BERTによる日本語文の類似度分析:Colab プログラムによる実験・研究スキルの基礎
【概要】本記事では、Google Colabで動作する文の意味的類似性分析プログラムについて解説する。BERTモデルを用いた文埋め込みベクトル生成、類似度計算、クラスタリングの手法を学び、実験・研究の基礎スキルを習得できる。
Colabのページ(ソースコードと説明): https://colab.research.google.com/drive/1Ba6PW6bHgnboGGN2FDHrW40BBRFeIyo1?usp=sharing




【目次】
プログラム利用ガイド
1. このプログラムの利用シーン
複数の文章の意味的な類似性を分析してグループ化したい場合に使用する。アンケートの自由記述回答の分類、文書の主題分析、類似文の検出などに活用できる。Google Colabで動作するため、ブラウザのみで実行可能である。
2. 主な機能
- 文の埋め込みベクトル生成:各文を768次元のベクトルに変換する。
- 類似度行列の計算と表示:すべての文ペア間の類似度を計算し、数値とヒートマップで表示する。
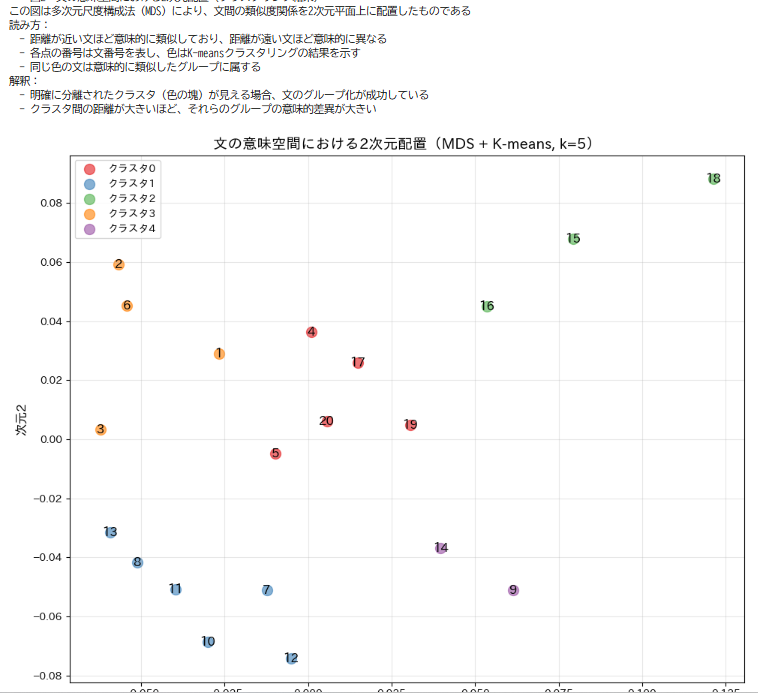
- 2次元可視化:文間の類似関係を2次元平面上に配置し、散布図で表示する。
- 自動クラスタリング:K-means法により文を自動的にグループ化し、最適なクラスタ数を決定する。
- クラスタ順ヒートマップ:クラスタリング結果に基づいて並び替えたヒートマップを表示する。
- 結果の保存:分析結果をテキストファイル(result.txt)に保存する。
3. 基本的な使い方
- Colabのページを開き,コードセルを実行
- 入力方法の選択:
プログラム実行後、0(サンプルテキスト)、1(ファイルアップロード)、2(前回結果の再利用)、3(終了)のいずれかを入力する。
- ファイルアップロード(選択肢1の場合):
改行で区切られた文章を含むテキストファイル(UTF-8形式)を選択する。
- 結果の確認:
プログラムを実行すると、以下の3つの図が順番に表示される。
- 図1:文番号順の類似度ヒートマップ
- 図2:2次元配置とクラスタリング結果
- 図3:クラスタ順に並び替えたヒートマップ
- 統計情報の確認:
平均類似度、標準偏差、最適クラスタ数、シルエット係数が表示される。
4. 便利な機能
- クラスタ数の調整:分析後、選択肢2を選ぶことで前回の結果のクラスタ数を1つ増やして再表示できる。異なるグループ数での分類を試すことができる。
- サンプルテキストの利用:動作確認のため、「手」という単語の3つの意味(身体部位、方法・手段、動作・運動)に関する20個のサンプル文が用意されている。
- 結果ファイルの保存:分析結果は自動的にresult.txtに保存される。入力文、類似度、統計情報、クラスタ別文一覧が記録される。
