徴ベクトル] ↘
[類似度計算] → [分類結果]
[テキストラベル] → [テキストencoder] → [テキスト特徴ベクトル] ↗
2.2 SigLIP2(Sigmoid Loss for Language-Image Pre-training 2)
SigLIP2は、SigLIPの訓練レシピを基に構築された多言語ビジョン言語エンコーダーである。デコーダーベース事前訓練、自己蒸留、マスク予測を含む統合レシピにより、密な予測タスクでの大幅な改善を実現している[2]。
2.3 Vision Transformer(ViT)
SigLIP2で使用されるViTは、画像を固定サイズのパッチに分割し、各パッチを線形埋め込みによってベクトルに変換する。その後、標準的なTransformerエンコーダで処理する[3]。
2.4 特徴量正規化
特徴量正規化は、ベクトルの大きさを1に統一する処理である。これにより、類似度計算時にベクトルの方向のみが重要となり、より安定した分類が可能になる。
用語集
SigLIP2: SigLIPの改良版で、多言語対応、密な特徴量、改良されたセマンティック理解を提供するビジョン言語モデル。
Vision Transformer (ViT): 画像をパッチに分割し、Transformerアーキテクチャを用いて処理する画像認識モデル。
ゼロショット学習: 訓練時に見たことのないクラスに対しても分類を行う機械学習手法。
対照学習: 類似したデータペアの表現を近づけ、異なるデータペアの表現を遠ざけることで学習を行う手法。
埋め込み空間: 高次元データを低次元の連続ベクトル空間にマッピングした表現空間。
Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
インストール済みの場合は実行不要。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent --accept-source-agreements --accept-package-agreements
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】
Python の公式ページ: https://www.python.org/
AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AI エディタの利用を推奨する。ここでは,Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行して、Windsurfをシステム全体にインストールする。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
winget install --scope machine --id Codeium.Windsurf -e --silent --accept-source-agreements --accept-package-agreements【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
必要なライブラリをシステム領域にインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する
pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
pip install transformers pillow accelerate opencv-python
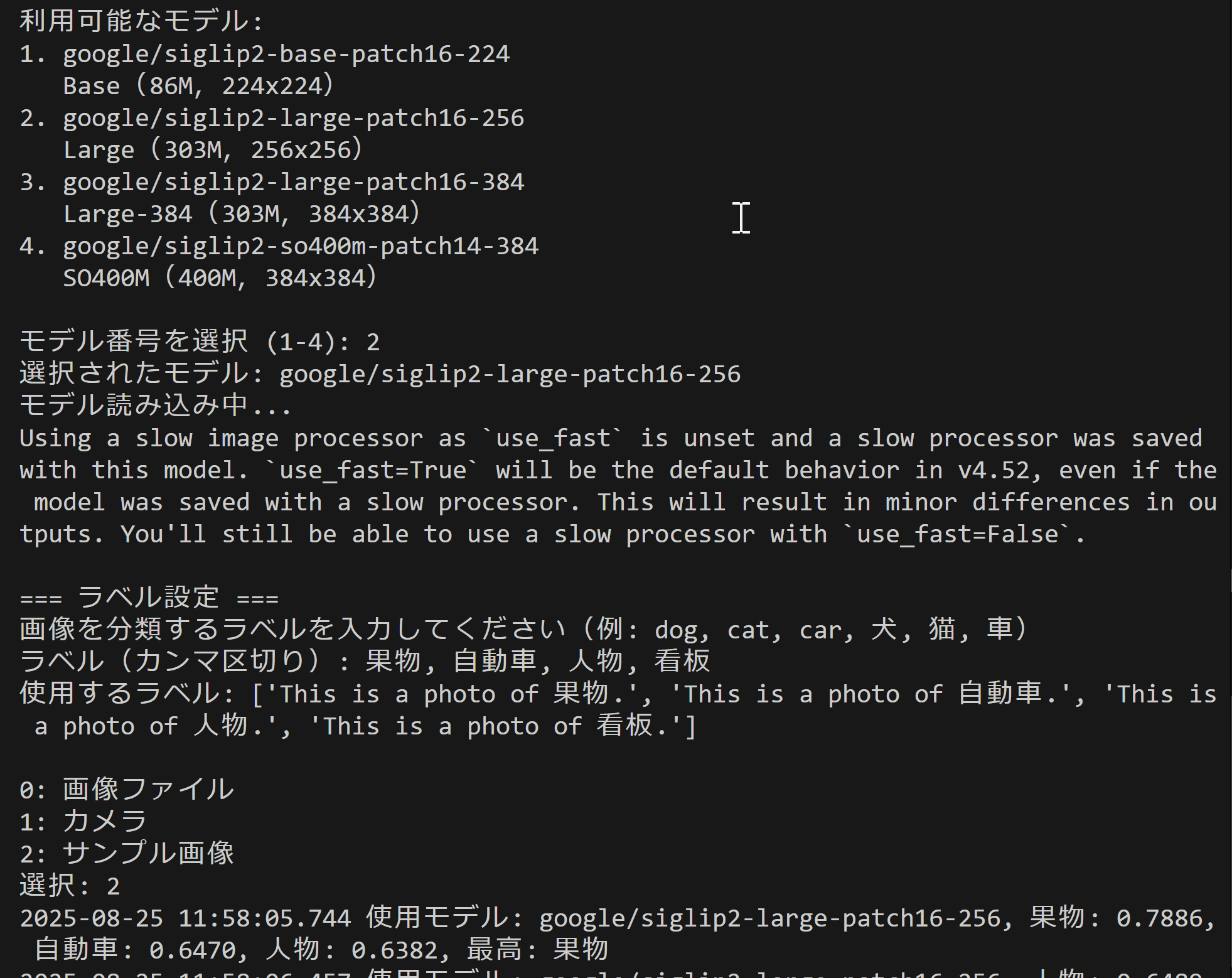
SigLIP2画像分類プログラム
概要
本プログラムは、SigLIP2 (Sigmoid Loss for Language-Image Pre-training 2) モデルを用いた画像分類システムである。入力画像に対して複数のテキストラベルとの類似度を計算し、最も適合するラベルを特定する。画像入力はファイル選択、カメラ撮影、サンプル画像から選択可能であり、処理結果はリアルタイムで表示され、最終的にファイルに保存される。
主要技術
SigLIP2 (Sigmoid Loss for Language-Image Pre-training 2)
SigLIP2は、Googleが開発した視覚言語モデルである[1]。従来のCLIP (Contrastive Language-Image Pre-training) モデルと異なり、Sigmoid損失関数を採用することで、学習の安定性と計算効率を向上させている。画像とテキストを共通の埋め込み空間にマッピングし、その類似度を計算することで、ゼロショット画像分類を実現する。
