日本語BERT文脈埋め込み分析
【概要】 BERTは文脈を考慮した単語埋め込み技術で、同一単語でも文脈により異なるベクトル表現を生成する。日本語BERT(tohoku-nlp/bert-base-japanese-v3)を用いて「手」の多義性を分析。身体部位としての「手」と方法・手段としての「手」のベクトル類似度を計算し、文脈による意味の違いを数値化。コサイン類似度とヒートマップで可視化し、BERTの文脈理解能力を実験的に確認する。

1. 概要
主要技術:BERT(Bidirectional Encoder Representations from Transformers)
出典:Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 4171-4186).
技術の特徴:BERTは文章中の各単語を前後の文脈を考慮して理解する技術である。従来の単語埋め込みでは単語に固定的なベクトルを割り当てていたが、BERTでは同じ単語でも使われる文脈によって異なるベクトル表現を生成する。これにより多義語の意味識別が可能となる。
アプリ例:文書分類、質問応答、感情分析、機械翻訳
体験価値:「手」という単語が文脈により異なる意味(身体部位/方法)を持つことを、ベクトルの類似度として数値的に観察できる。
2. 事前準備
Python, Windsurfをインストールしていない場合の手順(インストール済みの場合は実行不要)。
- 管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)。
- 以下のコマンドをそれぞれ実行する(winget コマンドは1つずつ実行)。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent
REM Windsurf をシステム領域にインストール
winget install --scope machine --id Codeium.Windsurf -e --silent
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul
REM Windsurf のパス設定
set "WINDSURF_PATH=C:\Program Files\Windsurf"
if exist "%WINDSURF_PATH%" (
echo "%PATH%" | find /i "%WINDSURF_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%WINDSURF_PATH%" /M >nul
)必要なPythonライブラリのインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。
pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
pip install transformers scikit-learn matplotlib numpy unidic-lite fugashi japanize-matplotlib
3. プログラムコード
ソースコード
# プログラム名: 日本語BERT文脈埋め込み分析プログラム
# 特徴技術名: BERT (Bidirectional Encoder Representations from Transformers)
# 出典: Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL-HLT 2019.
# 特徴機能: 文脈依存的な単語埋め込み生成(768次元)
# 学習済みモデル: tohoku-nlp/bert-base-japanese-v3
# 方式設計:
# - 利用技術:
# - Transformers: モデルとトークナイザーのロード・推論
# - PyTorch: テンソル演算と推論
# - scikit-learn: コサイン類似度計算
# - matplotlib/japanize_matplotlib: 可視化
# - fugashi/unidic-lite: 形態素解析
# - 入出力: 入力は日本語文リスト、出力はコンソール表示・ヒートマップ・result.txt保存
# - 処理手順: 形態素解析→トークン化→埋め込み抽出→類似度計算→可視化
# - 後処理: 対象語が複数トークンに分割された場合は平均ベクトルを使用する
# - 設定値: TARGET_WORD(デフォルト: "手")、MODEL_NAME(デフォルト: "tohoku-nlp/bert-base-japanese-v3")
# 前準備:
# - pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
# - pip install transformers scikit-learn matplotlib numpy japanize-matplotlib
# - pip install fugashi[unidic-lite]
# 注意: 初回実行時はモデルのダウンロードに時間を要する
import sys