- 大量文への対応:50文を超える場合、ヒートマップ上の数値表示を自動的に省略し、視認性を維持する。
プログラムコードの説明
1. 概要
このプログラムは、日本語BERTモデルを使用して文の意味表現を分析するツールである。各文を768次元の埋め込みベクトルに変換し、文間の意味的類似度を計算して可視化する。文のグループ化をクラスタリングで行い、結果をヒートマップと2次元散布図で表示する。
2. 主要技術
BERT (Bidirectional Encoder Representations from Transformers)
Devlinらが2019年に発表した双方向トランスフォーマーによる言語表現モデルである[1]。文脈を考慮した単語・文の埋め込みベクトルを生成する。本プログラムでは東北大学が開発したbert-base-japanese-v3モデルを使用する。
多次元尺度構成法(MDS)
高次元データ間の距離関係を保持しながら低次元空間に配置する手法である[2]。本プログラムでは文間の類似度を2次元平面上の距離として可視化する。
3. 技術的特徴
- [CLS]トークンによる文埋め込み
BERTの文頭に配置される[CLS]トークンの埋め込みベクトルを文全体の表現として使用する。最終4層の[CLS]トークン埋め込みを平均することで、深い層の抽象的な意味表現を取得する。
- コサイン類似度による文間比較
埋め込みベクトル間の角度の余弦値を計算し、-1から1の範囲で類似度を定量化する。値が1に近いほど意味的に類似する。
- シルエット係数による最適クラスタ数決定
クラスタの凝集度と分離度を評価する指標[3]を用いて、2から10の範囲で自動的に最適なクラスタ数を選択する。
- Unicode正規化による前処理
NFKC正規化により全角・半角の統一と連続空白の圧縮を行い、トークン化の安定性を向上させる。
4. 実装の特色
Google Colab環境での実行を前提とし、以下の機能を備える。
- 3種類の入力方法:サンプルテキスト、ファイルアップロード、前回結果の再利用
- 3種類のヒートマップ:文番号順、クラスタ順、クラスタ数変更後
- 対話的なクラスタ数調整:前回の結果を保持し、クラスタ数を増やして再表示可能
- 結果のテキストファイル保存機能
5. 参考文献
[1] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of NAACL-HLT 2019 (pp. 4171-4186). https://aclanthology.org/N19-1423/
[2] Borg, I., & Groenen, P. J. F. (2005). Modern Multidimensional Scaling: Theory and Applications (2nd ed.). Springer.