本システムでは、4種類のSigLIP2モデルから選択可能である:Base (86Mパラメータ、224×224解像度)、Large (303Mパラメータ、256×256解像度)、Large-384 (303Mパラメータ、384×384解像度)、SO400M (400Mパラメータ、384×384解像度)。各モデルはHugging Face Model Hubから利用可能である[2]。
技術的特徴
類似度計算アルゴリズム
本システムの中核となる類似度計算は、以下の手順で実行される:
- 画像とテキストを各々の埋め込みベクトルに変換
- L2正規化により単位ベクトル化
- 内積計算によるコサイン類似度の算出
- 温度パラメータ(SCALE=10.0)によるスケーリング
- Sigmoid関数適用による0-1範囲への正規化
温度パラメータは類似度スコアの分散を制御し、値が大きいほどラベル間の差異が明確になる。この手法により、確率的解釈が可能なスコアを生成する。
実装の特色
マルチリンガル対応
英語ラベルには「This is a photo of」テンプレートを適用し、日本語を含む非英語ラベルはテンプレートなしで直接処理する。これにより、多言語での画像分類を実現している。
GPU/CPU自動選択とデータ型最適化
PyTorchのCUDA利用可能性を自動判定し、GPU使用時はfloat16、CPU使用時はfloat32のデータ型を選択する。これにより、計算資源に応じた最適な処理を実現する。
リアルタイム処理と結果保存
OpenCVを用いた画像表示により、処理結果をリアルタイムで確認できる。カメラモードでは連続的な撮影と分類が可能であり、全処理結果はタイムスタンプ付きでresult.txtファイルに保存される。
参考文献
[1] Zhai, X., et al. (2025). SigLIP 2: Scaling Vision-Language Models with Sigmoid Loss. arXiv preprint arXiv:2501.09893. https://arxiv.org/abs/2501.09893
[2] Hugging Face. (2025). SigLIP2 Models. https://huggingface.co/collections/google/siglip2-release-6762f0cf5da2d58e0f773e47
ソースコード
# プログラム名: SigLIP2による画像分類システム
# 特徴技術名: SigLIP2 (Sigmoid Loss for Language-Image Pre-training 2)
# 出典: X. Zhai et al., "SigLIP 2: Scaling Vision-Language Models with Sigmoid Loss," arXiv preprint arXiv:2501.09893, 2025.
# 特徴機能: 画像とテキストの埋め込みベクトルを正規化後、内積によるコサイン類似度を計算し、温度パラメータでスケーリング後Sigmoid関数を適用することで0-1の確率的スコアを生成。これにより安定した学習とマッチングを実現
# 学習済みモデル:
# - google/siglip2-base-patch16-224 (Base, 86M params, 224x224): https://huggingface.co/google/siglip2-base-patch16-224
# - google/siglip2-large-patch16-256 (Large, 303M params, 256x256): https://huggingface.co/google/siglip2-large-patch16-256
# - google/siglip2-large-patch16-384 (Large, 384M params, 384x384): https://huggingface.co/google/siglip2-large-patch16-384
# - google/siglip2-so400m-patch14-384 (SO400M, 400M params, 384x384): https://huggingface.co/google/siglip2-so400m-patch14-384
# 方式設計:
# - 関連利用技術: PyTorch (ディープラーニングフレームワーク), Transformers (モデルロード・推論), PIL/Pillow (画像形式変換), OpenCV (画像入出力・表示), tkinter (ファイル選択ダイアログ)
# - 入力と出力:
# 入力: 