SAM2とCLIPによるセマンティックセグメンテーション Colab プログラムによる実験・研究スキルの基礎
【概要】
SAM2とCLIPを組み合わせたセマンティックセグメンテーションプログラムである。画像内のオブジェクトを自動検出し、30種類のカテゴリに分類して色分け表示する機能を持つ。Google Colab環境で動作し、カテゴリのカスタマイズや繰り返し実験が可能である。
Colabのページ(ソースコードと説明): https://colab.research.google.com/drive/1Vp21iHxOTOGZ9oPIOi_OEvY9wGUbvnpJ?usp=sharing

【目次】
プログラム利用ガイド
1. このプログラムの利用シーン
画像内の複数のオブジェクトを自動的に検出し、種類別に色分けして表示するためのツールである。物体検出、画像解析、データセット作成の前処理など、セマンティックセグメンテーションが必要な場面で使用できる。
2. 主な機能
- 自動オブジェクト検出:画像内の全オブジェクトをSAM2が自動的に検出し、境界線を抽出する。
- オブジェクト分類:CLIPが検出された各領域を30種類のカテゴリ(壁、建物、空、床、木、天井、道路、草、人、車、テーブル、椅子、扉、窓、植物、花、山、水、食べ物、動物、家具、乗り物、標識、街路、家、橋、服、本、電子機器、その他)に自動分類する。
- カテゴリ別可視化:同じカテゴリに分類されたオブジェクトを同じ色で表示し、画像内の構成要素を視覚的に理解できる。
- カテゴリのカスタマイズ:分類対象のカテゴリを自由に変更し、特定の用途に合わせた分類を実行できる。
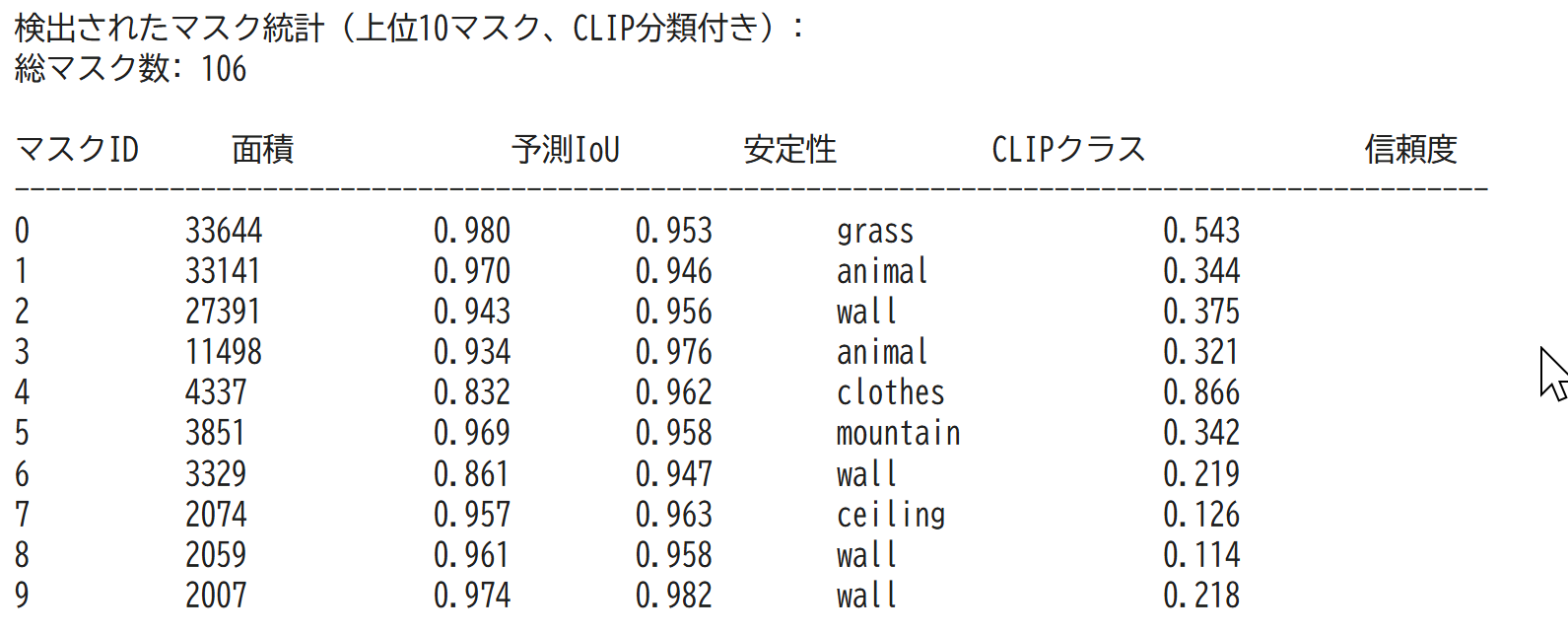
- 詳細統計表示:各マスクの面積、品質スコア、分類結果、信頼度を一覧表示する。
3. 基本的な使い方
- プログラムの起動:
Google Colabでセルを順番に実行する。最初のセルでライブラリのインストールが自動的に開始される(数分かかる)。
- サンプル画像の処理:
プログラムは起動後、自動的にサンプル画像をダウンロードし、セグメンテーションと分類を実行する。処理完了後、元画像とオーバーレイ画像が並べて表示される。
- ユーザー画像のアップロード:
ファイル選択ダイアログが表示されるので、処理したい画像ファイルを1つ選択してアップロードする。アップロード後、自動的に処理が開始される。
- 結果の確認:
画像表示の下に、検出されたマスクの統計情報(上位10マスク)とカテゴリ一覧が表示される。
4. 便利な機能
- カテゴリのカスタマイズ:処理完了後、分類カテゴリを変更して再実行できる。カンマ区切りで新しいカテゴリ名を入力する(例:人、犬、猫、車、建物)。空Enterでデフォルトの30カテゴリに戻る。
- 繰り返し処理:最後にアップロードまたは処理した画像に対して、カテゴリを変更しながら何度でも再実行できる。'q'または'quit'を入力すると終了する。
- 処理フローの説明表示:最初のサンプル画像処理時に、SAM2によるマスク生成とCLIPによる分類の詳細な処理フローが表示される。
- 画像の自動リサイズ:横幅が600ピクセルを超える画像は、自動的に縦横比を保って縮小され、処理時間が短縮される。
- 用語の説明表示:予測IoU、安定性スコア、CLIPクラス、信頼度といった専門用語の意味が、統計情報の前に表示される。
プログラムコードの説明
1. 概要
このプログラムは、画像内の全オブジェクトを自動的に検出し、各領域を30種類のカテゴリに分類するセマンティックセグメンテーションシステムである。SAM2による自動マスク生成とCLIPによるゼロショット分類を統合し、サンプル画像とユーザーアップロード画像の両方に対応する。
