6DRepNet頭部3次元姿勢推定
【概要】6DRepNetはリアルタイムで人間の頭部姿勢を推定するAI技術である。従来のEuler角表現と異なり、6次元回転表現を採用することで角度の曖昧性問題を解決し、推定を実現している。本ページでは、パソコンカメラを使用してリアルタイムに頭部の向きを検出し、ピッチ・ヨー・ロール角度を数値とグラフィカルな軸表示で確認できる。Windows環境での実行手順、プログラムコード、実験アイデアを含む。
実際にプログラムを動作させることで、AI技術が人間の動作を数値化する過程を体験し、頭部姿勢推定の精度や応答性を直接確認できる。顔の向きや表情の変化に対するAIの反応を観察することで、コンピュータビジョン技術の実用性と限界を理解する。
目次
事前準備
Python, Windsurfをインストールしていない場合の手順(インストール済みの場合は実行不要)。
- 管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー >
cmdと入力 > 右クリック > 「管理者として実行」)。 - 以下のコマンドをそれぞれ実行する(
wingetコマンドは1つずつ実行)。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent
REM Windsurf をシステム領域にインストール
winget install --scope machine --id Codeium.Windsurf -e --silent
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul
REM Windsurf のパス設定
set "WINDSURF_PATH=C:\Program Files\Windsurf"
if exist "%WINDSURF_PATH%" (
echo "%PATH%" | find /i "%WINDSURF_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%WINDSURF_PATH%" /M >nul
)Python パッケージのインストール
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する:
pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
pip install sixdrepnet numpy insightface pillow opencv-python
プログラムコード
# プログラム名: 6DRepNet頭部姿勢推定プログラム
# 特徴技術名: 6DRepNet(6次元回転表現による頭部姿勢推定)
# 出典: Hempel, T., & Abdelrahman, A. A. (2022). 6D Rotation Representation for Unconstrained Head Pose Estimation. In 2022 IEEE International Conference on Image Processing (ICIP) (pp. 2496-2500). IEEE.
# 特徴機能: 6次元回転表現による連続的な頭部姿勢推定。Euler角表現の不連続性・ジンバルロック問題を解決
# 学習済みモデル: 6DRepNet事前学習済みモデル(300W-LPデータセットで学習)。ライブラリ内で自動ダウンロード
# 方式設計:
# - 関連利用技術: InsightFace(顔検出)、OpenCV(画像処理・表示)、Pillow(日本語テキスト描画)
# - 入力と出力: 入力: 動画(0:ファイル選択、1:カメラ、2:サンプル動画)、出力: リアルタイム表示と結果ファイル保存
# - 処理手順: 1.顔検出、2.各顔領域抽出、3.姿勢推定、4.角度算出、5.結果表示
# - 前処理、後処理: 前処理:顔領域の抽出とパディング。後処理:角度の度数法変換、3D軸描画
# - 調整を必要とする設定値: DET_SIZE(顔検出解像度)、FACE_PADDING(顔領域パディング率)
# 前準備:
# pip install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
# pip install sixdrepnet numpy insightface pillow opencv-python
import cv2