[3] Rousseeuw, P. J. (1987). Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. Journal of Computational and Applied Mathematics, 20, 53-65. https://doi.org/10.1016/0377-0427(87)90125-7
実験・研究スキルの基礎:Google Colabで学ぶ文埋め込み分析実験
1. 実験・研究のスキル構成要素
実験や研究を行うには、以下の5つの構成要素を理解する必要がある。
1.1 実験用データ
このプログラムでは日本語の文章が実験用データである。各文は1行ずつ記載され、改行で区切られたテキストファイルとして準備する。
1.2 実験計画
何を明らかにするために実験を行うのかを定める。
計画例:
- 多義語を含む文のグループ化が意味ごとに正しく行われるかを確認する
- 類似した意味を持つ文が近い位置に配置されるかを確認する
- 文の長さや構造の違いが類似度に与える影響を調べる
- 同じ主題の文が同じクラスタに分類されるかを検証する
- 最適なクラスタ数が実際の意味グループ数と一致するかを確認する
1.3 プログラム
実験を実施するためのツールである。このプログラムはTransformersのBERTモデル、scikit-learnのMDSとK-meansを使用している。
- プログラムの機能を理解して活用することが基本である
- 基本となるプログラムを出発点として、将来、様々な機能を自分で追加することができる
1.4 プログラムの機能
このプログラムは文の埋め込みベクトルを生成し、文間の類似度を分析する。
入力データ:
- サンプルテキスト:プログラム内に用意された20個の文(「手」の多義性を示す例文)
- アップロードファイル:改行で区切られた日本語文を含むテキストファイル(UTF-8形式)
出力情報:
- 図1:文番号順の類似度ヒートマップ(すべての文ペアの類似度を色で表現)
- 図2:2次元散布図とクラスタリング結果(文の意味空間での配置)
- 図3:クラスタ順に並び替えたヒートマップ(同じクラスタの文を隣接配置)
- 統計情報:平均類似度、標準偏差、最適クラスタ数、シルエット係数
- クラスタ別文一覧:各文がどのクラスタに分類されたかのリスト
分析の流れ:
- 各文を768次元の埋め込みベクトルに変換する
- すべての文ペア間でコサイン類似度を計算する
- MDSにより2次元平面上に文を配置する
- K-meansクラスタリングで文をグループ化する
- シルエット係数により最適なクラスタ数を自動決定する
1.5 検証(結果の確認と考察)
プログラムの実行結果を観察し、文の意味的関係を考察する。
基本認識:
- 入力文を変えると結果が変わる。その変化を観察することが実験である
- 「良い結果」「悪い結果」は実験目的によって異なる
観察のポイント:
- 意味的に類似する文ペアの類似度は高いか(0.8以上など)
- 意味的に異なる文ペアの類似度は低いか(0.7以下など)
- 2次元散布図で意味的に近い文が近くに配置されているか
- クラスタリング結果が人間の直感的な分類と一致しているか
- 最適クラスタ数が実際の意味グループ数と対応しているか
- シルエット係数の値は十分に高いか(1に近いほど良好)
2. 間違いの原因と対処方法
2.1 プログラムのミス(人為的エラー)
プログラムがエラーで停止する
- 原因:必要なライブラリがインストールされていない、モデルのダウンロードに失敗した
- 対処方法:セルを最初から順番に実行する。エラーメッセージを確認し、インストールコマンドが正しく実行されたかを確認する
モデルのダウンロードに時間がかかる
- 原因:初回実行時にBERTモデル(約400MB)をダウンロードしている
- 対処方法:これは正常な動作である。ダウンロードが完了するまで待つ。2回目以降は高速に実行される
日本語が文字化けする
- 原因:japanize_matplotlibがインストールされていない、またはファイルのエンコーディングがUTF-8でない
- 対処方法:インストールセルを再実行する。テキストファイルはUTF-8形式で保存する
2.2 期待と異なる結果が出る場合
すべての文の類似度が非常に高い(0.9以上)
- 原因:入力した文が非常に似ている、または同じ単語を多く含んでいる
- 対処方法:これは正常な動作である。より多様な文を入力して実験する。意味的に異なる文を混ぜることで違いが観察できる