import warnings
warnings.filterwarnings('ignore')
import torch
from transformers import AutoTokenizer, AutoModel
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
import matplotlib.pyplot as plt
import japanize_matplotlib
from fugashi import Tagger
# 調整可能な設定値
MODEL_NAME = 'tohoku-nlp/bert-base-japanese-v3'
TARGET_WORD = '手'
RESULT_FILE = 'result.txt'
HEATMAP_VMIN = 0.7
HEATMAP_VMAX = 1.0
FONT_SIZE_TITLE = 14
FIGURE_SIZE = (10, 8)
# テスト文章
SENTENCES_WITH_CONTEXT = [
{'text': '手を洗って清潔にする', 'context': '身体部位'},
{'text': '手にけがを負った', 'context': '身体部位'},
{'text': '問題解決の手を考える', 'context': '方法・手段'},
{'text': '良い手が見つからない', 'context': '方法・手段'}
]
SENTENCES = [item['text'] for item in SENTENCES_WITH_CONTEXT]
CONTEXTS = [item['context'] for item in SENTENCES_WITH_CONTEXT]
results = []
def print_and_save(text, results_list):
print(text)
results_list.append(text)
# ガイダンス表示
print('=== 日本語BERT文脈埋め込み分析プログラム ===')
print('概要: BERTを使用して多義語の文脈依存的な意味の違いを分析する')
print('操作方法: プログラムは自動実行される。表示されたグラフウィンドウを閉じると終了する')
print('注意事項: 初回実行時はモデルのダウンロードに時間を要する\n')
print_and_save('=== 分析開始 ===', results)
print_and_save('対象単語が異なる文脈でどのように異なる埋め込みベクトルを持つかを分析する\n', results)
# 形態素解析器
tagger = Tagger()
# 形態素としてTARGET_WORDが含まれるか確認(独立一致のみ)
def find_morph_targets(sentence, target):
tokens = list(tagger(sentence))
spans = []
pos = 0
for t in tokens:
start = pos
end = start + len(t.surface)
if t.surface == target:
spans.append((start, end, t.surface))
pos = end
return spans
word_found = any(len(find_morph_targets(s, TARGET_WORD)) > 0 for s in SENTENCES)
if not word_found:
print(f'エラー: 対象単語「{TARGET_WORD}」が形態素として文章に含まれていない')
print('プログラムを終了する')
sys.exit(1)
# モデルとトークナイザーの読み込み
try:
print('モデルをロード中...')
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModel.from_pretrained(MODEL_NAME)
print('モデルのロードが完了した')
except Exception as e:
print(f'モデルのダウンロードに失敗した: {MODEL_NAME}')
print(f'エラー: {e}')
sys.exit(1)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
model.eval()
print_and_save(f'使用デバイス: {device}', results)
print_and_save(f'使用モデル: {MODEL_NAME}', results)
print_and_save(f'トークナイザー: {tokenizer.__class__.__name__}', results)
print_and_save('\n=== 入力文章 ===', results)
for i, (sentence, context) in enumerate(zip(SENTENCES, CONTEXTS)):