import numpy as np
from sixdrepnet import SixDRepNet
from insightface.app import FaceAnalysis
import tkinter as tk
from tkinter import filedialog
import os
import time
import urllib.request
import sys
import io
import torch
from PIL import Image, ImageDraw, ImageFont
from datetime import datetime
# Windows標準出力エンコーディング設定
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8', line_buffering=True)
# 定数定義
CAMERA_WIDTH = 640
CAMERA_HEIGHT = 480
USE_FACE_DETECTION = True
DET_SIZE = (640, 640) # 顔検出解像度
FACE_PADDING = 0.2 # 顔領域のパディング率(0.2 = 20%拡張)
FONT_SCALE = 0.7
FONT_THICKNESS = 2
FONT_COLOR_POSE = (0, 255, 255)
FONT_COLOR_FACE = (255, 255, 0)
FONT_COLOR_TEXT = (255, 255, 255)
BBOX_COLOR = (0, 255, 0)
BBOX_THICKNESS = 2
FONT_PATH = 'C:/Windows/Fonts/meiryo.ttc'
FONT_SIZE = 16
# 3D軸の色分け(X軸:赤、Y軸:緑、Z軸:青)
AXIS_COLORS = [(0, 0, 255), (0, 255, 0), (255, 0, 0)] # 各軸の色
MAIN_FUNC_DESC = "6DRepNet頭部姿勢推定"
def print_guidance_startup():
# プログラム開始時のガイダンス
print('=== 6DRepNet頭部姿勢推定プログラム ===')
print('')
print('【概要説明】')
print('6次元回転表現を使用した頭部姿勢推定を行います')
print('複数の顔を同時に検出し、各顔の姿勢を個別に推定します')
print('')
print('【操作方法】')
print('- qキーまたはESCキー: プログラム終了')
print('- 画面に各顔の姿勢角度と3D軸が表示されます')
print('')
print('【注意事項】')
print('- 顔が検出されない場合は姿勢推定を行いません')
print('- 処理結果は自動的にresult.txtに保存されます')
print('')
def init_sixdrepnet(device):
# モデル初期化
print('6DRepNetモデルを初期化中...')
if device.type == 'cuda':
model = SixDRepNet()
print('6DRepNetモデルの初期化完了(GPU使用)')
else:
os.environ['CUDA_VISIBLE_DEVICES'] = '-1'
model = SixDRepNet(gpu_id=-1)
print('6DRepNetモデルの初期化完了(CPU使用)')
return model
def init_face_detector(device):
face_app = None
if USE_FACE_DETECTION:
print('InsightFace顔検出器を初期化中...')
face_app = FaceAnalysis(allowed_modules=['detection'])
if device.type == 'cuda':
face_app.prepare(ctx_id=0, det_size=DET_SIZE)
print('InsightFace顔検出器の初期化完了(GPU使用)')
else:
face_app.prepare(ctx_id=-1, det_size=DET_SIZE)
print('InsightFace顔検出器の初期化完了(CPU使用)')
return face_app