静止画像(ユーザは「0:画像ファイル,1:カメラ,2:サンプル画像」のメニューで選択.0:画像ファイルの場合はtkinterで複数ファイル選択可能.1の場合はOpenCVでカメラが開き,スペースキーで撮影(複数回可能).2の場合はhttps://raw.githubusercontent.com/opencv/opencv/master/samples/data/fruits.jpg とhttps://raw.githubusercontent.com/opencv/opencv/master/samples/data/messi5.jpgとhttps://raw.githubusercontent.com/opencv/opencv/master/samples/data/aero3.jpgを使用)
# 出力: OpenCV画面でリアルタイムに処理結果表示,OpenCV画面内に最高スコアラベルとスコア値をテキスト表示,プログラム終了時に処理結果をresult.txtファイルに保存し「result.txtに保存」したことをprint()で表示
# - 処理手順: 1.モデル選択とロード 2.画像入力取得 3.ラベル文字列入力 4.画像をRGB変換 5.テキストと画像を埋め込みベクトルに変換 6.ベクトル正規化 7.コサイン類似度計算 8.温度パラメータでスケーリング 9.Sigmoid関数適用 10.スコア表示と保存
# - 前処理、後処理:
# 前処理: 画像のRGB変換(グレースケール・RGBA対応)、テキストの小文字化と「This is a photo of」テンプレート適用(英語ラベルのみ)、max_length=64でのパディング
# 後処理: スコアの降順ソート、最高スコアラベルの特定、画像へのオーバーレイ描画(スコアとラベル表示)
# - 追加処理: 日本語ラベル対応(英語以外のラベルはテンプレートなしで直接使用)、複数モデル選択機能(4種類のSigLIP2モデルから選択可能)、GPU/CPU自動判定とdtype整合性確保(GPU時はfloat16、CPU時はfloat32)
# - 調整を必要とする設定値: SCALE(温度パラメータ、デフォルト10.0)- スコアの分散を制御し、類似度の差を強調。値が大きいほどスコアの差が明確になる
# 将来方策: SCALE値の自動調整機能 - 複数画像のスコア分布を統計的に分析し、分散が0.1-0.3の範囲になるようSCALE値を動的に調整することで、各データセットに最適な識別性能を実現
# その他の重要事項: SigLIP2は2025年1月発表の最新モデルで、従来のCLIPと比較してマルチリンガル対応と計算効率が向上
# 前準備:
# - pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
# - pip install transformers pillow accelerate opencv-python
import cv2
import tkinter as tk
from tkinter import filedialog
import urllib.request
import os
import time
from datetime import datetime
import numpy as np
import torch
from transformers import AutoModel, AutoProcessor
from PIL import Image, ImageDraw, ImageFont
# 設定定数
MODELS = {
'google/siglip2-base-patch16-224': 'Base(86M,224x224)',
'google/siglip2-large-patch16-256': 'Large(303M,256x256)',
'google/siglip2-large-patch16-384': 'Large-384(303M,384x384)',
'google/siglip2-so400m-patch14-384': 'SO400M(400M,384x384)'
}
MODEL_COUNT = 4 # 選択可能なモデル数
SCALE = 10.0 # 温度パラメータ(スコアの分散を制御)
FONT_PATH = 'C:/Windows/Fonts/meiryo.ttc' # 日本語フォントパス
FONT_SIZE = 20 # フォントサイズ
# GPU/CPU自動選択
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'デバイス: {str(device)}')
# GPU使用時の最適化
if device.type == 'cuda':
torch.backends.cudnn.benchmark = True
# フォント存在確認
HAS_JAPANESE_FONT = os.path.exists(FONT_PATH)