print_and_save(f'文{i+1} ({context}): {sentence}', results)
# ヘルパ: WordPiece列から、指定表層と一致する連続範囲を探す([CLS]/[SEP]は除外)
SPECIAL_TOKENS = {'[CLS]', '[SEP]', '[PAD]', '[UNK]', '[MASK]'}
def strip_wp(tok):
return tok.replace('##', '')
def find_wp_span_for_surface(tokens, surface, start_idx):
n = len(tokens)
end_limit = n - 1 # [SEP]の直前まで
for j in range(start_idx, end_limit):
if tokens[j] in SPECIAL_TOKENS:
continue
concat = ''
k = j
while k < end_limit and tokens[k] not in SPECIAL_TOKENS and len(concat) <= len(surface):
concat += strip_wp(tokens[k])
if concat == surface:
return list(range(j, k + 1))
if len(concat) > len(surface):
break
k += 1
return None
# メイン処理
vectors = []
print_and_save('\n=== トークン化結果 ===', results)
for i, sentence in enumerate(SENTENCES):
# 形態素としての独立出現を列挙
morph_targets = find_morph_targets(sentence, TARGET_WORD)
# トークナイズ(長文対策としてtruncation=True)
inputs = tokenizer(sentence, return_tensors='pt', padding=True, truncation=True)
inputs = {k: v.to(device) for k, v in inputs.items()}
with torch.no_grad():
outputs = model(**inputs, output_hidden_states=True)
# 最終4層の平均を使用
last4 = outputs.hidden_states[-4:] # tuple of 4 tensors [B, T, H]
token_embeddings = torch.stack(last4, dim=0).mean(dim=0)[0] # [T, H]
tokens = tokenizer.convert_ids_to_tokens(inputs['input_ids'][0])
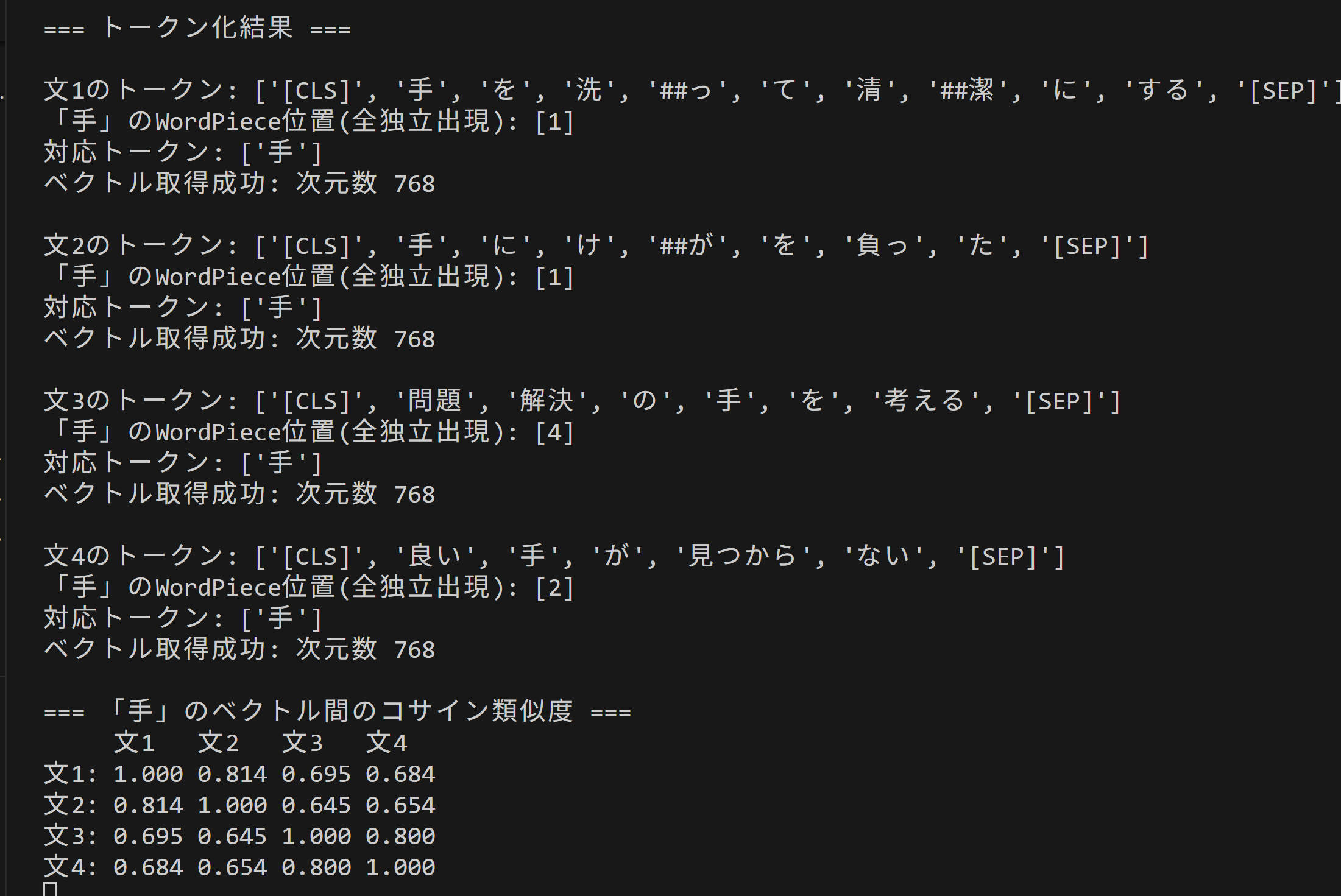
print_and_save(f'\n文{i+1}のトークン: {tokens}', results)
# 各独立出現に対応するWordPiece範囲を探索
wp_positions_all = []
cursor = 1 # [CLS]を飛ばす
for (_start, _end, surface) in morph_targets:
span = find_wp_span_for_surface(tokens, surface, cursor)
if span is None:
print_and_save(f'\nエラー: 文{i+1}で対象語「{surface}」のWordPiece範囲を同定できない', results)
print_and_save(f' 形態素出現: {surface}', results)
print_and_save(f' トークン列: {tokens}', results)
print_and_save('プログラムを終了する', results)
with open(RESULT_FILE, 'w', encoding='utf-8') as f:
f.write('\n'.join(results))
print(f'\nエラーログを{RESULT_FILE}に保存した')
sys.exit(1)
wp_positions_all.extend(span)
cursor = span[-1] + 1
if wp_positions_all:
print_and_save(f'「{TARGET_WORD}」のWordPiece位置(全独立出現): {wp_positions_all}', results)
print_and_save(f'対応トークン: {[tokens[p] for p in wp_positions_all]}', results)
vec = token_embeddings[wp_positions_all].mean(dim=0).cpu().numpy()
vectors.append(vec)