# 日本語フォント初期化
def draw_japanese_text(frame, text, position, font_color=(255, 255, 255)):
"""OpenCV画像に日本語テキストを描画"""
if not use_japanese_font:
cv2.putText(frame, text, position, cv2.FONT_HERSHEY_SIMPLEX,
FONT_SCALE, font_color, FONT_THICKNESS)
return frame
img_pil = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_pil)
# BGRからRGBへ正しく変換
draw.text(position, text, font=font, fill=(font_color[2], font_color[1], font_color[0]))
return cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
def format_result_line(choice, frame_count, result, current_time):
if choice == '1': # カメラの場合
return datetime.fromtimestamp(current_time).strftime("%Y-%m-%d %H:%M:%S.%f")[:-3] + ' ' + result
else: # 動画ファイルの場合
return f"{frame_count} {result}"
def video_frame_processing(frame):
global frame_count
current_time = time.time()
frame_count += 1
faces = []
if USE_FACE_DETECTION and face_app is not None:
faces = face_app.get(frame)
# 顔が検出されない場合
if len(faces) == 0:
frame = draw_japanese_text(frame, '顔が検出されていません', (10, 30), FONT_COLOR_TEXT)
result = '顔が検出されていません'
else:
# 各顔に対して姿勢推定を実行
face_results = []
frame_copy = frame.copy()
for i, face in enumerate(faces):
bbox = face.bbox.astype(int)
x1, y1, x2, y2 = bbox
# バウンディングボックスをパディング付きで拡張
width = x2 - x1
height = y2 - y1
# パディング量を計算
pad_x = int(width * FACE_PADDING)
pad_y = int(height * FACE_PADDING)
# 拡張後の座標(画像境界内に制限)
h, w = frame.shape[:2]
x1_exp = x1 - pad_x
y1_exp = y1 - pad_y
x2_exp = x2 + pad_x
y2_exp = y2 + pad_y
# 境界クリッピング処理
x1_exp = max(0, x1_exp)
y1_exp = max(0, y1_exp)
x2_exp = min(w, x2_exp)
y2_exp = min(h, y2_exp)
if x2_exp > x1_exp and y2_exp > y1_exp:
# 拡張された顔領域を切り出し
face_img = frame[y1_exp:y2_exp, x1_exp:x2_exp].copy()
# 6DRepNetで姿勢推定
pitch, yaw, roll = model.predict(face_img)
# 切り出した画像に軸を描画
face_img_with_axis = face_img.copy()
model.draw_axis(face_img_with_axis, yaw, pitch, roll)
# 元のフレームに軸付き画像を合成
frame_copy[y1_exp:y2_exp, x1_exp:x2_exp] = face_img_with_axis
# バウンディングボックスの描画(軸の後に描画)
cv2.rectangle(frame_copy, (x1, y1), (x2, y2), BBOX_COLOR, BBOX_THICKNESS)