# 処理結果を保存するリスト
results_log = []
# グローバル変数
model = None
processor = None
labels = []
formatted_labels = []
model_name = ''
def is_english_word(text):
"""文字列が英単語(英数字とスペースのみ)かどうかを判定"""
for char in text.strip():
if not (char.isalnum() or char.isspace()):
return False
has_alpha = any(c.isalpha() for c in text.strip())
return has_alpha
def image_processing(img):
"""画像を処理してスコアを計算し,オーバーレイを付与したBGR画像を返す"""
global model, processor, device, labels, formatted_labels, model_name
current_time = time.time()
# OpenCV画像→PIL
if isinstance(img, np.ndarray):
img_pil = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
else:
img_pil = img
# RGB変換
if img_pil.mode != 'RGB':
img_pil = img_pil.convert('RGB')
# プロセッサでテンソル化
inputs = processor(
text=formatted_labels,
images=img_pil,
return_tensors='pt',
padding='max_length',
max_length=64
)
# device/dtype整合
inputs = {k: (v.to(device) if isinstance(v, torch.Tensor) else v) for k, v in inputs.items()}
target_dtype = next(model.parameters()).dtype
if 'pixel_values' in inputs and isinstance(inputs['pixel_values'], torch.Tensor):
inputs['pixel_values'] = inputs['pixel_values'].to(dtype=target_dtype)
# 推論
with torch.no_grad():
outputs = model(**inputs)
image_embeds = outputs.image_embeds
text_embeds = outputs.text_embeds
# 正規化
image_embeds = image_embeds / image_embeds.norm(dim=-1, keepdim=True)
text_embeds = text_embeds / text_embeds.norm(dim=-1, keepdim=True)
# 類似度計算
similarity = (image_embeds @ text_embeds.T).squeeze(0)
similarity = similarity * SCALE
scores = torch.sigmoid(similarity)
# 表示用画像
result_img_bgr = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
# スコア出力
sorted_indices = torch.argsort(scores, descending=True).detach().cpu().tolist()
result_text = f'使用モデル: {model_name}, '
for idx in sorted_indices[:3]: # 上位3つのみ表示
result_text += f'{labels[idx]}: {scores[idx].item():.4f}, '
top_label = labels[sorted_indices[0]]
top_score = scores[sorted_indices[0]].item()
result_text += f'最高: {top_label}'
# オーバーレイ描画
cv2.putText(result_img_bgr, f'Score: {top_score:.4f}', (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
# 日本語ラベル表示
if HAS_JAPANESE_FONT:
font = ImageFont.truetype(FONT_PATH, FONT_SIZE)
tmp = Image.fromarray(cv2.cvtColor(result_img_bgr, cv2.COLOR_BGR2RGB))
ImageDraw.Draw(tmp).text((10, 70), f'Label: {top_label}', font=font, fill=(255, 255, 255))
result_img_bgr = cv2.cvtColor(np.array(tmp), cv2.COLOR_RGB2BGR)
else:
cv2.putText(result_img_bgr, f'Label: {top_label}', (10, 70),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 255, 255), 2)
return result_img_bgr, result_text, current_time
def process_and_display_images(image_sources, source_type):
display_index = 1
for source in image_sources:
img = cv2.imread(source) if source_type == 'file' else source
if img is None:
continue
cv2.imshow(f'Image_{display_index}', img)
processed_img, result, current_time = image_processing(img)
cv2.imshow(f'SigLIP2分類結果_{display_index}', processed_img)
print(datetime.fromtimestamp(current_time).strftime("%Y-%m-%d %H:%M:%S.%f")[:-3], result)
results_log.append(result)
display_index += 1
# プログラム開始
print('=== SigLIP2による画像分類システム ===')
print('概要: 画像を入力し,指定ラベルとの類似度を計算して表示・保存する')
print('操作方法: カメラモードではスペースキーで撮影,qキーで終了\n')
# モデル選択
print('利用可能なモデル:')
model_list = list(MODELS.keys())
for i, (mn, desc) in enumerate(MODELS.items()):
print(f'{i+1}. {mn}')
print(f' {desc}')
choice = input('\nモデル番号を選択 (1-4): ')
if not choice.isdigit() or not (1 <= int(choice) <= MODEL_COUNT):
print('無効な選択')
exit()
model_name = model_list[int(choice) - 1]
# モデル初期化
print(f'選択されたモデル: {model_name}')
print('モデル読み込み中...')
if device.type == 'cuda':
model = AutoModel.from_pretrained(model_name, torch_dtype=torch.float16).to(device)
else:
model = AutoModel.from_pretrained(model_name, torch_dtype=torch.float32).to(device)
processor = AutoProcessor.from_pretrained(model_name)
model.eval()
# ラベル入力
print('\n=== ラベル設定 ===')
print('画像を分類するラベルを入力してください(例: dog, cat, car, 犬, 猫, 車)')
labels_input = input('ラベル(カンマ区切り): ')
if not labels_input.strip():
print('ラベルが入力されていない')
exit()
labels = [label.strip() for label in labels_input.split(',')]
formatted_labels = []
for lbl in labels:
if is_english_word(lbl):
formatted_labels.append(f'This is a photo of {lbl.lower()}.')