2. 主要技術
Segment Anything Model 2 (SAM2)
Meta AIが2024年に発表した画像・動画セグメンテーション用の基盤モデルである[1]。階層的Transformerエンコーダとストリーミングメモリ機構を組み合わせ、プロンプトベースの視覚セグメンテーションを実現する。本プログラムでは、グリッド状に配置された点から自動的にマスクを生成するAutomatic Mask Generation機能を使用している。
Contrastive Language-Image Pre-training (CLIP)
OpenAIが2021年に開発した、画像とテキストを共通の埋め込み空間にマッピングするマルチモーダル学習モデルである[2]。4億組の画像-テキストペアで事前学習され、自然言語による視覚概念の記述を可能にする。本プログラムでは、セグメンテーションされた領域の分類にゼロショット分類機能を活用している。
3. 技術的特徴
- 二段階処理パイプライン
SAM2による物体境界の検出と、CLIPによる意味的分類を分離し、各処理を独立して実行する。この設計により、セグメンテーション精度と分類精度を個別に最適化できる。
- グリッドベースマスク生成
画像上に20×20のグリッド(400点)を配置し、各点を起点としてマスク候補を生成する。予測IoUと安定性スコアによる品質フィルタリング(閾値0.8、0.92)により、低品質なマスクを除去する。
- ゼロショット分類機構
CLIPの画像エンコーダとテキストエンコーダを使用し、マスク領域と30種類のカテゴリ記述との類似度を計算する。最も類似度が高いカテゴリをそのマスクのクラスとして割り当てる。
- カテゴリ別色分け可視化
同一CLIPクラスに分類された複数のマスクに対して、固定色を割り当てる。この処理により、画像内の同種オブジェクトの分布を視覚的に把握できる。
- 適応的画像リサイズ
横幅600ピクセルを基準として、大きな画像を縦横比を保って縮小する。処理時間の短縮と、Google Colabの計算リソース制約への対応を両立する。
4. 実装の特色
Google Colab環境で動作する対話型プログラムであり、以下の機能を備える。
- サンプル画像による自動実行とユーザーアップロード画像の処理
- CLIP分類カテゴリのカスタマイズ機能(カンマ区切り入力による変更)
- 処理結果の統計情報表示(マスクID、面積、予測IoU、安定性スコア、CLIPクラス、信頼度)
- 検出マスクのカテゴリ一覧出力(面積降順)
- 最小マスク領域面積の設定(100ピクセル)による微小領域の除外
- 元画像とオーバーレイ画像の並列表示による結果比較
- 繰り返し実行ループによる複数パラメータ設定の試行
5. 参考文献
[1] Ravi, N., et al. (2024). SAM 2: Segment Anything in Images and Videos. arXiv:2408.00714. https://arxiv.org/abs/2408.00714
[2] Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., & Sutskever, I. (2021). Learning Transferable Visual Models from Natural Language Supervision. Proceedings of the 38th International Conference on Machine Learning (ICML), 139, 8748-8763. https://arxiv.org/abs/2103.00020