意味的に似ている文の類似度が低い
- 原因:表現方法が大きく異なる、または文の長さに差がある
- 対処方法:これはBERTモデルの特性である。類似度が低くても2次元散布図では近くに配置される場合がある。両方の結果を総合的に判断する
クラスタ数が期待より少ない
- 原因:シルエット係数により最適値として選ばれた、または文間の類似度が全体的に高い
- 対処方法:これは自動最適化の結果である。選択肢2でクラスタ数を増やして再表示できる。異なるクラスタ数での分類を比較する
クラスタリング結果が直感と異なる
- 原因:BERTは文脈や文法構造を考慮するため、単語の一致だけでは判断しない
- 対処方法:これは正常な動作である。ヒートマップで類似度の実際の値を確認する。どのような特徴でグループ化されたかを考察する機会である
文の数が多すぎて図が見づらい
- 原因:50文を超えるとヒートマップの数値表示が省略される
- 対処方法:これは仕様である。まず少数の文(10~30文程度)で実験し、理解を深めてから文を増やす
3. 実験レポートのサンプル
多義語を含む文の自動分類
実験目的:
「手」という単語の異なる意味(身体部位、方法・手段、動作・運動)を含む文が、BERTモデルにより意味ごとに正しく分類されるかを検証する。
実験計画:
各意味カテゴリから5~7文ずつ、合計20文を用意し、クラスタリング結果が意味カテゴリと一致するかを確認する。
実験方法:
プログラムのサンプルテキスト(20文)を使用し、以下の基準で評価する:
- クラスタ数:自動決定された最適クラスタ数が3(意味カテゴリ数)と一致するか
- 分類精度:各クラスタに含まれる文が同じ意味カテゴリに属するか
- 類似度パターン:同じ意味カテゴリ内の文ペアの類似度が高いか
実験結果:
| クラスタ番号 | 文の数 | 含まれる意味カテゴリの内訳 | 備考 |
|---|---|---|---|
| (例文)クラスタ0 | (例文)x文 | (例文)身体部位x文、動作・運動x文、方法・手段x文 | (例文)3つのカテゴリが混在 |
| (例文)クラスタ1 | (例文)x文 | (例文)方法・手段x文、身体部位x文 | (例文)方法・手段がやや多い |
| (例文)クラスタ2 | (例文)x文 | (例文)動作・運動x文、方法・手段x文、身体部位x文 | (例文)動作・運動がやや多いが混在 |
統計情報:
- 最適クラスタ数:xxxx
- シルエット係数:xxxx(低~中程度の値)
- 平均類似度:xxxx(高めの類似度)
考察:
- (例文)最適クラスタ数は自動的にxxxxと決定されたが、各クラスタには複数の意味カテゴリが混在し、意味による明確な分類は実現されなかった。
- (例文)すべてのクラスタにおいて複数の意味カテゴリが混在した。特にクラスタ0では3つのカテゴリすべてが含まれており、意味による分離が困難であることが示された。これは、「手」という単語を含む文が、意味の違いにかかわらず文脈的・構造的に類似している可能性を示唆している。
- (例文)方法・手段を表す文の一部は複数のクラスタに分散した。「良い手が見つからない」と「次の手を打つ」のように同じ意味カテゴリに属する文でも、文の構造や動詞の違いによって異なるクラスタに分類されたケースが観察された。
- (例文)図3のクラスタ順ヒートマップでは、対角線に沿ったブロック構造は不明瞭であり、クラスタ内外で類似度に大きな差が見られなかった。これは、全体的に文間の類似度が高く、クラスタ間の境界が曖昧であることを示している。
- (例文)シルエット係数が低~中程度の値にとどまったことから、形成されたクラスタの品質が十分ではなく、クラスタ内の凝集度もクラスタ間の分離度も明確ではないことが確認された。
- (例文)平均類似度が高めの値を示したことは、サンプル文全体が互いに類似しており、意味の違いよりも「手」という共通の単語を含むことの影響が大きいことを示唆している。
結論:
(例文)本実験では、BERTモデルによる多義語「手」を含む文の自動分類を試みたが、意味カテゴリに基づく明確な分類には至らなかった。すべてのクラスタで複数の意味カテゴリが混在し、シルエット係数も低~中程度にとどまった。BERTの文埋め込みだけでは多義語の細かい意味の違いを捉えることが困難であることが明らかになった。実用的には、自動分類の結果を参考にしつつ、別の技術の利用や、最終的には人間が内容を確認して分類する必要がある。