print_and_save(f'ベクトル取得成功: 次元数 {vec.shape[0]}', results)
else:
print_and_save(f'\nエラー: 文{i+1}で対象単語「{TARGET_WORD}」が見つからない', results)
print_and_save('プログラムを終了する', results)
with open(RESULT_FILE, 'w', encoding='utf-8') as f:
f.write('\n'.join(results))
print(f'\nエラーログを{RESULT_FILE}に保存した')
sys.exit(1)
# コサイン類似度の計算
similarity_matrix = cosine_similarity(vectors)
print_and_save(f'\n=== 「{TARGET_WORD}」のベクトル間のコサイン類似度 ===', results)
header = ' ' + ''.join([f'文{i+1} ' for i in range(len(SENTENCES))])
print_and_save(header, results)
for i in range(len(SENTENCES)):
row = f'文{i+1}: ' + ' '.join([f'{similarity_matrix[i,j]:.3f}' for j in range(len(SENTENCES))])
print_and_save(row, results)
# ヒートマップの作成
plt.figure(figsize=FIGURE_SIZE)
im = plt.imshow(similarity_matrix, cmap='coolwarm', vmin=HEATMAP_VMIN, vmax=HEATMAP_VMAX)
plt.colorbar(im)
plt.xticks(range(len(SENTENCES)), [f'文{i+1}' for i in range(len(SENTENCES))])
plt.yticks(range(len(SENTENCES)), [f'文{i+1}' for i in range(len(SENTENCES))])
plt.title(f'「{TARGET_WORD}」の文脈依存類似度 - BERT日本語モデル', fontsize=FONT_SIZE_TITLE)
for i in range(len(SENTENCES)):
for j in range(len(SENTENCES)):
plt.text(j, i, f'{similarity_matrix[i,j]:.3f}', ha='center', va='center', color='black')
plt.tight_layout()
plt.show()
# 分析結果
print_and_save('\n=== 分析結果 ===', results)
same_context_pairs = []
diff_context_pairs = []
for i in range(len(SENTENCES)):
for j in range(i+1, len(SENTENCES)):
if CONTEXTS[i] == CONTEXTS[j]:
same_context_pairs.append((i, j, similarity_matrix[i,j]))
else:
diff_context_pairs.append((i, j, similarity_matrix[i,j]))
# 同一文脈内の類似度
if same_context_pairs:
print_and_save('\n同一文脈内の類似度:', results)
same_vals = []
for i, j, sim in same_context_pairs:
print_and_save(f' 文{i+1}「{SENTENCES[i]}」と文{j+1}「{SENTENCES[j]}」: {sim:.3f}', results)
same_vals.append(sim)
avg_same_context = np.mean(same_vals)
std_same_context = np.std(same_vals) if len(same_vals) > 1 else 0
else:
avg_same_context = None
std_same_context = None
# 異文脈間の類似度
if diff_context_pairs:
print_and_save('\n異文脈間の類似度:', results)
diff_vals = []
for i, j, sim in diff_context_pairs:
print_and_save(f' 文{i+1}「{SENTENCES[i]}」と文{j+1}「{SENTENCES[j]}」: {sim:.3f}', results)
diff_vals.append(sim)
avg_diff_context = np.mean(diff_vals)