実験・研究スキルの基礎:Google Colabで学ぶセマンティックセグメンテーション実験
1. 実験・研究のスキル構成要素
実験や研究を行うには、以下の5つの構成要素を理解する必要がある。
1.1 実験用データ
このプログラムでは画像ファイルが実験用データである。
1.2 実験計画
何を明らかにするために実験を行うのかを定める。
計画例:
- カテゴリの種類が分類結果に与える影響を確認する
- カテゴリ数が分類精度に与える影響を確認する
- 特定のオブジェクト(人、車、建物など)を確実に分類するためのカテゴリ設定を見つける
- 画像の種類(屋外、屋内、自然、都市など)によって適切なカテゴリセットを探る
- 同一画像に対して異なるカテゴリセットで分類し、結果の違いを観察する
1.3 プログラム
実験を実施するためのツールである。このプログラムはMeta AIのSAM2モデルとOpenAIのCLIPモデルを使用している。
- プログラムの機能を理解して活用することが基本である
- 基本となるプログラムを出発点として、将来、様々な機能を自分で追加することができる
1.4 プログラムの機能
このプログラムはカテゴリリストによってセマンティックセグメンテーションの分類を制御する。
入力パラメータ:
- 分類カテゴリリスト:CLIPが使用する分類カテゴリの名称(カンマ区切りで指定)
- デフォルトカテゴリ:30種類(壁、建物、空、床、木、天井、道路、草、人、車、テーブル、椅子、扉、窓、植物、花、山、水、食べ物、動物、家具、乗り物、標識、街路、家、橋、服、本、電子機器、その他)
出力情報:
- 元画像(左側)とオーバーレイ画像(右側)の並列表示
- 同じカテゴリに分類されたマスクは同じ色で表示される
- 検出されたマスクの統計情報(面積、予測IoU、安定性スコア、CLIPクラス、信頼度)
- 検出マスクのカテゴリ一覧(面積降順)
処理の流れ:
- SAM2が画像内の全オブジェクトを自動検出してマスクを生成する(数分かかる)
- CLIPが各マスクを指定されたカテゴリリストから最も類似度が高いカテゴリに分類する
- カテゴリを変更すると同じマスクに対して再分類が実行される
1.5 検証(結果の確認と考察)
プログラムの実行結果を観察し、カテゴリ設定の影響を考察する。
基本認識:
- カテゴリを変えると分類結果が変わる。その変化を観察することが実験である
- 「良い結果」「悪い結果」は目的によって異なる
観察のポイント:
- 各カテゴリに分類されたマスク数はどう変化するか
- 誤分類(明らかに違うカテゴリへの分類)は発生しているか
- CLIPの信頼度スコアは妥当か(低い信頼度は分類の不確実性を示す)
- カテゴリ数を増やすと分類精度は向上するか、それとも混乱するか
- 類似したカテゴリ(例:車と乗り物)を同時に含めると結果はどうなるか
2. 間違いの原因と対処方法
2.1 プログラムのミス(人為的エラー)
プログラムがエラーで停止する
- 原因:構文エラー、必要なライブラリがインストールされていない
- 対処方法:エラーメッセージを確認し、提供されたコードと比較する
モデルのダウンロードに時間がかかる
- 原因:初回実行時にSAM2モデル(約900MB)とCLIPモデルをダウンロードしている
- 対処方法:これは正常な動作である。ダウンロードが完了するまで待つ
画像処理に非常に時間がかかる
- 原因:SAM2のマスク生成処理は計算量が多い(数分かかる)
- 対処方法:これは正常な動作である。処理完了を待つ。横幅600ピクセルを超える画像は自動的に縮小される
画像がアップロードできない
- 原因:ファイル選択ダイアログでファイルが選択されていない、またはファイル形式が対応していない
- 対処方法:PNG、JPG、JPEG形式の画像ファイルを選択する