# 姿勢情報を表示
text_y = y1 - 10 if y1 > 30 else y2 + 20
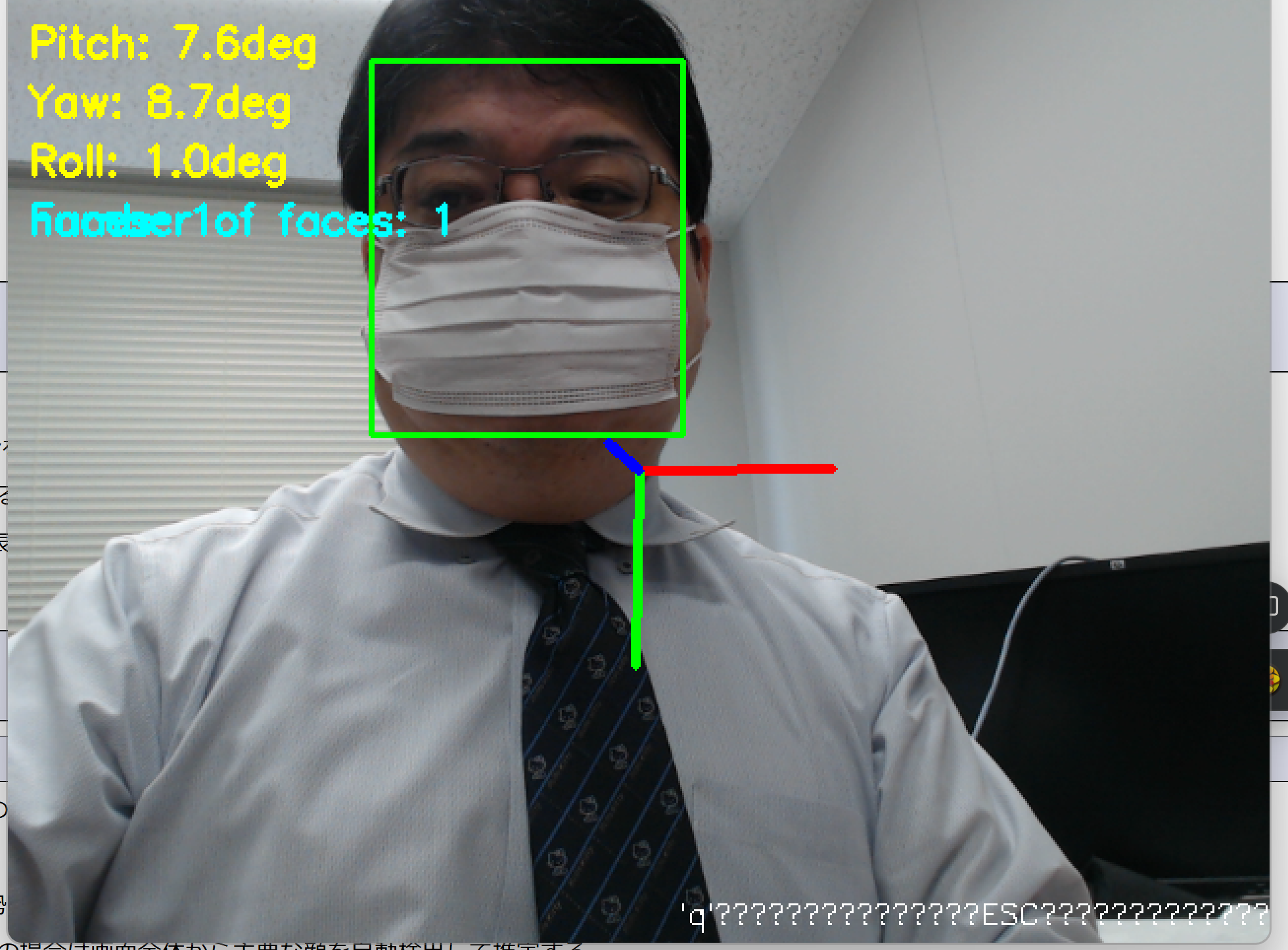
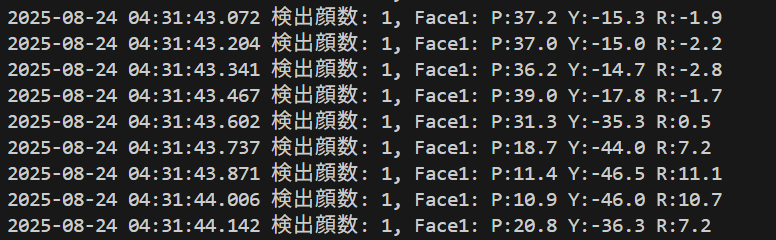
info_text = f'Face{i+1}: P:{float(pitch):.1f} Y:{float(yaw):.1f} R:{float(roll):.1f}'
frame_copy = draw_japanese_text(frame_copy, info_text, (x1, text_y), FONT_COLOR_POSE)
face_results.append({
'id': i+1,
'pitch': float(pitch),
'yaw': float(yaw),
'roll': float(roll)
})
# 統計情報の表示
frame_copy = draw_japanese_text(frame_copy, f'検出顔数: {len(faces)}', (10, 30), FONT_COLOR_FACE)
# 結果文字列の生成
result = f'検出顔数: {len(faces)}'
for face_result in face_results:
result += f", Face{face_result['id']}: P:{face_result['pitch']:.1f} Y:{face_result['yaw']:.1f} R:{face_result['roll']:.1f}"
frame = frame_copy
# 操作説明
frame = draw_japanese_text(frame, '終了: q または ESC',
(frame.shape[1] - 200, frame.shape[0] - 20),
FONT_COLOR_TEXT)
return frame, result, current_time
def print_guidance_runtime():
print('\n=== 動画処理開始 ===')
print('操作方法:')
print(' q キー: プログラム終了')
print_guidance_startup()
# GPU/CPU自動選択
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'デバイス: {str(device)}')
# GPU使用時の最適化
if device.type == 'cuda':
torch.backends.cudnn.benchmark = True
# モデル初期化(関数化後)
model = init_sixdrepnet(device)
# 顔検出器初期化(関数化後)
face_app = init_face_detector(device)
# 日本語フォント初期化
try:
font = ImageFont.truetype(FONT_PATH, FONT_SIZE)
use_japanese_font = True
except:
font = None
use_japanese_font = False
print('日本語フォントの読み込みに失敗しました。英語表示のみ行います')
# 結果記録用
frame_count = 0
results_log = []
print("0: 動画ファイル")
print("1: カメラ")
print("2: サンプル動画")
choice = input("選択: ")
if choice == '0':
root = tk.Tk()
root.withdraw()
path = filedialog.askopenfilename()
if not path:
exit()
cap = cv2.VideoCapture(path)
elif choice == '1':
cap = cv2.VideoCapture(0, cv2.CAP_DSHOW)
if not cap.isOpened():
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, CAMERA_WIDTH)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, CAMERA_HEIGHT)