std_diff_context = np.std(diff_vals) if len(diff_vals) > 1 else 0
else:
avg_diff_context = None
std_diff_context = None
# 文脈識別評価
print_and_save('\n=== 文脈識別評価 ===', results)
if avg_same_context is not None and avg_diff_context is not None:
print_and_save(f'同一文脈内平均類似度: {avg_same_context:.3f} (標準偏差: {std_same_context:.3f})', results)
print_and_save(f'異文脈間平均類似度: {avg_diff_context:.3f} (標準偏差: {std_diff_context:.3f})', results)
print_and_save(f'サンプル数: 同一文脈ペア={len(same_context_pairs)}, 異文脈ペア={len(diff_context_pairs)}', results)
discrimination = avg_same_context - avg_diff_context
print_and_save(f'文脈識別スコア: {discrimination:.3f}', results)
if discrimination > 0.1:
evaluation = '文脈依存性が明確'
elif discrimination > 0.05:
evaluation = '文脈依存性あり'
elif discrimination > 0:
evaluation = '文脈依存性が限定的'
else:
evaluation = '文脈依存性が検出されない'
print_and_save(f'評価: {evaluation}', results)
elif avg_same_context is not None:
print_and_save(f'同一文脈内平均類似度のみ計算可能: {avg_same_context:.3f}', results)
print_and_save('異文脈ペアが存在しないため、文脈識別評価は不可', results)
elif avg_diff_context is not None:
print_and_save(f'異文脈間平均類似度のみ計算可能: {avg_diff_context:.3f}', results)
print_and_save('同一文脈ペアが存在しないため、文脈識別評価は不可', results)
else:
print_and_save('文脈識別評価には同一文脈と異文脈の両方のペアが必要である', results)
# モデル情報
print_and_save('\n=== モデル情報 ===', results)
print_and_save(f'語彙サイズ: {tokenizer.vocab_size}', results)
print_and_save(f'埋め込み次元数: {vectors[0].shape[0]}', results)
print_and_save(f'最大シーケンス長: {model.config.max_position_embeddings}', results)
# 結果保存
with open(RESULT_FILE, 'w', encoding='utf-8') as f:
f.write('\n'.join(results))
print(f'\n分析結果を{RESULT_FILE}に保存した')
4. 使用方法
- 上記のプログラムを実行する
- 実行結果として、「手」という単語の文脈による意味の違いがコサイン類似度として数値化され、ヒートマップで視覚化される。コサイン類似度は-1から1の値を取り、1に近いほど2つのベクトルが似た方向を向いている(意味が近い)ことを示す。
5. 実験・探求のアイデア
実験要素
- 対象単語の変更:「目」(身体部位/目的)、「線」(物理的線/路線)など他の多義語で実験する。
- 文章数の増加:同じ意味で使われる文章を4つ用意し、クラスタリングの精度を観察する。
- 類似度閾値の探索:同一文脈と判定する閾値を実験的に決定する。
- AIモデル選択:プログラムコード内のコメントに記載されている各モデルの特徴を参考に、以下のモデルで同じ実験を行い、文脈識別能力を比較する。
- tohoku-nlp/bert-base-japanese-v2(旧版)
- tohoku-nlp/bert-large-japanese-v2(大規模版)
- tohoku-nlp/bert-base-japanese-char-v3(文字レベル版)
新発見を促す実験
- 慣用句での観察:「手を打つ」「手が回らない」での「手」のベクトルを観察し、物理的な手との関係を探る。
- 応用実験:取得したベクトルを使って文書分類器を作成し、文脈理解の実用性を体験する。
- 層別分析:BERTの各層(1層目、6層目、12層目)での埋め込みを比較し、文脈理解がどの層で形成されるか観察する。