2.2 期待と異なる結果が出る場合
カテゴリを変更しても分類結果が変わらない
- 原因:新しいカテゴリが元のカテゴリと意味的に類似している、または入力が正しく認識されていない
- 対処方法:全く異なるカテゴリセット(例:動物名のみ)で試す。カンマ区切りが正しいか確認する
明らかに間違ったカテゴリに分類される
- 原因:カテゴリリストに適切な選択肢がない、または視覚的特徴が類似している
- 対処方法:より具体的なカテゴリを追加する。信頼度スコアを確認し、低い場合は分類が不確実であることを示している。これは正常な動作であり、CLIPのゼロショット分類の限界を理解する機会である
同じオブジェクトが複数のマスクに分割される
- 原因:SAM2が一つのオブジェクトを複数の領域として検出している
- 対処方法:これはSAM2の動作特性である。複数のマスクが同じカテゴリに分類されていれば、色分け表示で同一オブジェクトとして認識できる
カテゴリ数が多すぎると処理が遅くなる
- 原因:CLIPは各マスクに対して全カテゴリとの類似度を計算する
- 対処方法:カテゴリ数は目的に応じて必要最小限に絞る。実験では5~15個程度が適切である
カテゴリ一覧に同じ単語が何度も出現する
- 原因:多数のマスクが同じカテゴリに分類されている
- 対処方法:これは正常な動作である。画像内に同種のオブジェクトが多い場合に発生する。カテゴリの多様性を増やすと分類が分散される
3. 実験レポートのサンプル
カテゴリ設定が分類結果に与える影響の分析
実験目的:
屋外風景画像において、カテゴリの種類と数が分類結果にどのような影響を与えるかを明らかにする。
実験計画:
同一の画像に対して、異なる3種類のカテゴリセットで分類を実行し、結果を比較する。
実験方法:
プログラムを実行し、以下の3つのカテゴリセットで分類を実施する。
- セットA(広範囲・30カテゴリ):デフォルトの30カテゴリ
- セットB(中範囲・10カテゴリ):建物、空、木、道路、草、人、車、山、水、その他
- セットC(狭範囲・5カテゴリ):自然物、人工物、人、乗り物、その他
実験結果:
| カテゴリセット | カテゴリ数 | 検出マスク総数 | 最多カテゴリ | 平均信頼度 | 信頼度0.5未満の割合 |
|---|---|---|---|---|---|
| セットA(広範囲) | 30 | xx | xxxx | x.xx | xx% |
| セットB(中範囲) | 10 | xx | xxxx | x.xx | xx% |
| セットC(狭範囲) | 5 | xx | xxxx | x.xx | xx% |
考察:
- (例文)xxxxでは多様な分類が可能だったが、平均信頼度がxxと比較的低く、類似カテゴリ間での分類の不確実性が見られた
- (例文)xxxxでは平均信頼度がxxに向上し、画像の主要な構成要素を適切に分類できた。カテゴリ数と精度のバランスが良好であった
- (例文)xxxxでは信頼度が最も高かったが、分類が粗すぎて詳細な構成要素の識別ができなかった。「その他」カテゴリへの分類が全体のxx%を占めた
- (例文)カテゴリ数を減らすほど信頼度は向上するが、分類の詳細度が低下するというトレードオフの関係が確認できた
- (例文)画像内に存在しないカテゴリ(例:動物、食べ物)を含めても分類結果に悪影響はなく、CLIPは適切に他のカテゴリを選択していた
結論:
(例文)本実験の屋外風景画像においては、xxxxが最もバランスの取れた設定であった。分類の詳細度を重視する場合はxxxカテゴリ程度が適切であり、大まかな構成把握が目的の場合はxxxカテゴリで十分である。実験を通じて、カテゴリ設定が分類結果に大きく影響することが確認でき、目的に応じた適切なカテゴリ選択の重要性を理解できた。