else:
# サンプル動画ダウンロード・処理
SAMPLE_URL = 'https://raw.githubusercontent.com/opencv/opencv/master/samples/data/vtest.avi'
SAMPLE_FILE = 'vtest.avi'
urllib.request.urlretrieve(SAMPLE_URL, SAMPLE_FILE)
cap = cv2.VideoCapture(SAMPLE_FILE)
if not cap.isOpened():
print('動画ファイル・カメラを開けませんでした')
exit()
# メイン処理
print_guidance_runtime()
try:
while True:
ret, frame = cap.read()
if not ret:
break
processed_frame, result, current_time = video_frame_processing(frame)
cv2.imshow(MAIN_FUNC_DESC, processed_frame)
print(format_result_line(choice, frame_count, result, current_time))
results_log.append(result)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
finally:
print('\n=== プログラム終了 ===')
cap.release()
cv2.destroyAllWindows()
if results_log:
with open('result.txt', 'w', encoding='utf-8') as f:
f.write('=== 結果 ===\n')
f.write(f'処理フレーム数: {frame_count}\n')
f.write(f'使用デバイス: {str(device).upper()}\n')
if device.type == 'cuda':
f.write(f'GPU: {torch.cuda.get_device_name(0)}\n')
f.write('\n')
f.write('\n'.join(results_log))
print(f'\n処理結果をresult.txtに保存しました')
使用方法
- プログラムファイルを任意のフォルダに保存する
- コマンドプロンプトでそのフォルダに移動し、
python ファイル名.pyを実行する - カメラの映像が表示され、顔を検出すると頭部姿勢の推定が開始される
- 画面左上に角度情報、顔の位置に緑の矩形、頭部の向きに3次元軸が表示される
- 'q'キーまたはESCキーで終了する
実験・探求のアイデア
顔検出機能の比較
プログラム内のUSE_FACE_DETECTIONを変更することで、顔検出機能の有無を比較できる:
USE_FACE_DETECTION = True:InsightFaceによる顔検出ありUSE_FACE_DETECTION = False:顔検出なし、全画面から頭部姿勢を推定
顔検出ありの場合は検出された顔領域に対してのみ姿勢推定を行い、なしの場合は画面全体から主要な顔を自動検出して推定する。
カメラ解像度の調整
CAMERA_WIDTHとCAMERA_HEIGHTを変更することで、処理速度と精度のトレードオフを観察できる:
- 高解像度(1280×720):精度向上、処理速度低下
- 低解像度(320×240):処理速度向上、精度低下
基本体験
- 正面向きでの基準値確認:正面を向いた状態での各角度の基準値を確認する
- 極端な角度での限界確認:横顔や上下を向いた際の推定限界を観察する
- 複数人での同時検出:複数人が画面に映った際の検出精度を確認する
精度検証実験
- 角度測定実験:分度器を用いて実際の角度と推定値を比較し、誤差を測定する
- 距離による影響確認:カメラからの距離を変えて推定精度の変化を観察する
- 照明条件の影響:明るさや光の方向を変えて推定結果への影響を確認する
応用シナリオ検証
- 視線追跡シミュレーション:画面上の特定点を見つめた際の角度変化を記録する
- 表情変化の影響:笑顔や驚いた表情での推定精度の変化を観察する
- 髪型・眼鏡の影響:帽子や眼鏡着用時の推定結果変化を確認する
これらの実験を通じて、技術の実用性と限界を具体的に理解し、頭部姿勢推定技術の応用可能性を探索できる。