else:
formatted_labels.append(lbl)
print(f'使用するラベル: {formatted_labels}')
# 画像入力選択
print('\n0: 画像ファイル')
print('1: カメラ')
print('2: サンプル画像')
choice = input('選択: ')
try:
if choice == '0':
root = tk.Tk()
root.withdraw()
if not (paths := filedialog.askopenfilenames()):
exit()
process_and_display_images(paths, 'file')
cv2.waitKey(0)
elif choice == '1':
cap = cv2.VideoCapture(0, cv2.CAP_DSHOW)
if not cap.isOpened():
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
try:
print('カメラが起動しました。スペースキーで撮影,qキーで終了')
while True:
ret, frame = cap.read()
if not ret:
break
cv2.imshow('Camera', frame)
key = cv2.waitKey(1) & 0xFF
if key == ord(' '):
processed_img, result, current_time = image_processing(frame)
cv2.imshow('SigLIP2分類結果', processed_img)
print(datetime.fromtimestamp(current_time).strftime("%Y-%m-%d %H:%M:%S.%f")[:-3], result)
results_log.append(result)
elif key == ord('q'):
break
finally:
cap.release()
else:
urls = [
"https://raw.githubusercontent.com/opencv/opencv/master/samples/data/fruits.jpg",
"https://raw.githubusercontent.com/opencv/opencv/master/samples/data/messi5.jpg",
"https://raw.githubusercontent.com/opencv/opencv/master/samples/data/aero3.jpg",
"https://upload.wikimedia.org/wikipedia/commons/3/3a/Cat03.jpg"
]
downloaded_files = []
for i, url in enumerate(urls):
try:
urllib.request.urlretrieve(url, f"sample_{i}.jpg")
downloaded_files.append(f"sample_{i}.jpg")
except:
print(f"画像のダウンロードに失敗しました: {url}")
process_and_display_images(downloaded_files, 'file')
cv2.waitKey(0)
finally:
print('\n=== プログラム終了 ===')
cv2.destroyAllWindows()
if results_log:
with open('result.txt', 'w', encoding='utf-8') as f:
f.write('=== 結果 ===\n')
f.write(f'使用デバイス: {str(device).upper()}\n')
if device.type == 'cuda':
f.write(f'GPU: {torch.cuda.get_device_name(0)}\n')
f.write('\n')
f.write('\n'.join(results_log))
print(f'\n処理結果をresult.txtに保存しました')
実行手順
- プログラムを実行
- モデル番号を選択(1-4)
- 分類ラベルを入力
モデル選択指針と実験アイデア
モデル選択指針
| モデル | パラメータ数 | 推論速度 | 精度 | 推奨用途 |
|--------|-------------|----------|------|----------|
| base-patch16-224 | 86M | 高速 | 基本 | 初回実験、プロトタイプ |
| large-patch16-256 | 303M | 中速 | 良好 | 一般的な応用 |
| large-patch16-384 | 303M | 低速 | 高精度 | 詳細分類 |
| so400m-patch14-384 | 400M | 最低速 | 最高精度 | 研究・精密実験 |
実験のアイデア
- 軽量モデル vs 高精度モデル: 同一画像・同一ラベルでbase-patch16-224とso400m-patch14-384の出力を比較し、精度向上と処理時間増加のトレードオフを分析する
- 抽象概念 vs 具体概念: 「猫」「犬」のような具体的ラベルと「幸せな雰囲気」「静寂」のような抽象的ラベルで分類精度を比較し、SigLIP2の理解の限界を探る
- 文脈情報の効果: 「犬」と「家庭の犬」「警察犬」のように文脈を含むラベルでの分類差異を観察し、文脈理解能力を評価する
- 詳細度の段階: 「動物」→「犬」→「柴犬」のように詳細度を変えたラベルでの認識精度変化を分析する
- 画像の複雑さと精度: 単一オブジェクトの画像と複数オブジェクトが混在する画像での分類精度差を比較する
- 撮影条件の影響: 同じ対象を異なる照明・角度・背景で撮影した画像での分類安定性を検証する
- 画質と分類性能: 高解像度画像と低解像度画像での分類精度変化を観察し、画質の影響度を評価する
これらの実験を通じて、AIがどのように画像を理解し、言語との対応付けを行っているかの新たな発見が期待できる。